In plain English
A computer can't compare two sentences the way you do. To it, "How do I get a refund?" and "What's your return policy?" are just different strings of characters with almost no letters in common — yet a person sees instantly that they mean nearly the same thing. To make a machine feel that closeness, you first need to turn each sentence into a list of numbers, an embedding, where similar meanings land close together.
sentence-transformers (also called SBERT) is the open-source Python library that does exactly that. You hand it text, it hands you back vectors. One line — model.encode("some text") — and you have an embedding you can search, cluster, or compare. It is the most widely used library for this job, and most semantic-search and RAG tutorials you'll ever read are quietly built on top of it.
Think of it as a translator from words into coordinates. A street address is just text, but a GPS coordinate is a pair of numbers you can do math on — measure distances, find what's nearby, draw a map. sentence-transformers gives every sentence its own coordinate in a high-dimensional "meaning space," so two sentences that mean the same thing end up as near neighbors, even when they share no words.
Why it matters
Before SBERT, comparing the meaning of two sentences with a BERT-style model was painfully slow. To score how similar two sentences were, you had to feed both of them through the model together. Comparing one query against 10,000 documents meant 10,000 model runs — hopeless for real-time search.
SBERT's key move was to make the embedding standalone. Each sentence is encoded once into a fixed vector, all on its own. After that, comparing two sentences is just cheap arithmetic on the vectors — no model needed. You can embed your whole document collection ahead of time, then answer any query in milliseconds. That single change is what made semantic search at scale practical.
What builders actually use it for
- Semantic search and RAG — embed your documents, embed the user's question, and retrieve the closest passages by meaning instead of keywords. This is the heart of every retriever.
- Clustering and deduplication — group thousands of support tickets, reviews, or news headlines by topic, or spot near-duplicates, without reading them.
- Classification and recommendations — embeddings make strong, cheap features: "find more like this," tag routing, intent detection.
- Reranking — a separate, more accurate model (more on this below) that re-scores a shortlist of search results to push the best one to the top.
- Training your own model — fine-tune an embedding model on your data so it understands your domain's jargon, not just generic English.
Crucially, it is a shared, standard library. When everyone uses the same encode() interface and the same published models, a tutorial, a benchmark, and your production code all behave the same way. That reproducibility is half the reason the embedding ecosystem grew so fast — you can swap in a better model later by changing one string, and the rest of your pipeline doesn't move.
How it works
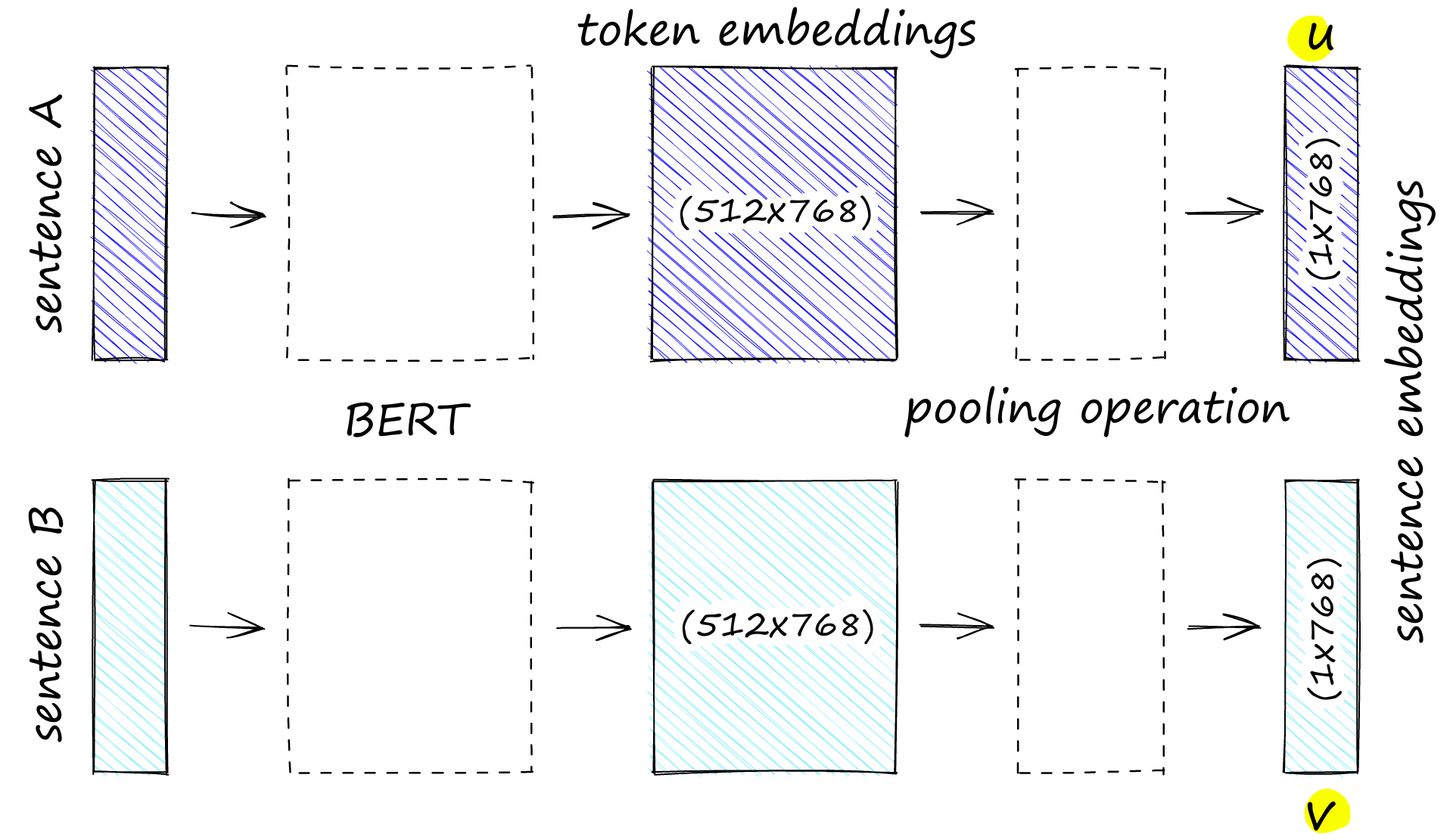
Under the hood, a sentence-transformers model is usually a transformer (a BERT-family network) followed by a pooling step. The transformer reads the text and produces one vector per token (roughly per word-piece). Pooling then squashes all those token vectors into a single sentence vector — most commonly by averaging them ("mean pooling"). The result is one fixed-length vector, no matter how long the input was.
