In plain English
An embedding is a list of numbers. The dimension count is simply how many numbers are in that list. When a model card says text-embedding-3-small outputs 1,536-dimensional vectors, it means every piece of text you embed becomes a list of exactly 1,536 decimal numbers — nothing more, nothing less. A 3,072-dimensional model produces a list twice as long. A 384-dimensional one produces a list four times shorter.
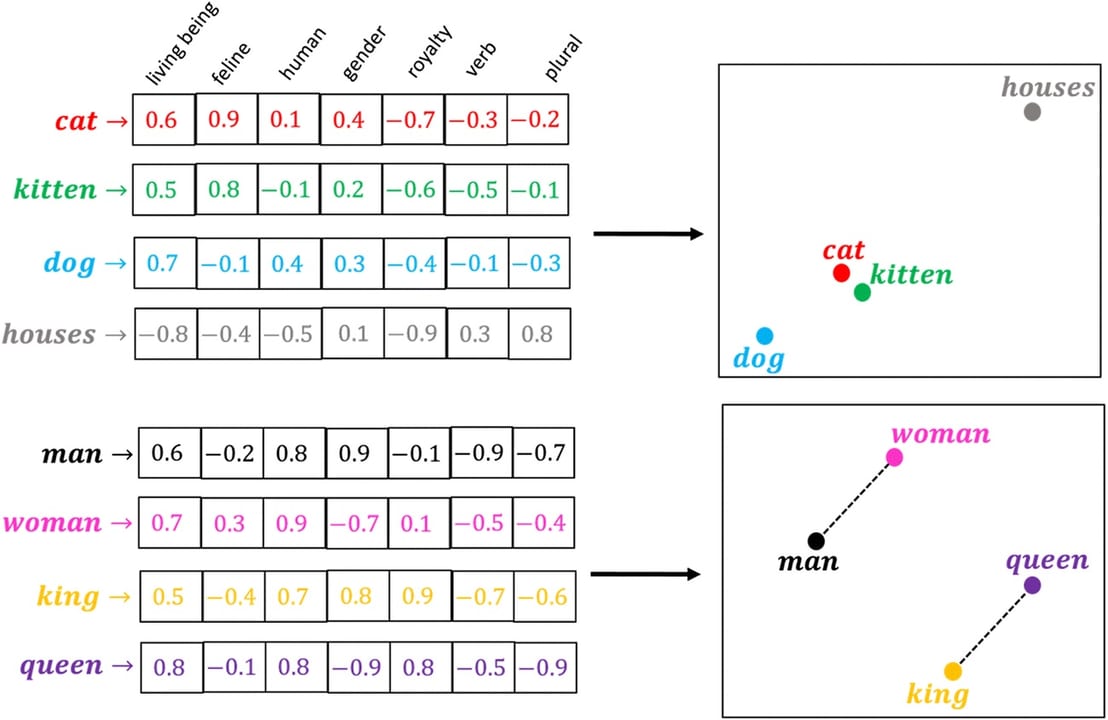
Think of it like a scorecard. Imagine you're rating a movie across a set of attributes: how funny it is, how scary, how romantic, how long, how much dialogue, how much action, and so on. A very coarse scorecard might use just 10 attributes; a detailed critic's rubric might use 500. Each movie ends up as a list of numbers — one score per attribute. Two movies with similar lists are similar movies. Embedding dimensions work the same way: each dimension is one learned attribute of meaning, and the model can tell apart more nuanced concepts when it has more attributes to work with.
Crucially, no single dimension has a human-readable label. There is no "dimension 47 = how formal the writing is." The model discovers its own abstract attributes during training, distributed across all the dimensions at once. You never read individual dimension values; you only ever compare whole vectors to measure how close two meanings sit.
Why dimension count matters to builders
Dimension count is not just an implementation detail — it directly controls three things you pay for in production: retrieval quality, storage cost, and query latency. All three move in the same direction when you increase dimensions, which is why "just use the biggest model" is not a universal answer.
Storage and cost grow linearly
Every vector in your database scales with dimensions. Going from 768 to 3,072 dimensions quadruples the raw storage needed. At 10 million vectors, that's roughly 230 MB at 384 dimensions versus 3.7 GB at 3,072 dimensions in float32. Cloud vector database pricing follows storage, so the bill scales accordingly. For a large corpus this is often the deciding factor in dimension choice.
Search latency rises with dimensions
Every similarity comparison must multiply and sum across all dimensions. Real systems use approximate nearest-neighbor (ANN) indexes like HNSW, which don't compare every vector — but those indexes still do more work per comparison at higher dimensions. Measured latency on HNSW search drops from roughly 2 ms at 768 dimensions to under 0.7 ms at 64 dimensions. For applications serving thousands of queries per second, those fractions add up fast.
