
Overview
Muse Spark, released on April 8, 2026, is the first model from Meta Superintelligence Labs and Meta's first new flagship since Llama 4 in April 2025. It marks a strategic break for Meta: where the Llama line shipped open weights, Muse Spark is proprietary — Meta's first frontier model not released as open weights, though the company says it hopes to open-source future versions. It is positioned as a small, fast, natively multimodal reasoning model purpose-built for Meta's products.
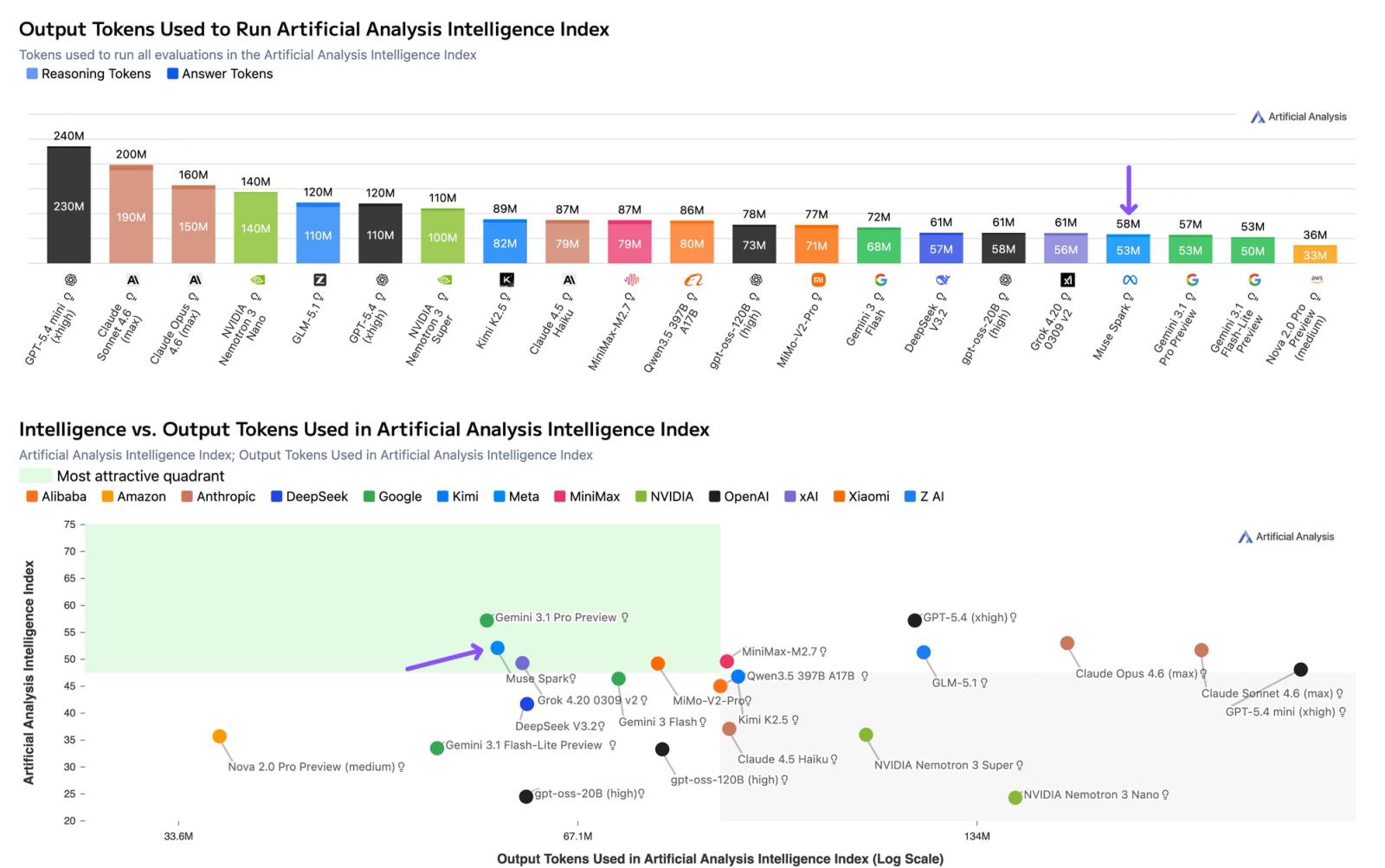
On the Artificial Analysis Intelligence Index, Muse Spark scores 52 — roughly tripling Llama 4 Maverick's 18 and placing it fourth overall, behind only Gemini 3.1 Pro, GPT-5.4, and Claude Opus 4.6. It is notably token-efficient, using about 58M output tokens to run the Index, in the same range as Gemini 3.1 Pro and far below Claude Opus 4.6 and GPT-5.4. Muse Spark is also the second-strongest vision model Artificial Analysis benchmarked, scoring 80.5% on MMMU-Pro.
