
Overview
MiniMax-M3 is an open-weight frontier model released June 1, 2026, billed by MiniMax as the first open-weight model to combine top-tier coding and agentic performance, a 1M-token context window, and native multimodality in a single architecture.
It is a sparse Mixture-of-Experts model with roughly 428B total parameters and about 23B activated per token, powered by MiniMax Sparse Attention (MSA). MSA cuts per-token compute at full context length and delivers large prefill and decode speedups versus M2 at 1M context. The model supports text, image, and video input and offers toggleable reasoning (thinking on/off) at identical pricing.
Weights are openly downloadable on Hugging Face under the MiniMax Community License. MiniMax reports strong agentic and coding results and aggressive pricing through its platform.
| Released | 2026-06-01 |
|---|---|
| License | MiniMax Community License |
| Weights | Open weights |
| Parameters | ~428B total / ~23B active |
| Context | 1M |
| Architecture | Sparse MoE with MiniMax Sparse Attention (MSA) |
| Modalities | Text, Vision, Video |
| Status | Available |
Benchmarks
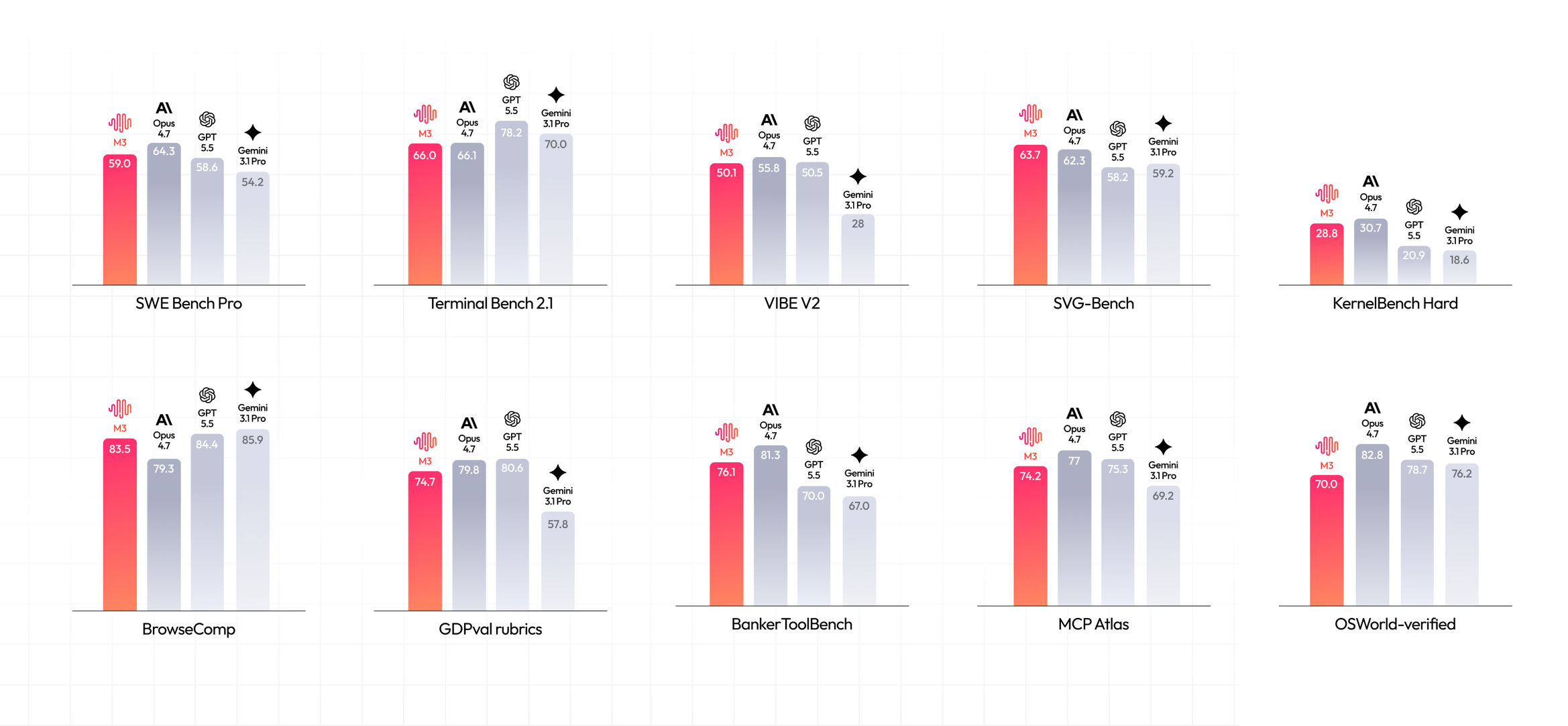
MiniMax M3 vs Claude Opus 4.7, GPT-5.5, and Gemini 3.1 Pro across ten benchmarks, as published in the headline comparison chart on the official MiniMax M3 blog post. Values are the numeric labels printed on each bar.
