
Overview
Mistral Small 4 is Mistral AI's March 2026 update to its Small line and the current flagship of that series. Released on 16 March 2026 under the permissive Apache 2.0 license, it is the first Mistral model to fold the company's separate specialist families into one set of weights: instruct-style chat, the reasoning behaviour previously shipped as Magistral, the vision understanding of Pixtral, and the agentic coding of Devstral. Instead of switching models, you switch a single reasoning_effort flag.
Under the hood, Mistral Small 4 is a Mixture-of-Experts model with 128 experts and 4 active per token, totalling 119B parameters but activating only about 6.5B per token. It handles text and image input, returns text, and supports a 256k-token context window. A per-request reasoning_effort parameter lets developers trade latency for depth: "none" returns fast answers comparable to Mistral Small 3.2, while "high" produces verbose step-by-step reasoning.
The open weights ship on Hugging Face as mistralai/Mistral-Small-4-119B-2603 and run on vLLM, llama.cpp, SGLang, Transformers, and NVIDIA NIM. The hosted version is served through Mistral's La Plateforme API as model ID mistral-small-2603 at $0.15 per million input tokens and $0.60 per million output tokens, and you can try it interactively in Le Chat.
| Released | 2026-03-16 |
|---|---|
| License | Apache 2.0 |
| Weights | Open weights |
| Parameters | 119B total / 6.5B active (MoE) |
| Context | 256K |
| Architecture | Mixture-of-Experts (MoE) with 128 experts and 4 active per token; 119B total parameters, ~6.5B active per token. Accepts text and image input and returns text. Exposes a per-request reasoning_effort control ("none" for fast Small-3.2-style responses, "high" for step-by-step reasoning). |
| Knowledge cutoff | Not disclosed |
| Modalities | Text, Vision |
| Status | Available |
Benchmarks
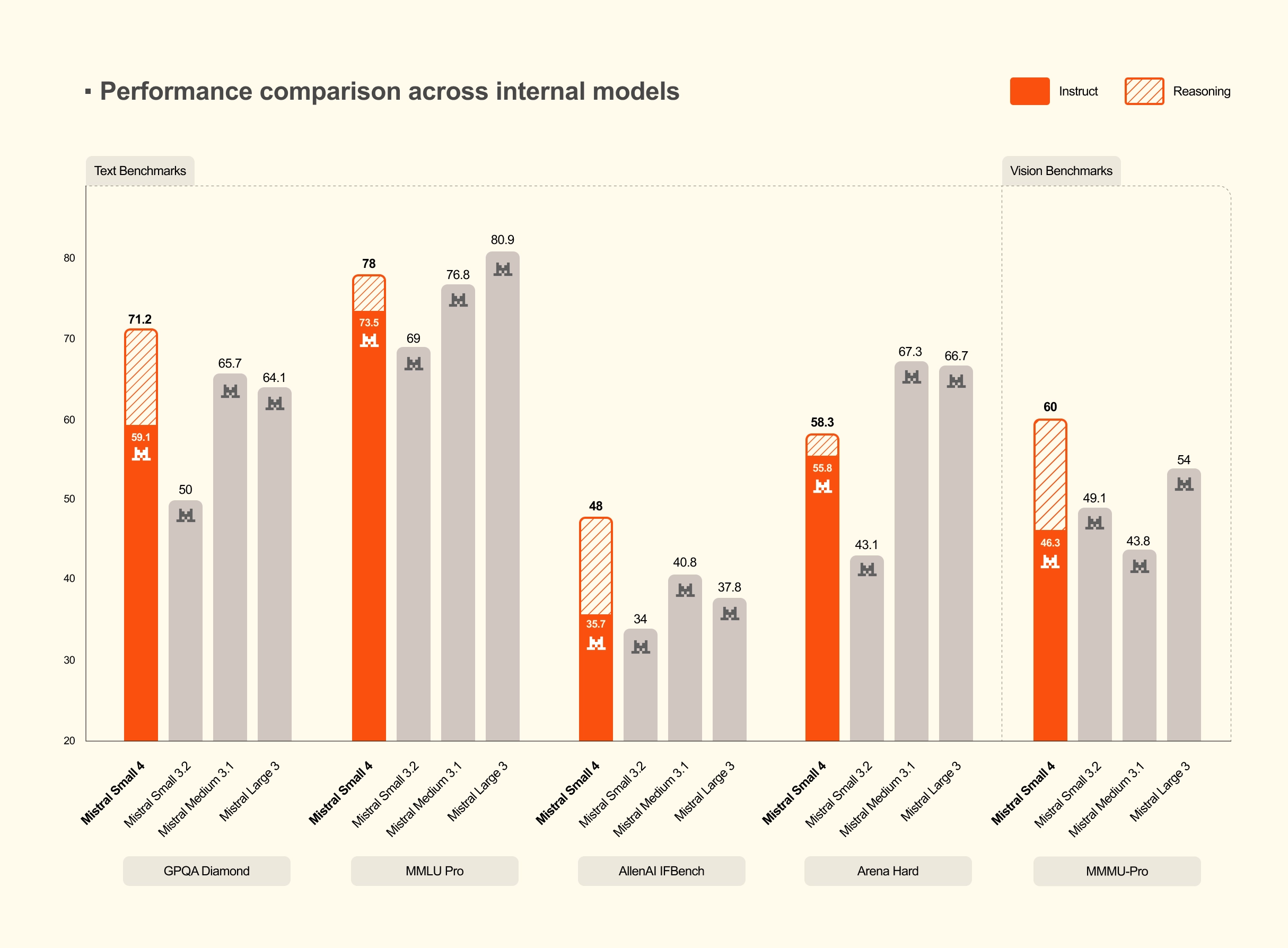
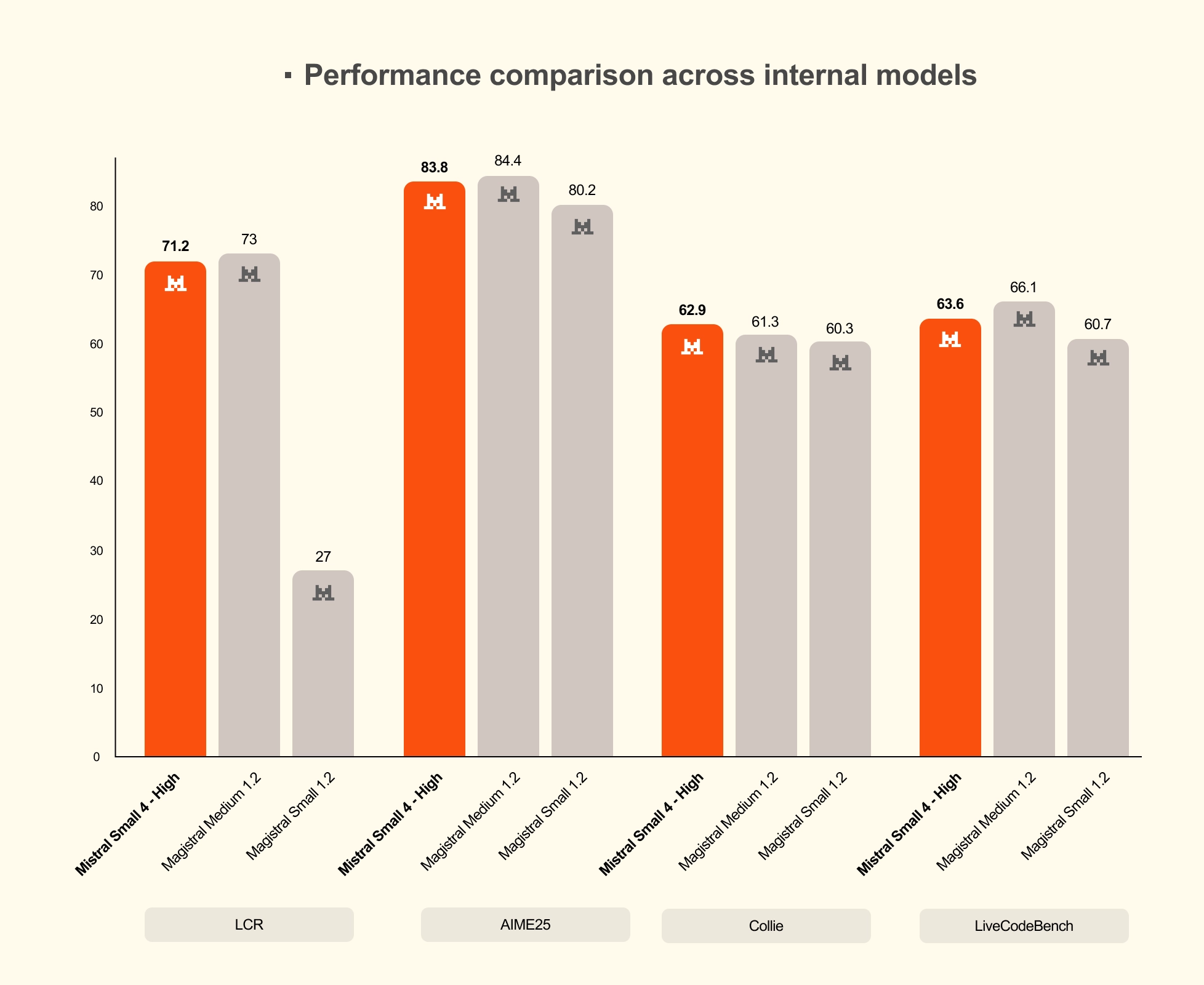
Performance comparison across internal models: Mistral Small 4 - High vs Magistral 1.2 models.
