
Overview
Claude Fable 5 is Anthropic's most capable widely released model and the first member of its Mythos class — a capability tier above the Opus line — that the company made generally available. It launched on June 9, 2026 (API id claude-fable-5) on the Claude API, Claude Platform on AWS, Amazon Bedrock, Vertex AI, and Microsoft Foundry, built for the most demanding reasoning and long-horizon agentic work.
Claude Fable 5 shares the same underlying model as the restricted Claude Mythos 5, but ships with safety classifiers that can decline requests in high-risk areas (cybersecurity, biology and chemistry, and model-distillation attempts); refused requests instead route to Claude Opus 4.8. Anthropic reports that more than 95% of Fable 5 sessions involve no fallback at all. It carries a 1M-token context window and up to 128K output tokens, accepts text and image input, and runs adaptive thinking that is always on (extended thinking is not offered; the effort parameter controls thinking depth).
Three days after launch, on June 12, 2026, Anthropic suspended all access to Claude Fable 5 and Claude Mythos 5 to comply with a US government export-control directive — reportedly the first time the United States applied export controls to an AI model itself rather than the chips behind it. Anthropic publicly disagreed with the decision, which it tied to a narrow potential jailbreak, but disabled the models for all customers to remain compliant while working to restore access.
| Released | 2026-06-09 |
|---|---|
| License | Proprietary |
| Weights | API only |
| Parameters | Undisclosed |
| Context | 1M |
| Max output | 128K |
| Architecture | Undisclosed. Same underlying model as the restricted Claude Mythos 5; Fable 5 adds safety classifiers. Uses the tokenizer introduced with Claude Opus 4.7. |
| Modalities | Text, Vision |
| Status | Generally available June 9, 2026, then suspended June 12, 2026 under a US export-control directive |
Benchmarks
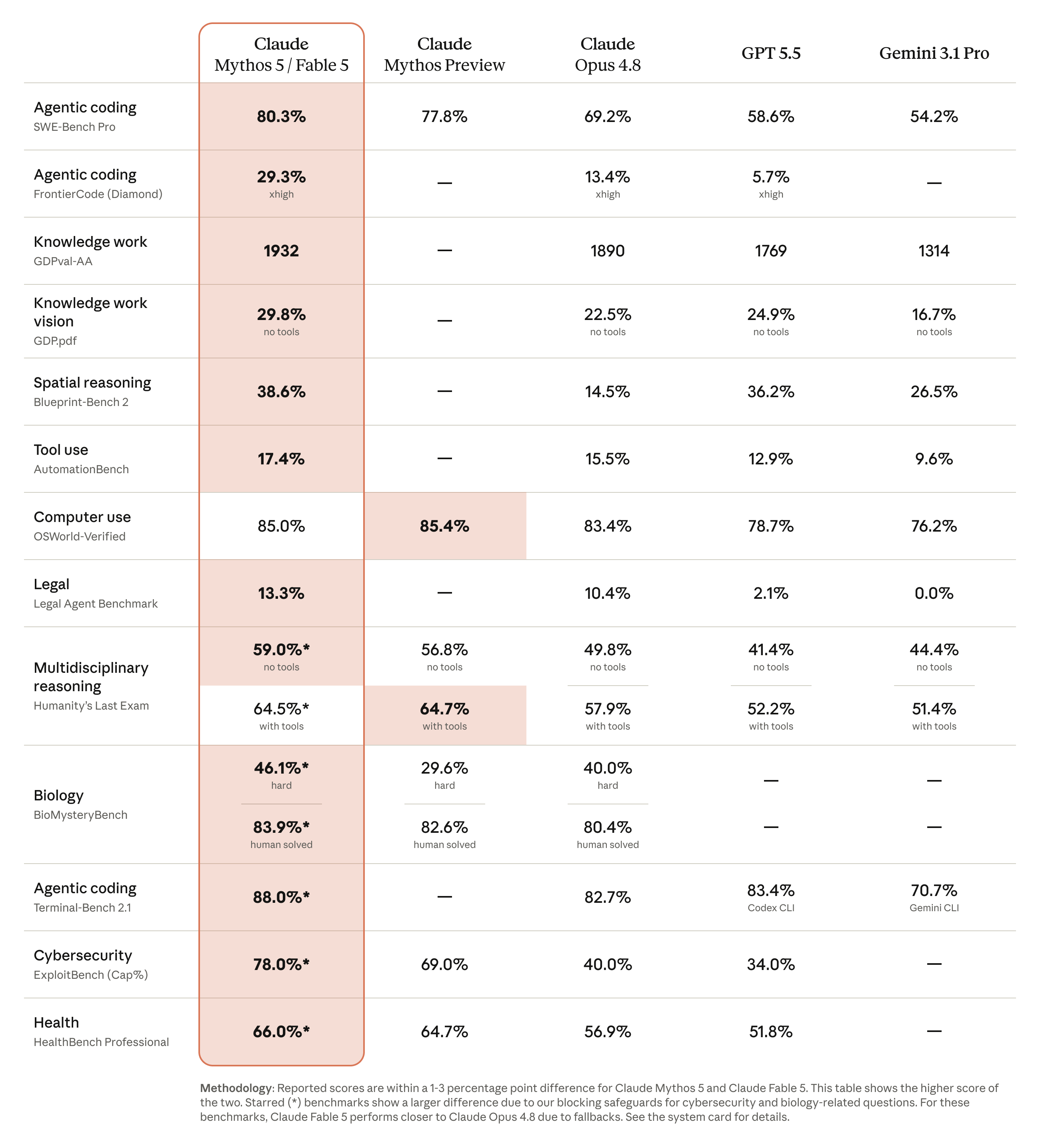
Claude Fable 5 / Mythos 5 benchmark comparison vs. Claude Opus 4.8, GPT 5.5, and Gemini 3.1 Pro (Anthropic launch table). The leading column covers both Claude Mythos 5 and Claude Fable 5 (shared scores). Starred values (*) for the Claude column reflect Anthropic's blocking safeguards on cybersecurity/biology-related questions; on those benchmarks Claude Fable 5 performs closer to Claude Opus 4.8 due to fallbacks.