Muse Spark's standout strength is health: trained on data curated with more than 1,000 physicians, it leads the HealthBench Hard leaderboard at 0.428, ahead of every other frontier model tested. Its Contemplating mode lifts hard-reasoning scores to 58.4 on Humanity's Last Exam (with tools) and 38.3 on FrontierScience Research, competing with extreme reasoning modes like Gemini Deep Think and GPT Pro. Today Muse Spark powers the Meta AI app and meta.ai for free and is rolling out across WhatsApp, Instagram, Facebook, Messenger, and AI glasses; a public API is in private preview.
| Released | 2026-04-08 |
|---|---|
| License | Proprietary (Meta) — Meta's first frontier model not released as open weights |
| Weights | API only |
| Parameters | Not disclosed by Meta |
| Context | 262K |
| Max output | Not disclosed by Meta |
| Architecture | Natively multimodal reasoning model. Meta Superintelligence Labs rebuilt its AI stack from the ground up to reach Llama 4 Maverick-level capability with over an order of magnitude less training compute. Reinforcement learning with a penalty on thinking time produces a "thought compression" effect — after first learning to think longer, the model compresses its reasoning to solve problems with far fewer tokens. A separate "Contemplating mode" scales test-time compute by orchestrating multiple agents that reason in parallel, then aggregating their solutions. Meta has not published parameter counts or whether the model is dense or mixture-of-experts. |
| Knowledge cutoff | Not disclosed by Meta |
| Modalities | Text, Vision, Audio |
| Status | Available |
Benchmarks
This model's scores
- Artificial Analysis Intelligence Index52index
- MMMU-Pro (vision)80.5%
- Humanity's Last Exam39.9%
- Humanity's Last Exam (with tools, Contemplating mode)58.4%
- FrontierScience Research (Contemplating mode)38.3%
- HealthBench Hard0.428score
- SWE-Bench Verified77.4%
- ARC-AGI-242.5%
- CritPT (physics research)11%
- Tau-squared Bench Telecom92%
Scores on a 0–100 scale (25-point gridlines); higher is better. Each benchmark links to its published source.
Pricing
| Input | Free / 1M tokens |
|---|---|
| Output | Free / 1M tokens |
Muse Spark is currently free to use via meta.ai and the Meta AI app (Meta account required). Artificial Analysis lists input and output at $0.00 per 1M tokens. There is no public paid API yet — API access is in private preview for select partners, and Meta has not announced a public rate card.
Strengths
- Leads the HealthBench Hard leaderboard (0.428), ahead of every other frontier model tested — trained with 1,000+ physicians
- Strong native multimodality — second-best vision model on MMMU-Pro (80.5%) behind only Gemini 3.1 Pro
- Highly token-efficient for its intelligence: ~58M output tokens to run the Artificial Analysis Index, far less than GPT-5.4 or Claude Opus 4.6
- Contemplating mode scales test-time compute via parallel agents, reaching 58.4 on Humanity's Last Exam (with tools)
- Reaches Llama 4 Maverick capability with over an order of magnitude less training compute
- Free to use today via meta.ai and the Meta AI app
Best for
- Health and medical question-answering where factual, comprehensive responses matter (its strongest area)
- Multimodal reasoning over images — visual STEM questions, entity recognition, and localization
- Visual coding — generating websites and small games from visual context
- Hard science and math reasoning, especially with Contemplating mode for the most difficult problems
- Powering consumer assistants across Meta's apps (WhatsApp, Instagram, Messenger) and AI glasses
- Agentic and tool-use workflows that benefit from multi-agent orchestration
How to access
| Provider | Model ID |
|---|---|
| Meta AI ↗ | muse-spark |
FAQ
Is Muse Spark open source?
No. Muse Spark is proprietary — it is Meta's first frontier model not released as open weights, a deliberate break from the open Llama line. Meta has said it hopes to open-source future versions of the model, but the April 2026 release is closed.
How much does Muse Spark cost?
It is currently free to use through meta.ai and the Meta AI app (a Meta account is required). Artificial Analysis lists input and output at $0.00 per 1M tokens. There is no public paid API yet — API access is in private preview for select partners, and Meta has not published a public rate card.
What is Contemplating mode?
Contemplating mode scales test-time compute by orchestrating multiple agents that reason in parallel and then aggregating their solutions, rather than relying on a single chain of thought. It lifts Muse Spark to 58.4 on Humanity's Last Exam (with tools) and 38.3 on FrontierScience Research, competing with extreme reasoning modes like Gemini Deep Think and GPT Pro.
What is Muse Spark best at?
Health. Trained on data curated with more than 1,000 physicians, Muse Spark leads the HealthBench Hard leaderboard at 0.428, ahead of every other frontier model tested. It is also a strong vision model, scoring 80.5% on MMMU-Pro — second only to Gemini 3.1 Pro.