
Overview
Qwen3.6 is the April 2026 release from the Qwen team at Alibaba Group, building on Qwen3.5. It is an open-weight line published under the Apache 2.0 license, distributed on Hugging Face and ModelScope and served through Alibaba Cloud Model Studio. The release leads with two open models: Qwen3.6-35B-A3B, a Mixture-of-Experts model with 35B total and roughly 3B active parameters (released 2026-04-16), and Qwen3.6-27B, a 27-billion-parameter dense model (released 2026-04-22) that the Qwen team frames as 'flagship-level coding in a 27B dense model.'
The headline story is parameter efficiency in agentic coding: the dense Qwen3.6-27B reaches 77.2 on SWE-bench Verified and 59.3 on Terminal-Bench 2.0, edging past the much larger Qwen3.5-397B-A17B MoE from the previous generation on most coding benchmarks. Qwen3.6 focuses on real-world utility — smoother front-end workflows, repository-level reasoning, and a 'thinking preservation' feature that keeps reasoning context across conversation history for iterative, agentic development.
Architecturally, Qwen3.6 uses a hybrid attention stack (Gated DeltaNet linear attention interleaved with periodic full Gated Attention) and Multi-Token Prediction for faster decoding. Both released models carry a vision encoder, accept text, image, and video input, and serve a native 262,144-token context that can be stretched toward ~1M tokens with YaRN RoPE scaling. As an Apache-2.0 release, the weights can be self-hosted via vLLM, SGLang, llama.cpp, MLX, or Transformers, or accessed through hosted APIs.
| Released | 2026-04 |
|---|---|
| License | Apache 2.0 |
| Weights | Open weights |
| Parameters | 27B dense (Qwen3.6-27B); 35B total / 3B active MoE (Qwen3.6-35B-A3B) |
| Context | 262K (extensible ~1M) |
| Max output | ~32K (up to ~82K for complex reasoning) |
| Architecture | Hybrid attention: stacked blocks of Gated DeltaNet (linear attention) plus periodic Gated (full) Attention, trained with Multi-Token Prediction (MTP). The 27B is dense (64 layers, hidden size 5120); the 35B-A3B is a sparse Mixture-of-Experts (256 experts, 8 routed + 1 shared active). Both include a vision encoder and a "thinking" reasoning mode with thinking-preservation across turns. |
