
Overview
Command A+ is Cohere's flagship large language model, released on May 20, 2026 as the model ID command-a-plus-05-2026. It is the company's first Mixture-of-Experts model and the last entry in the Command A family, folding vision input, reasoning, translation, and agentic tool use into a single 218-billion-parameter network that activates only 25 billion parameters per token.
Notably, Command A+ is Cohere's first Command frontier model shipped under a full Apache 2.0 license with open weights. Cohere publishes near-lossless 16-bit (BF16), 8-bit (FP8), and 4-bit (W4A4) quantizations on the Hugging Face Hub, so the recommended W4A4 build runs on as few as two NVIDIA H100 GPUs or a single B200 — a footprint Cohere targets at sovereign, on-premise, and regulated enterprise deployments where data must stay inside trusted systems.
Beyond raw scores, Command A+ adds native citation grounding: when it pulls from an external tool or document it emits explicit grounding spans that tie each factual claim back to its source. It supports a 128K-token context window, up to 64K output tokens, and 48 languages (up from 23 in the original Command A), including every official EU language.
| Released | 2026-05-20 |
|---|---|
| License | Apache-2.0 |
| Weights | Open weights |
| Parameters | 218B total / 25B active (sparse MoE) |
| Context | 128K |
| Max output | 64K tokens |