From the user's side, none of that is visible. You load a model and call encode(). The library handles tokenizing, batching, running the network, pooling, and (optionally) normalizing for you.
from sentence_transformers import SentenceTransformer
# Load a pretrained embedding model.
model = SentenceTransformer("a-pretrained-embedding-model")
sentences = [
"How do I get a refund?",
"What is your return policy?",
"The weather in Paris is mild today.",
]
# One call turns text into vectors (a NumPy array of shape [3, dim]).
embeddings = model.encode(sentences, normalize_embeddings=True)
# Similarity is just a dot product now — no model needed.
similarities = model.similarity(embeddings, embeddings)
print(similarities)
# The first two sentences score high; the Paris one scores low.Once text is vectors, "how similar are these?" becomes a simple geometry question. The standard answer is cosine similarity: the angle between two vectors, scored from -1 (opposite) to 1 (identical). Pass normalize_embeddings=True and cosine similarity becomes a plain dot product, which is exactly what fast semantic search and vector databases are optimized to compute.
Bi-encoders vs cross-encoders (the two model types)
The single most useful thing to understand about this library is that it ships two different kinds of model, and they do opposite jobs. Mixing them up is the most common beginner mistake.
Bi-encoder — the embedder (fast, scalable)
A bi-encoder is what we've described so far. It encodes each piece of text independently into its own vector. Because every document can be embedded ahead of time, search at query time is near-instant — you only embed the new query and compare. The tradeoff: the two texts never "see" each other, so the score is a good approximation of similarity, not a perfect one.
Cross-encoder — the reranker (slow, accurate)
A cross-encoder takes both texts at once — the query and one candidate, fed in together — and outputs a single relevance score. Because the model reads them jointly, it judges relevance far more precisely. The catch is cost: there's no reusable vector, so you must run the model fresh for every query–document pair. That's too slow to scan a million documents, but perfect for re-scoring a shortlist.
- Encodes each text alone → a vector
- Embed documents once, up front
- Query time is milliseconds
- Scales to millions of items
- Good — but approximate — ranking
- Reads query + candidate together
- No reusable vector to cache
- Must run per query–document pair
- Only viable on a small shortlist
- Excellent, precise ranking
In practice you use them together in a retrieve-then-rerank pipeline: the fast bi-encoder pulls the top ~50 candidates out of millions, then the slow cross-encoder carefully re-scores just those 50 to surface the best handful. Cheap-and-broad first, expensive-and-precise second — the standard recipe for high-quality search.
Training and fine-tuning your own model
The library isn't only for using pretrained models — it's also the standard tool for training them. If a generic model doesn't understand your domain (medical codes, legal phrasing, internal product names), you can fine-tune one on your own examples and it learns your meaning of "similar."