| Benchmark | Mistral Small 4 - High | Magistral Medium 1.2 | Magistral Small 1.2 |
|---|---|---|---|
| LCR | 71.2 score | 73 score | 27 score |
| AIME25 | 83.8 score | 84.4 score | 80.2 score |
| Collie | 62.9 score | 61.3 score | 60.3 score |
| LiveCodeBench | 63.6 score | 66.1 score | 60.7 score |
This model's scores
Scores on a 0–100 scale (25-point gridlines); higher is better. Each benchmark links to its published source.
Pricing
| Input | $0.15 / 1M tokens per 1M tokens |
|---|---|
| Output | $0.60 / 1M tokens per 1M tokens |
Hosted on Mistral's La Plateforme as model ID mistral-small-2603. Open weights are free to self-host under Apache 2.0.
Strengths
- Apache 2.0 open weights — free to self-host, fine-tune, and use commercially
- One model for chat, reasoning, vision, and agentic coding instead of separate specialist checkpoints
- Toggleable reasoning_effort (none/high) trades latency for depth on a per-request basis
- Sparse 119B MoE activates only ~6.5B parameters per token, keeping inference efficient
- Long 256k-token context window for big documents and codebases
- Concise outputs — competitive scores while emitting far fewer tokens than rivals (e.g. 0.72 AA LCR at ~1.6K characters)
Best for
- Self-hosted assistants and agents where an open, commercially-usable license matters
- Agentic coding workflows that need tool calling, structured output, and concise code
- Multimodal document and image understanding over long contexts
- Cost-sensitive reasoning tasks where you toggle deep thinking only when needed
- Fine-tuning a single base for chat, reasoning, and coding without maintaining multiple models
How to access
| Provider | Model ID |
|---|---|
| Mistral AI (La Plateforme) ↗ | mistral-small-2603 |
| OpenRouter ↗ | mistralai/mistral-small-2603 |
Mistral Small — every version
The full lineage of the Mistral Small line, newest first. Every version has its own page — click any to compare specs, benchmarks and pricing.
| Version | Released | Context | License |
|---|---|---|---|
| Mistral Small 4current | 2026-03-16 | — | Apache-2.0 |
| Mistral Small 3.2 | 2025-06-20 | — | Apache-2.0 |
| Mistral Small 3.1 | 2025-03-17 | — | Open weights |
| Mistral Small 3 | 2025-01-30 | — | Apache-2.0 |
| Mistral Small (24.09) | 2024-09-17 | — | Open weights |
FAQ
Is Mistral Small 4 open source?
The weights are released under the Apache 2.0 license, so you can download, self-host, fine-tune, and use Mistral Small 4 commercially for free. They ship on Hugging Face as mistralai/Mistral-Small-4-119B-2603.
How big is Mistral Small 4?
It is a Mixture-of-Experts model with 119B total parameters and 128 experts, but only 4 experts (about 6.5B parameters) are active per token, which keeps inference efficient relative to its total size.
What is the reasoning_effort parameter?
Mistral Small 4 takes a per-request reasoning_effort setting. "none" returns fast answers comparable to Mistral Small 3.2, while "high" produces step-by-step reasoning. This lets one model cover both quick chat and deeper problem-solving.
How much does Mistral Small 4 cost via the API?
On Mistral's hosted API (model ID mistral-small-2603) it is priced at $0.15 per million input tokens and $0.60 per million output tokens. Self-hosting the open weights is free under Apache 2.0.