Simon Willison · 2026-05-08 · notable
Simon Willison: The Unreasonable Effectiveness of HTML Output From Claude Code
Willison reverses his Markdown-by-default rule for LLM output. With current models, asking Claude or GPT-5.5 for HTML unlocks SVG diagrams, inline JS, and self-contained explainers that Markdown cannot express.
With reasoning-tier models, Markdown is leaving capability on the table — ask for HTML and the same prompt produces something you can actually click through.
What is it?
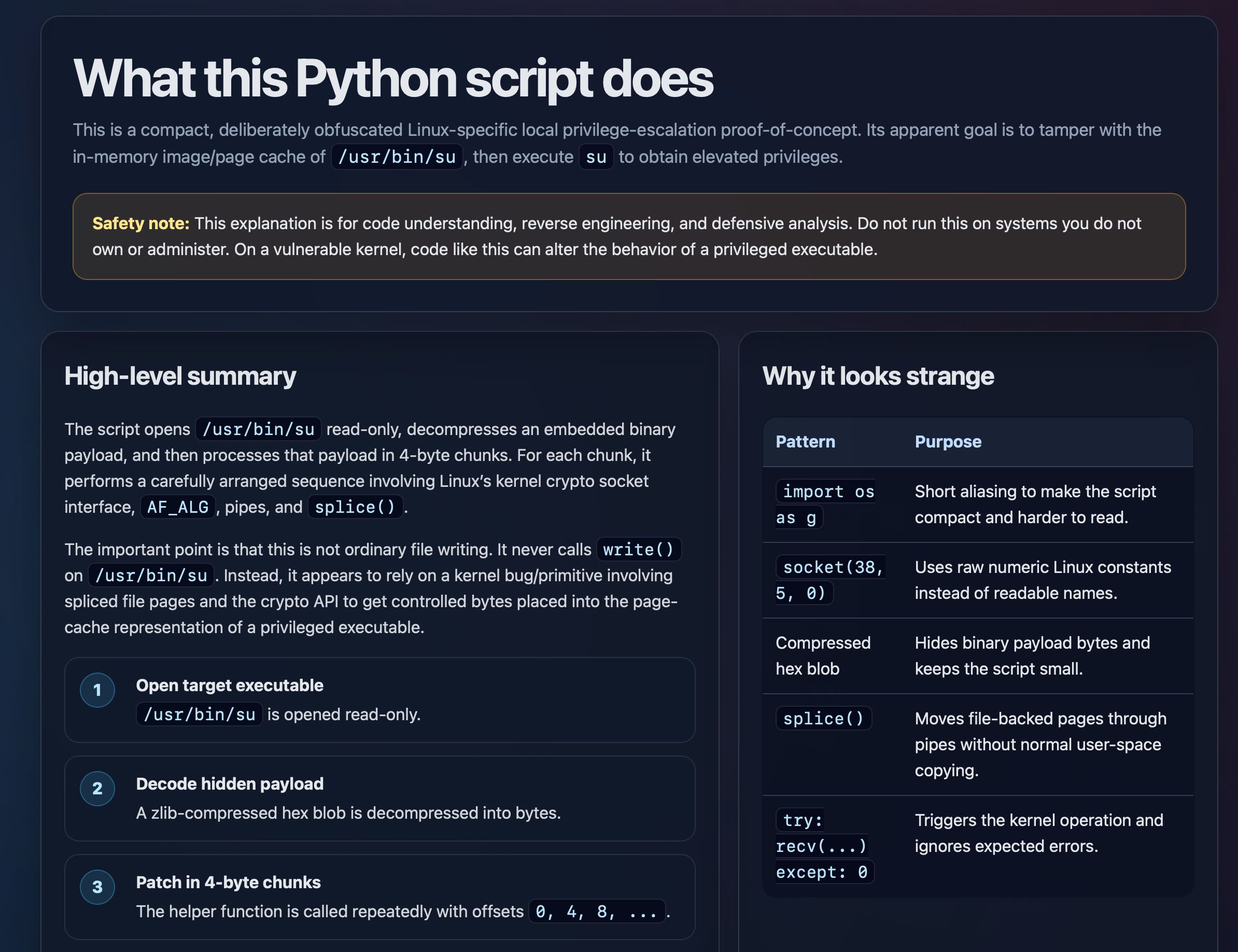
A short post from Simon Willison riffing on Thariq Shihipar's argument that we default to Markdown for LLM output for legacy reasons (token cost, GPT-4 era) and shouldn't anymore. Willison demos asking GPT-5.5 to explain a Linux io_uring exploit as a single self-contained HTML page, with annotated code, SVG control-flow diagrams, and collapsible sections.
How does it work?
Same prompt, different output format. Markdown collapses into headings + code blocks; HTML opens up SVG, CSS, JS, anchor navigation, and progressive disclosure. Models trained on the open web are equally fluent in both — Markdown was a token-budget compromise from a different model generation that has quietly stopped paying for itself.
Why does it matter?
Anyone wiring Claude Code, Codex, or a custom agent into a doc-generation or explainer pipeline has a free upgrade waiting in the prompt template. The post is also a useful pointer to Thariq's longer argument and to the io_uring HTML explainer Willison built in one shot.
Who is it for?
anyone using LLMs for technical writing, internal docs, or explainer UIs