Quality improves — up to a point
More dimensions let the model encode finer semantic distinctions. OpenAI's text-embedding-3-large (3,072 dimensions) scores 64.6% on the MTEB benchmark versus 61.0% for the older text-embedding-ada-002 (1,536 dimensions). For multilingual tasks the gap is even sharper. But the gains compress quickly: shrinking text-embedding-3-large from 3,072 to 1,536 dimensions still beats ada-002 at full size, and the model can be compressed all the way to 256 dimensions while still outperforming ada-002 uncompressed. Beyond a model-specific sweet spot, adding more dimensions stops helping much.
How dimensions encode meaning
When an embedding model processes your text, it passes it through many transformer layers. At the end, a pooling step collapses the per-token outputs into a single vector of the model's fixed output size. Each position in that vector is a weighted combination of learned features — patterns the model discovered across billions of training examples. The model is never told what these features should represent; it learns the most useful breakdown on its own.
Why higher dimension = more expressive
Mathematically, a higher-dimensional space can hold more distinct directions. Two concepts that happen to land in similar positions in 64 dimensions might be pulled apart and distinguishable in 1,536 dimensions — the extra dimensions give the model room to encode the subtle difference. A simple analogy: a 2D city map can tell you which neighborhood a building is in; a 3D model also tells you which floor. More dimensions means more ways to be different.
The storage math
Each dimension is typically stored as a 32-bit float (4 bytes). The per-vector memory formula is straightforward:
# Bytes per vector
bytes_per_vector = dimensions * 4 # float32
# Total for a corpus
num_vectors = 1_000_000
total_gb = (num_vectors * bytes_per_vector) / 1e9
print(f"384 dims: {384 * 4 / 1e3:.1f} KB/vector, {1e6 * 384 * 4 / 1e9:.2f} GB for 1M vectors")
print(f"768 dims: {768 * 4 / 1e3:.1f} KB/vector, {1e6 * 768 * 4 / 1e9:.2f} GB for 1M vectors")
print(f"1536 dims: {1536 * 4 / 1e3:.1f} KB/vector, {1e6 * 1536 * 4 / 1e9:.2f} GB for 1M vectors")
print(f"3072 dims: {3072 * 4 / 1e3:.1f} KB/vector, {1e6 * 3072 * 4 / 1e9:.2f} GB for 1M vectors")
# Output:
# 384 dims: 1.5 KB/vector, 1.54 GB for 1M vectors
# 768 dims: 3.1 KB/vector, 3.07 GB for 1M vectors
# 1536 dims: 6.1 KB/vector, 6.14 GB for 1M vectors
# 3072 dims: 12.3 KB/vector, 12.29 GB for 1M vectorsCommon dimension sizes compared
Different embedding models output different default dimensions. The table below maps the most common options to concrete specs so you can compare apples to apples:
| Model | Default dims | Adjustable? | MTEB score | Typical use case |
|---|---|---|---|---|
all-MiniLM-L6-v2 (open-source) | 384 | No | ~56 | Local/edge, cost-sensitive |
nomic-embed-text-v1.5 (open-source) | 768 | Yes (via MRL) | ~62 | Long-context open-source |
text-embedding-3-small (OpenAI) | 1,536 | Yes (via MRL) | ~62 | General-purpose hosted |
voyage-3 (Voyage AI) | 1,024 | Yes (256-2048) | ~65 | RAG, long context |
text-embedding-3-large (OpenAI) | 3,072 | Yes (via MRL) | 64.6 | High-accuracy hosted |
voyage-3-large (Voyage AI) | 1,024 default | Yes (256-2048) | ~67 | State-of-art retrieval |
Notice that larger default dimension does not automatically mean better MTEB score. Voyage AI's voyage-3 achieves competitive quality at 1,024 dimensions, costing 3-4x less storage than OpenAI's 3,072-dimensional model. The quality of training data and the training objective matter at least as much as raw dimension count.
- Less storage per vector
- Faster similarity search
- Lower memory for ANN index
- Cheaper to host at scale
- May miss fine-grained distinctions
- Good for broad topics and RAG
- More expressive: finer distinctions
- Better on multilingual tasks
- Higher MTEB benchmark scores
- More storage per vector
- Slower query at scale
- Better for technical, precise domains
Flexible dimensions: Matryoshka embeddings
A key practical question is: "Can I use a high-quality model but save storage by using fewer dimensions?" With Matryoshka Representation Learning (MRL), the answer is yes — as long as the model was trained with MRL.
How MRL works
An MRL-trained model applies its training loss not just to the full vector, but also to sliced prefixes — the first 64 dimensions, the first 128, the first 256, and so on. This forces the model to front-load the most important information into the early dimensions. The result is a vector where you can safely truncate from the right and still get a useful, meaningful embedding. No retraining needed.