| Benchmark | Claude Fable 5 | Claude Mythos Preview | Claude Opus 4.8 | GPT 5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|---|
| SWE-Bench-Pro (Agentic coding) | 80.3% | 77.8% | 69.2% | 58.6% | 54.2% |
| FrontierCode Diamond (Agentic coding, high effort) | 29.3% | — | 13.4% | 5.7% | — |
| GDPval-AA (Knowledge work) | 1932 Elo | — | 1890 Elo | 1769 Elo | 1314 Elo |
| GDPval (Knowledge work vision, no tools) | 29.8% | — | 22.5% | 24.9% | 16.7% |
| Blueprint Bench 2 (Spatial reasoning) | 38.6% | — | 14.5% | 36.2% | 26.5% |
| AutomationBench (Tool use) | 17.4% | — | 15.5% | 12.9% | 9.6% |
| OSWorld Verified (Computer use) | 85% | 85.4% | 83.4% | 78.7% | 76.2% |
| Legal Agent Benchmark (Legal) | 13.3% | — | 10.4% | 2.1% | 0% |
| Humanity's Last Exam (Multidisciplinary reasoning, no tools) | 59% | 56.6% | 49.8% | 41.4% | 44.4% |
| Humanity's Last Exam (with tools) | 64.5*% | 64.7% | 57.9% | 52.2% | 51.4% |
| BioMysteryBench (Biology, hard) | 46.1*% | 29.6% | 40% | — | — |
| BioMysteryBench (human solved) | 83.9*% | 82.6% | 80.4% | — | — |
| Terminal Bench 2.1 (Agentic coding) | 88.0*% | — | 82.7% | 83.4 (Codex CLI)% | 70.7 (Gemini CLI)% |
| ExploitBench Cap(%) (Cybersecurity) | 78.0*% | 69% | 40% | 34% | — |
| HealthBench Professional (Health) | 66.0*% | 64.7% | 56.9% | 51.8% | — |
This model's scores
Scores on a 0–100 scale (25-point gridlines); higher is better. Each benchmark links to its published source.
Pricing
| Input | $10.00 / 1M tokens |
|---|---|
| Cached input | $1.00 / 1M tokens |
| Output | $50.00 / 1M tokens |
5-minute cache write $12.50/MTok; 1-hour cache write $20/MTok; Batch API $5 input / $25 output per MTok. Same pricing for Mythos 5.
Strengths
- Frontier-level agentic coding — 95% on SWE-bench Verified and 80.3% on SWE-bench Pro, ahead of Claude Opus 4.8
- Strong computer use and terminal agents (85% OSWorld-Verified, 88% Terminal-Bench 2.1)
- 1M-token context window billed at standard per-token rates, with up to 128K output tokens
- Vision input strong enough to rebuild a web app's source from screenshots and read precise numbers from scientific figures
- Adaptive thinking always on, with an effort parameter to tune reasoning depth against cost
Best for
- Reach for it for the most demanding multi-step agentic coding across large codebases when you want above-Opus capability.
- Use it for long-horizon agent workflows (computer use, terminal automation) where reliability matters more than per-token cost.
- Apply it to deep reasoning and analysis over very long documents that fit a 1M-token context.
- Use it for vision-heavy work like reconstructing UIs from screenshots or extracting figures from scientific PDFs.
How to access
| Provider | Model ID |
|---|---|
| Anthropic API ↗ | claude-fable-5 |
| Amazon Bedrock ↗ | anthropic.claude-fable-5 |
| Google Cloud Vertex AI ↗ | claude-fable-5 |
Claude Fable / Mythos (Mythos-class) — every version
The full lineage of the Claude Fable / Mythos (Mythos-class) line, newest first. Every version has its own page — click any to compare specs, benchmarks and pricing.
| Version | Released | Context | License |
|---|---|---|---|
| Claude Fable 5current | 2026-06-09 | — | Proprietary |
| Claude Mythos 5 | 2026-06-09 | — | Proprietary |
| Claude Mythos Preview | 2026-04 | — | Proprietary |
FAQ
What is Claude Fable 5?
Claude Fable 5 is Anthropic's most capable widely released model and the first publicly available model in its Mythos class, a capability tier above the Opus line. It launched on June 9, 2026 with the API id claude-fable-5. It is the same underlying model as the restricted Claude Mythos 5, but adds safety classifiers that route sensitive requests to Claude Opus 4.8.
How much does Claude Fable 5 cost?
Claude Fable 5 costs $10 per million input tokens and $50 per million output tokens on the Anthropic API. Cache reads are $1 per million tokens, a 5-minute cache write is $12.50, and the Batch API halves prices to $5 input / $25 output per million tokens. Claude Mythos 5 carries the same pricing.
What are the context window and output limits of Claude Fable 5?
Claude Fable 5 has a 1M-token context window at standard pricing and can generate up to 128K output tokens per request. It accepts text and image input, and adaptive thinking is always on; the effort parameter controls thinking depth.
Why was Claude Fable 5 suspended?
On June 12, 2026, three days after launch, Anthropic suspended all access to Claude Fable 5 and Claude Mythos 5 to comply with a US government export-control directive — reportedly the first export control applied to an AI model rather than to chips. Anthropic publicly disagreed with the order, which it linked to a narrow potential jailbreak, but disabled the models for all customers while working to restore access.