| Architecture | Decoder-only sparse Mixture-of-Experts Transformer with 128 experts (8 active per token plus one shared expert) and interleaved sliding-window / global attention. Runs on as few as 2x NVIDIA H100 (W4A4) or 1x B200; FP8 needs 4x H100, BF16 needs 8x H100. |
| Modalities | Text, Vision |
| Status | Available |
Benchmarks
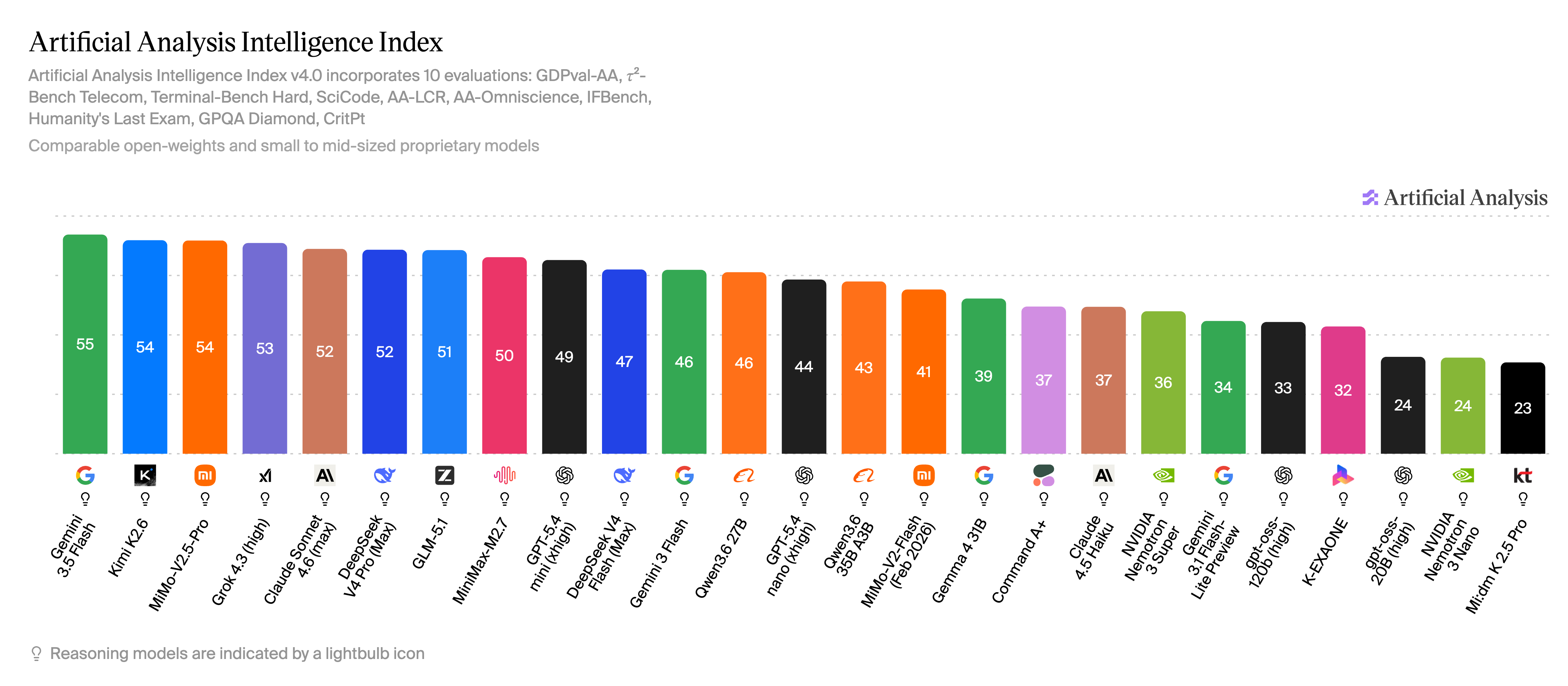
This model's scores
- τ²-Bench Telecom (agentic)85%
- Terminal-Bench Hard (agentic coding)25%
- MMMU (multimodal understanding)75.1%
- MMMU-Pro (visual reasoning)63%
- MathVista80.6%
- CharXiv (reasoning)52.7%
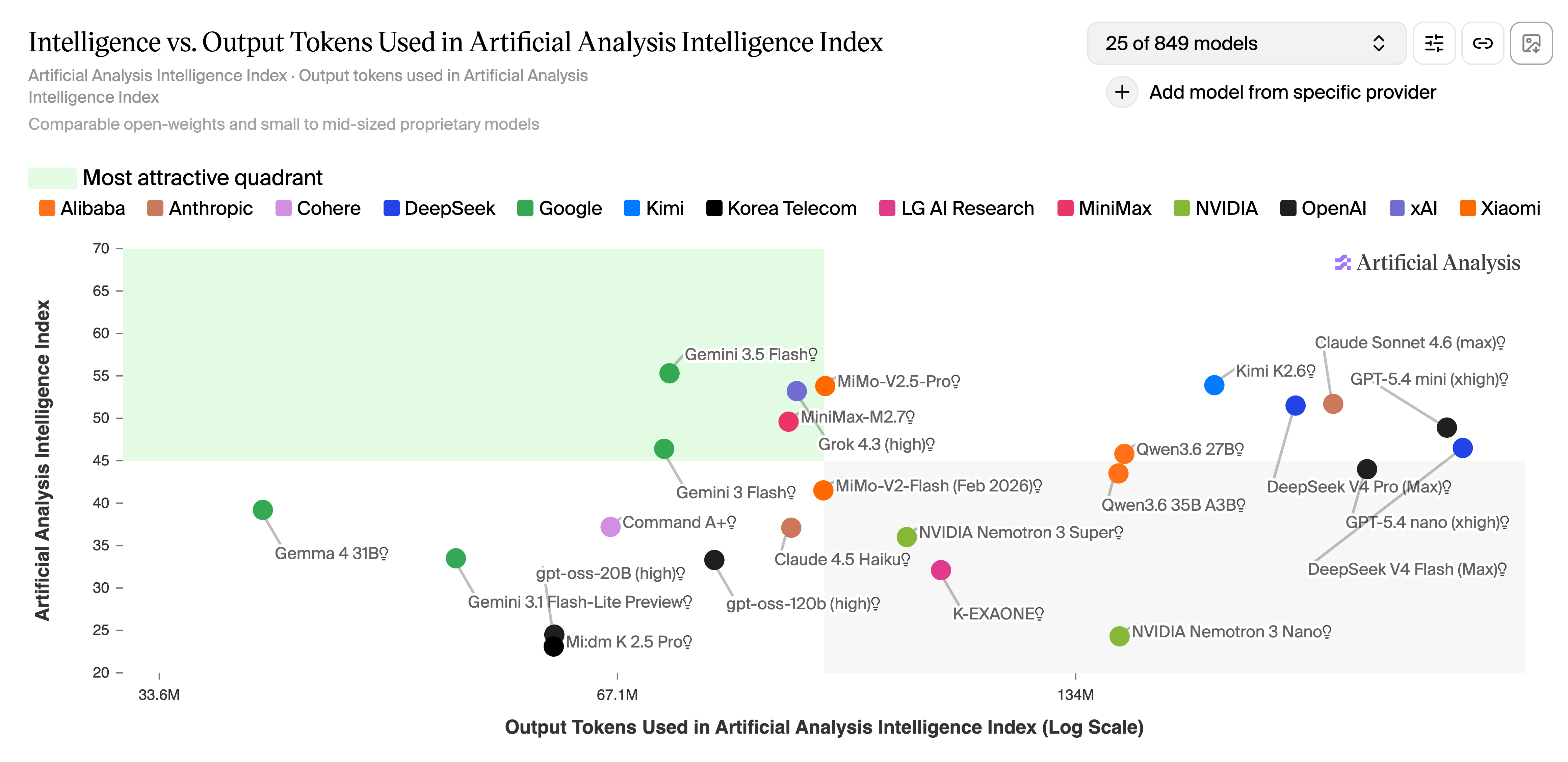
- Artificial Analysis Intelligence Index29%
Scores on a 0–100 scale (25-point gridlines); higher is better. Each benchmark links to its published source.
Strengths
- Open weights under a true Apache 2.0 license — commercial, government, and military use with no revenue caps or non-compete clauses
- Efficient sparse MoE: 25B active parameters keep inference fast while 218B total parameters back the quality
- Strongest agentic and tool-use model in the Command family, with large gains on multi-step enterprise task benchmarks
- Native citation grounding links every claim to its source document for verifiable RAG
- Small deployment footprint: near-lossless W4A4 quantization fits on 2x H100 or a single B200
- Broad multilingual coverage across 48 languages, including all official EU languages
Best for
- On-premise and sovereign enterprise agents that must keep sensitive data in-house
- Retrieval-augmented generation where every answer needs verifiable, cited sources