OpenAI's text-embedding-3-small and text-embedding-3-large both support MRL via their API's dimensions parameter. Voyage AI's models support output dimensions of 256, 512, 1,024, or 2,048. Many open-source models on Hugging Face (including Nomic Embed) also include MRL training.
from openai import OpenAI
client = OpenAI()
# Full 3,072 dimensions (default for text-embedding-3-large)
full = client.embeddings.create(
model="text-embedding-3-large",
input="machine learning",
)
print(len(full.data[0].embedding)) # 3072
# Reduced to 256 dimensions via the 'dimensions' parameter
small = client.embeddings.create(
model="text-embedding-3-large",
input="machine learning",
dimensions=256,
)
print(len(small.data[0].embedding)) # 256
# Still outperforms text-embedding-ada-002 at 1536 dims on MTEBGoing deeper
The curse of dimensionality and why it doesn't bite as hard as you'd expect. In theory, higher dimensions make nearest-neighbor search harder — a phenomenon called the curse of dimensionality, where points become equidistant as dimensions grow. In practice, embedding models learn low-dimensional structure: the "intrinsic dimensionality" of natural language meaning is much lower than 3,072. ANN indexes like HNSW exploit this structure and scale well into the thousands of dimensions, which is why real systems don't observe the textbook curse. That said, above a few thousand dimensions you do start paying real costs with diminishing accuracy returns.
Quantization: shrink bytes, keep most quality. If you can't reduce dimensions, you can reduce precision. Float32 (4 bytes/dim) is the default, but modern vector DBs and libraries like Sentence Transformers also support int8 (1 byte/dim) and binary (1 bit/dim) quantization. Int8 cuts storage by 4x with a small recall penalty; binary cuts by 32x with a larger but often acceptable penalty for first-pass retrieval in a two-stage pipeline. Combining MRL dimension reduction with int8 quantization can reduce storage by 32x or more.
Matryoshka vs. post-hoc dimensionality reduction. Before MRL, teams used PCA to compress existing embeddings to fewer dimensions. PCA is unsupervised — it doesn't know what the embedding space is for, so it may discard directions that matter for retrieval. MRL almost always outperforms PCA at the same compression ratio because the training objective explicitly rewards the truncated prefixes for being useful.
Don't conflate dimension count with context length. Dimension count is the output size — how many numbers represent the final embedding. Context length is the input constraint — how many tokens the model can read before it pools. A model can have a 512-token input limit and still output 3,072 dimensions, or a 32,000-token context and only output 1,024 dimensions. They are independent hyperparameters controlled by different parts of the architecture.
Choosing dimensions in practice. Start by checking whether your chosen model supports MRL — if so, you have flexibility to tune later. For RAG over a few hundred thousand documents, 768-1,024 dimensions is usually fine. For multilingual retrieval, precise technical domains (code, legal, medical), or tasks requiring fine-grained ranking, push to 1,536 or higher. For edge/mobile inference or search serving over hundreds of millions of vectors, go as low as 256-512 with an MRL-trained model. Always measure recall@K on a held-out sample of your actual queries rather than relying on published benchmarks alone — MTEB scores don't always predict real-world accuracy on your specific domain.
FAQ
What does it mean when an embedding model has 768 dimensions?
Every piece of text you embed is converted into a list of exactly 768 decimal numbers. Each number is a learned feature the model uses to encode aspects of meaning. Two pieces of text with similar meaning get similar lists; unrelated text gets lists that are far apart. The 768 is a fixed property of that model.
Does a higher embedding dimension always mean better quality?
Not automatically. Quality depends heavily on the training data, training objective, and model architecture — not just dimension count. Voyage AI's voyage-3 achieves competitive or superior MTEB scores at 1,024 dimensions compared to models with 3,072 dimensions. Bigger dimensions can encode finer distinctions, but a well-trained smaller model often outperforms a poorly-trained larger one.
How do I choose between 768, 1536, and 3072 dimensions?
Start with your scale. Under 1 million vectors, 1,536 dimensions (like OpenAI text-embedding-3-small) is a safe default. At tens of millions of vectors, memory and latency costs make 768-1,024 dimensions more practical. For very high precision requirements (multilingual retrieval, dense technical text), 3,072 dimensions may justify the cost. Always benchmark recall on a sample of your own data.
What is Matryoshka representation learning and how does it help?
Matryoshka Representation Learning (MRL) trains a model so that the first N dimensions of its output are themselves a useful embedding, for many values of N. This lets you truncate the vector at query time — say from 3,072 to 256 — to save storage and speed up search, while retaining most of the quality. OpenAI's embedding v3 models and Voyage AI's models both support this via a dimensions API parameter.
Does reducing embedding dimensions require retraining my model?
With an MRL-trained model, no — you just request fewer dimensions at inference time (e.g., via OpenAI's dimensions parameter) or truncate and re-normalize the vector yourself. However, you must re-embed your entire existing corpus at the new dimension size and rebuild your vector index. Mixing vectors of different dimension sizes or from different model versions will silently corrupt similarity scores.
How much storage does one million embedding vectors require?
At 384 dimensions in float32, about 1.5 GB. At 1,536 dimensions, about 6 GB. At 3,072 dimensions, about 12 GB. These figures are for raw vector bytes only — ANN index structures (like HNSW) can add 2-3x on top. Int8 quantization cuts the raw vector size by 4x, and MRL truncation compounds on top of that.