The core idea is contrastive learning: show the model pairs that should be close and pairs that should be far apart, and it adjusts the vectors to match. Most training data is just one of these shapes:
| Data you have | What it teaches | Typical loss |
|---|---|---|
| Pairs that belong together (question, its answer) | Pull matching pairs close | MultipleNegativesRanking |
| Triplets (anchor, positive, negative) | Closer to the positive than the negative | Triplet loss |
| Pairs with a similarity score (0–1) | Match a known degree of similarity | CosineSimilarity loss |
A pleasant surprise for beginners: the most effective setup is often the simplest. With just lists of matching pairs and MultipleNegativesRankingLoss, every other example in the same training batch is automatically treated as a "negative." You don't have to hand-pick hard negatives to get a strong model — good positive pairs go a long way. The same SentenceTransformerTrainer workflow fine-tunes both bi-encoders and cross-encoders, so once you know one, you know both.
Common pitfalls
- Using a cross-encoder for first-stage search. It has no cached vectors, so running it over your whole corpus per query is brutally slow. Cross-encoders are for reranking a shortlist, never for scanning everything.
- Comparing vectors from two different models. Each model has its own meaning space. Re-embed everything whenever you switch models — an old index plus a new query model produces nonsense scores.
- Ignoring the model's max input length. Models silently truncate text past a token limit, so long documents lose their endings. Split long text into chunks before embedding (the same chunking step RAG uses).
- Forgetting to normalize, then using the wrong distance. If you don't normalize, a raw dot product is skewed by vector length. Either normalize and use dot product, or use cosine similarity directly — just be consistent across indexing and querying.
- Re-embedding on every request. Embed your documents once and store the vectors. Re-encoding a static corpus on each query throws away the entire speed advantage.
Going deeper
Once the basics click, a few directions are worth knowing.
Matryoshka embeddings. Many modern models are trained so you can truncate a vector to fewer dimensions and keep most of its quality — a 768-length vector cut down to 256 still searches well. That saves storage and speeds up search. See Matryoshka embeddings for the idea and its tradeoffs.
Choosing a model is a real decision. Dimensions, max input length, speed, language coverage, and whether the model expects special instruction prefixes all matter. The library exposes all of this through one consistent interface, which is exactly why swapping models is easy — see how to choose an embedding model.
Beyond plain text. The same toolkit extends to multilingual models (where translations of a sentence land near each other) and, increasingly, to multimodal embeddings that place images and text in one shared space. The encode() mental model stays the same; only the inputs change.
Library vs hosted API. Some teams skip self-hosting entirely and call a managed embedding API instead. sentence-transformers is the open, run-it-yourself path: you control the model, run it offline, fine-tune it, and pay no per-call fee — at the cost of managing the compute. Both produce the same kind of vector, and the same retrieve-then-rerank principles apply either way. The honest summary: sentence-transformers is the foundational, evergreen library the rest of the embedding world is taught and built on — start here, and the concepts transfer everywhere.
FAQ
What is the difference between sentence-transformers and BERT?
Plain BERT produces one vector per token and isn't tuned to give a single good "sentence vector" on its own. sentence-transformers (SBERT) adds a pooling step and fine-tuning so each sentence becomes one meaningful, standalone embedding. That lets you embed text once and compare with fast vector math, instead of re-running the model for every comparison.
What does model.encode() return?
It returns a fixed-length numeric vector (an embedding) for each input text, as a NumPy array — for a list of N sentences you get an array of shape [N, dim]. Every text maps to the same number of dimensions regardless of its length, so you can compare any two with cosine similarity or a dot product.
When should I use a cross-encoder instead of a bi-encoder?
Use a bi-encoder (an embedder) for first-stage retrieval, because you can embed all documents in advance and search in milliseconds. Use a cross-encoder (a reranker) only to re-score a small shortlist, where its higher accuracy is worth the cost. The common pipeline uses the bi-encoder to retrieve, then the cross-encoder to rerank.
Do I need a GPU to use sentence-transformers?
No. It runs on CPU and works fine for moderate workloads and one-off encoding. A GPU mainly speeds up embedding very large collections or training your own model; for those it makes a big difference, but a GPU is not required to get started.
Can I train my own embedding model with it?
Yes — that's a core feature. You provide training pairs or triplets, pick a loss such as MultipleNegativesRankingLoss, and fine-tune a pretrained model on your domain. Starting from a strong pretrained model and fine-tuning on a few thousand of your own examples usually beats training from scratch.
Is sentence-transformers free and open source?
Yes. The library is open source (Apache-2.0) and free to use, and many of the embedding and reranker models it loads are openly published. You can run everything locally with no per-call API fees, which is a key reason it's so widely adopted in tutorials and production.