- Multi-step agentic workflows and tool use in customer support, operations, and analytics
- Multilingual document understanding and translation across 48 languages
- Multimodal document analysis combining text and image (vision) inputs
How to access
| Provider | Model ID |
|---|---|
| Cohere ↗ | command-a-plus-05-2026 |
FAQ
Is Command A+ open source?
Yes. Command A+ is released with open weights under a full Apache 2.0 license, allowing commercial, government, and military use with no revenue caps or non-compete clauses. Weights are published on the Hugging Face Hub under the CohereLabs organization in BF16, FP8, and W4A4 quantizations.
What hardware does Command A+ need to run?
The recommended near-lossless W4A4 (4-bit) build runs on as few as two NVIDIA H100 GPUs or a single B200. The FP8 build needs about four H100s and the full BF16 build needs about eight H100s.
How big is Command A+ and what context length does it support?
It is a sparse Mixture-of-Experts model with 218 billion total parameters and 25 billion active per token (128 experts, 8 active plus one shared). It supports a 128K-token context window and up to 64K output tokens.
What makes Command A+ good for enterprise agents?
It is the strongest agentic and tool-use model in the Command family, with large gains on multi-step task benchmarks like τ²-Bench Telecom (85%), plus native citation grounding that links every claim to its source — useful for verifiable RAG. Its small deployment footprint suits sovereign, on-premise use where data must stay in-house.