| Knowledge cutoff | Not publicly disclosed |
| Modalities | Text, Vision, Video |
| Status | Available |
Benchmarks
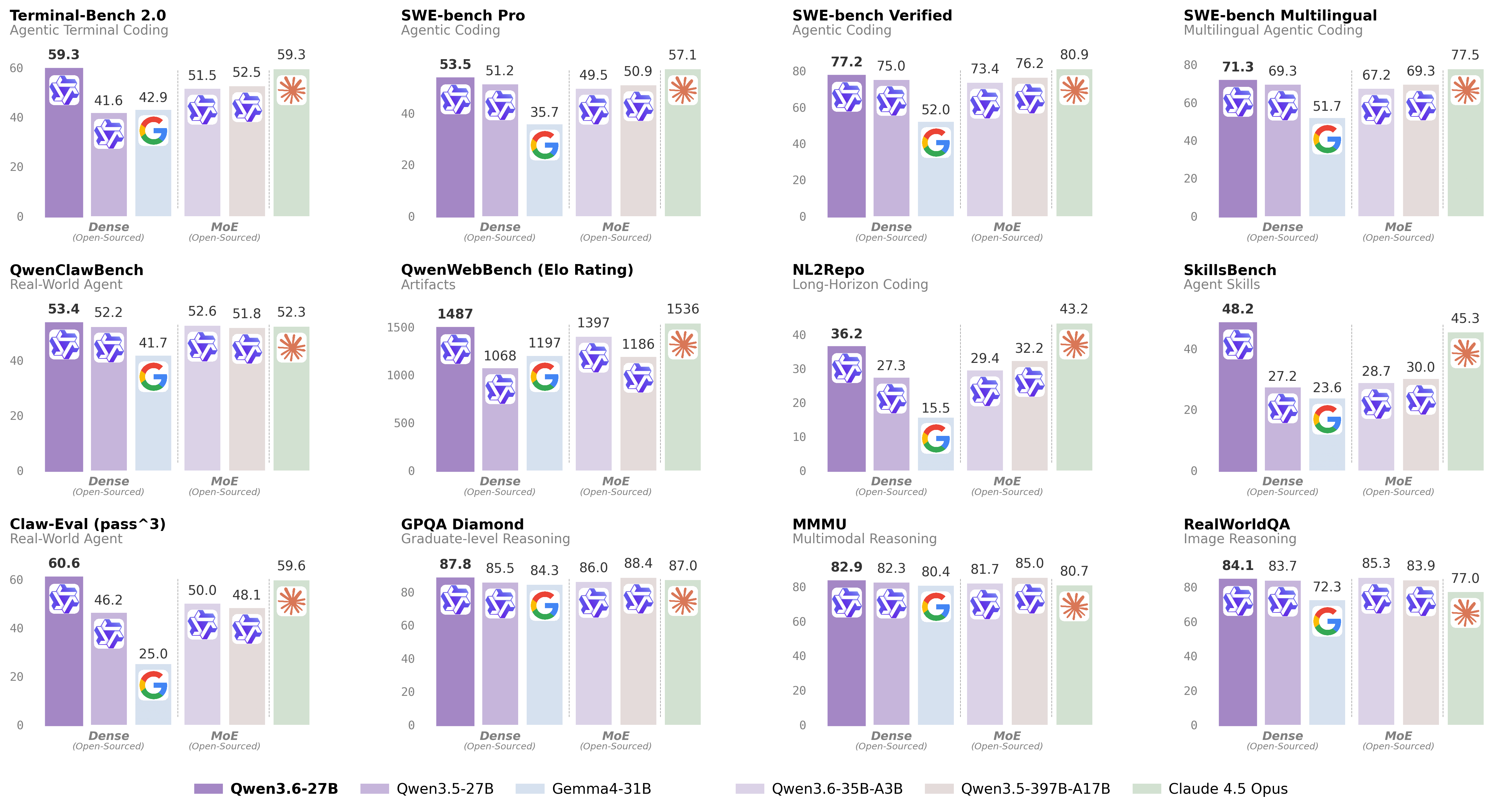
Qwen3.6-27B official benchmark comparison (language + vision-language) vs Qwen3.5-27B, Qwen3.5-397B-A17B, Gemma4-31B, Claude 4.5 Opus, and Qwen3.6-35B-A3B, from the official Qwen model card. Showing 20 of 43 published benchmarks.
| Benchmark | Qwen3.5-27B | Qwen3.5-397B-A17B | Gemma4-31B | Claude 4.5 Opus | Qwen3.6-35B-A3B | Qwen3.6-27B |
|---|---|---|---|---|---|---|
| SWE-bench Verified | 75% | 76.2% | 52% | 80.9% | 73.4% | 77.2% |
| SWE-bench Pro | 51.2% | 50.9% | 35.7% | 57.1% | 49.5% | 53.5% |
| SWE-bench Multilingual | 69.3% | 69.3% | 51.7% | 77.5% | 67.2% | 71.3% |
| Terminal-Bench 2.0 | 41.6% | 52.5% | 42.9% | 59.3% | 51.5% | 59.3% |
| SkillsBench Avg5 | 27.2% | 30% | 23.6% | 45.3% | 28.7% | 48.2% |
| QwenWebBench | 1068 Elo | 1186 Elo | 1197 Elo | 1536 Elo | 1397 Elo | 1487 Elo |
| NL2Repo | 27.3% | 32.2% | 15.5% | 43.2% | 29.4% | 36.2% |
| Claw-Eval Avg | 64.3% | 70.7% | 48.5% | 76.6% | 68.7% | 72.4% |
| Claw-Eval Pass^3 | 46.2% | 48.1% | 25% | 59.6% | 50% | 60.6% |
| QwenClawBench | 52.2% | 51.8% | 41.7% | 52.3% | 52.6% | 53.4% |
| MMLU-Pro | 86.1% | 87.8% | 85.2% | 89.5% | 85.2% | 86.2% |
| MMLU-Redux | 93.2% | 94.9% | 93.7% | 95.6% | 93.3% | 93.5% |
| SuperGPQA | 65.6% | 70.4% | 65.7% | 70.6% | 64.7% | 66% |
| C-Eval | 90.5% | 93% | 82.6% | 92.2% | 90% | 91.4% |
| GPQA Diamond | 85.5% | 88.4% | 84.3% | 87% | 86% | 87.8% |
| LiveCodeBench v6 | 80.7% | 83.6% | 80% | 84.8% | 80.4% | 83.9% |
| HMMT Feb 25 | 92% | 94.8% | 88.7% | 92.9% | 90.7% | 93.8% |
| HMMT Nov 25 | 89.8% | 92.7% | 87.5% | 93.3% | 89.1% | 90.7% |
| HMMT Feb 26 | 84.3% | 87.9% | 77.2% | 85.3% | 83.6% | 84.3% |
| IMOAnswerBench | 79.9% | 80.9% | 74.5% | 84% | 78.9% | 80.8% |
This model's scores
- SWE-bench Verified77.2%
- Terminal-Bench 2.059.3%
- MMLU-Pro86.2%
- AIME 202694.1%
- GPQA Diamond87.8%
- MMMU Pro75.8%
Scores on a 0–100 scale (25-point gridlines); higher is better. Each benchmark links to its published source.
