Epoch AI / METR · 2026-04-10 · major
MirrorCode: AI Reimplements a 16k-Line Codebase — Weeks of Human Work in One Run
Epoch AI and METR released MirrorCode, a long-horizon coding benchmark where AI must reimplement real CLI programs from execute-only access. Claude Opus 4.6 reimplemented gotree (16,905 lines, 40+ commands) passing 99.95% of 2,001 tests — a task estimated at 2–17 weeks of human engineering.
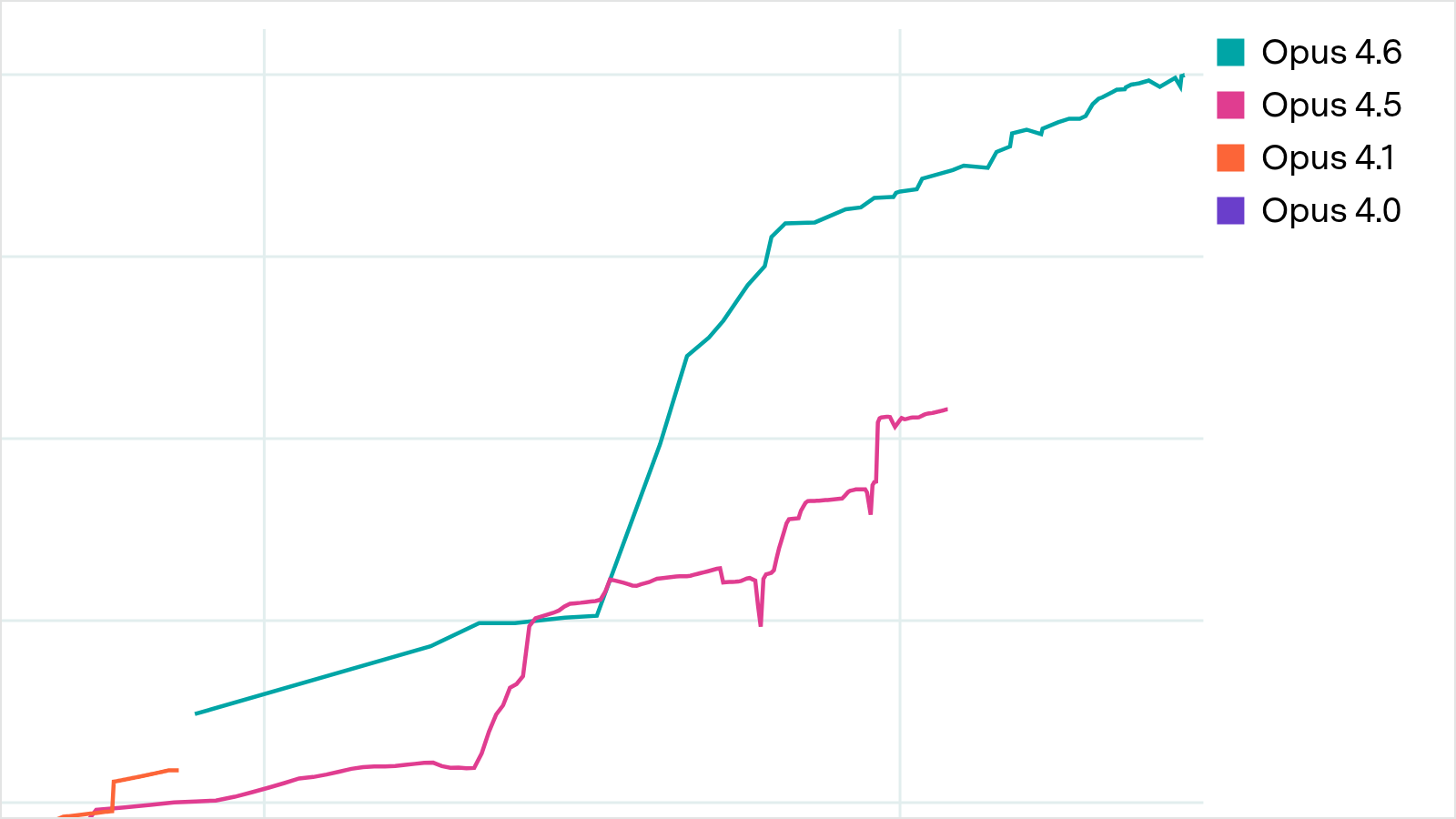
Claude Opus 4.6 autonomously reimplemented a 16k-line bioinformatics toolkit from scratch — no source code, just an executable and tests.
Key specs
| Gotree loc | 16,905 |
|---|---|
| Gotree test pass rate | 99.95% |
| Human equivalent time | 2–17 weeks |
| Token budget | 1 billion |
| Model | Claude Opus 4.6 |
What is it?
MirrorCode is a long-horizon software engineering benchmark from Epoch AI and METR. Each task gives an AI agent execute-only access to a real CLI program (no source) and a test suite, then asks it to reimplement the program from scratch. The benchmark spans Unix utilities, bioinformatics tools, cryptography, interpreters, and configuration languages — programs ranging from ~900 to 61,000 lines of code.
How does it work?
The agent runs the reference program to observe its behavior, forms hypotheses about its implementation, writes code, and iterates against the test suite — all within a fixed token budget (up to 1 billion tokens). Performance is measured by exact output matching across hundreds to thousands of end-to-end test cases. Claude Opus 4.6 solved gotree (a 16,905-line Go bioinformatics toolkit with 40+ subcommands), passing 99.95% of 2,001 tests. Smaller programs like cal and choose were solved by earlier models; the 61k-line Pkl configuration language remains unsolved at ~35% pass rate.
Why does it matter?
This is the first benchmark to put a concrete number on AI's reach into weeks-long engineering tasks. The gotree result demonstrates that a frontier model can reverse-engineer a complex, multi-command production tool entirely from behavioral observation. The token budget and test-pass metric give teams a replicable framework for measuring how far this capability extends as models improve.
Who is it for?
AI safety researchers tracking capability timelines; engineering teams evaluating AI for autonomous coding tasks
Try it
https://epoch.ai/blog/mirrorcode-preliminary-results