| Benchmark | MiniMax M3 | Claude Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE Bench Pro | 59% | 64.3% | 58.6% | 54.2% |
| Terminal Bench 2.1 | 66% | 66.1% | 78.2% | 70% |
| VIBE V2 | 50.1% | 55.8% | 50.5% | 28% |
| SVG-Bench | 63.7% | 62.3% | 58.2% | 59.2% |
| KernelBench Hard | 28.8% | 30.7% | 20.9% | 18.6% |
| BrowseComp | 83.5% | 79.3% | 84.4% | 85.9% |
| GDPval rubrics | 74.7% | 79.8% | 80.6% | 57.8% |
| BankerToolBench | 76.1% | 81.3% | 70% | 67% |
| MCP Atlas | 74.2% | 77% | 75.3% | 69.2% |
| OSWorld-verified | 70% | 82.8% | 78.7% | 76.2% |
This model's scores
- SWE-Bench Pro59%
- Terminal-Bench 2.166%
- MCP Atlas74.2%
- KernelBench Hard28.8%
- SWE-fficiency34.8%
Scores on a 0–100 scale (25-point gridlines); higher is better. Each benchmark links to its published source.
Pricing
| Input | $0.60 / 1M tokens |
|---|---|
| Output | $2.40 / 1M tokens |
Strengths
- 1 million token context window with efficient MiniMax Sparse Attention
- Open weights for self-hosting and customization
- Native multimodal input (text, image, video)
- Frontier-level coding and agentic benchmark scores
- Toggleable reasoning modes at the same price
Best for
- Long-horizon agentic coding and software engineering
- Ultra-long-document and full-repository understanding
- Multimodal applications across text, image, and video
- Self-hosted frontier-class deployments
How to access
| Provider | Model ID |
|---|---|
| MiniMax ↗ | MiniMax-M3 |
| OpenRouter ↗ | minimax/minimax-m3 |
MiniMax M-Series — every version
The full lineage of the MiniMax M-Series line, newest first. Every version has its own page — click any to compare specs, benchmarks and pricing.
| Version | Released | Context | License |
|---|---|---|---|
| MiniMax M3current | 2026-06-01 | 1M | MiniMax Community |
| MiniMax M2.7 / M2.7-highspeed | 2026-03-18 | — | Open weights |
| MiniMax M2.5 / M2.5-Lightning | 2026-02-12 | — | Open weights |
| MiniMax M2.1 | 2025-12-23 | — | Open weights |
| MiniMax M2 | 2025-10-27 | — | MIT |
FAQ
Is MiniMax-M3 open weights?
Yes. MiniMax released M3's weights openly on Hugging Face (MiniMaxAI/MiniMax-M3) under the MiniMax Community License, in Safetensors format. MiniMax describes it as the first open-weight model to combine frontier coding, a 1M-token context window, and native multimodality, enabling self-hosting and enterprise customization.
What is MiniMax Sparse Attention (MSA)?
MSA is the sparse attention operator behind MiniMax-M3, designed for million-token contexts. It reduces per-token compute at full context length to a fraction of the previous generation while preserving quality, yielding large prefill and decode speedups over M2 at 1M context and making long-context inference far cheaper.
How much does MiniMax-M3 cost?
Through MiniMax's platform, M3 is priced at $0.60 per 1M input tokens and $2.40 per 1M output tokens for prompts at or below 512K tokens, with a higher long-context rate above 512K. A launch promotion temporarily halved these to $0.30 input and $1.20 output.
What benchmarks does MiniMax-M3 report?
Per MiniMax's official blog, M3 scores 59.0% on SWE-Bench Pro, 66.0% on Terminal-Bench 2.1, 74.2% on MCP Atlas, 28.8% on KernelBench Hard, and 34.8% on SWE-fficiency. MiniMax positions these as frontier-level agentic and coding results at a fraction of comparable proprietary model costs.