Pricing
| Input | $0.2885 / 1M tokens per 1M tokens |
|---|---|
| Output | $3.17 / 1M tokens per 1M tokens |
Qwen3.6-27B via OpenRouter (lowest listed provider); prices vary by host. The Apache-2.0 weights can also be self-hosted at no per-token cost.
Strengths
- Flagship-level agentic coding at small scale — the 27B dense model scores 77.2 on SWE-bench Verified, beating the prior-gen 397B MoE on most coding benchmarks
- Apache 2.0 open weights — free to self-host, fine-tune, and deploy commercially with no license gate
- Long context out of the box (262K native, extensible toward ~1M via YaRN scaling)
- Multimodal input — text, images, and video accepted via a built-in vision encoder
- Efficient hybrid architecture (Gated DeltaNet + periodic full attention) with Multi-Token Prediction for lower-latency decoding
- Thinking-preservation keeps reasoning context across turns, suited to iterative agentic workflows
- Broad ecosystem support: vLLM, SGLang, llama.cpp, MLX, Transformers, plus Qwen Code and Qwen-Agent
Best for
- Agentic coding and repository-level software engineering (SWE-bench / Terminal-Bench style tasks)
- Front-end and full-stack web development workflows
- Self-hosted, privacy-sensitive deployments where Apache-2.0 weights matter
- Long-document and large-codebase analysis using the 262K-token context
- Multimodal tasks combining code, images, and video understanding
- Fine-tuning a strong open base for domain-specific coding or reasoning agents
- Cost-efficient inference where a 27B dense or 3B-active MoE beats running a much larger model
How to access
| Provider | Model ID |
|---|---|
| Alibaba Cloud Model Studio ↗ | qwen3.6-27b |
| OpenRouter ↗ | qwen/qwen3.6-27b |
| Hugging Face (self-host) ↗ | Qwen/Qwen3.6-27B |
Qwen (open-weight) — every version
The full lineage of the Qwen (open-weight) line, newest first. Every version has its own page — click any to compare specs, benchmarks and pricing.
| Version | Released | Context | License |
|---|---|---|---|
| Qwen3.6current | 2026-04 | — | Apache-2.0 |
| Qwen3.5 | 2026-02-16 | — | Apache-2.0 |
| Qwen3 (2507 update) | 2025-07 | — | Apache-2.0 |
| Qwen3 | 2025-04-28 | — | Apache-2.0 |
| Qwen2.5 | 2024-09 | — | Apache-2.0 |
| Qwen2 | 2024-06 | — | Apache-2.0 |
FAQ
Is Qwen3.6 open source?
The released Qwen3.6 models — Qwen3.6-27B (dense) and Qwen3.6-35B-A3B (MoE) — are open-weight under the Apache 2.0 license. You can download them from Hugging Face or ModelScope and self-host, fine-tune, or deploy commercially. (Note: Alibaba's separate Qwen3.6-Max flagship is a closed-weight, API-only model.)
What is the difference between Qwen3.6-27B and Qwen3.6-35B-A3B?
Qwen3.6-27B is a 27-billion-parameter dense model and the team's 'flagship-level' coding model. Qwen3.6-35B-A3B is a Mixture-of-Experts model with 35B total parameters but only ~3B active per token, trading a bit of peak accuracy for cheaper, faster inference. Both share the hybrid attention architecture, vision input, and 262K context.
How long is Qwen3.6's context window?
Both open models serve a native context of 262,144 tokens and can be extended toward roughly 1 million tokens using YaRN RoPE scaling. Qwen recommends keeping at least 128K of context to preserve the model's reasoning behavior.
How good is Qwen3.6 at coding?
The dense Qwen3.6-27B scores 77.2 on SWE-bench Verified and 59.3 on Terminal-Bench 2.0, beating the prior-generation Qwen3.5-397B-A17B MoE on most coding benchmarks despite being far smaller. It is tuned for agentic coding, front-end workflows, and repository-level reasoning.