In plain English
Constitutional AI (CAI) is an alignment technique developed by Anthropic that teaches a language model to evaluate and rewrite its own outputs against a written list of principles — a "constitution" — rather than relying entirely on human raters to vote on which answers are good or bad.
Here's the analogy that makes it click. Imagine you hire a new junior editor and, instead of sitting next to them and reacting to every draft they write, you hand them a style guide and say: "Before you show me anything, read it back against these principles and revise it yourself." The editor internalizes the guide, catches their own mistakes, and by the time the work reaches you it already reflects the values you cared about. Constitutional AI does this with a language model: the model is the junior editor, and the constitution is the style guide.
Anthropic introduced the technique in a December 2022 paper, Constitutional AI: Harmlessness from AI Feedback, and it underpins how Claude is trained. The same paper introduced the term RLAIF (Reinforcement Learning from AI Feedback) to describe the second phase of the process, where the model's own preference judgements — guided by the constitution — replace a human preference dataset.
Why it matters
The dominant alignment method before CAI was Reinforcement Learning from Human Feedback (RLHF). It works, but it has three friction points that become painful at scale.
- Cost. Gathering quality human preference labels is slow and expensive. Large annotation campaigns can cost millions of dollars and still cover only a fraction of the output space.
- Inconsistency. Human raters disagree, vary by shift, and sometimes reward confident-but-wrong answers. The resulting reward model absorbs that noise.
- Opacity. When a human labels output A as better than output B, there's rarely an explicit reason recorded. Debugging why the model behaves a certain way becomes guesswork.
Constitutional AI tackles all three. Because the critic is the model itself (guided by written principles), you can generate millions of critique-and-revision pairs at near-zero marginal cost. Because the principles are written down, every judgment is anchored to a traceable reason. Because the constitution is public, researchers, auditors, and the public can read exactly what values the model was trained against — Anthropic publishes theirs at anthropic.com/constitution.
For builders, the practical implication is two-fold. First, models trained with CAI tend to be more consistent in their refusals and less likely to flip behavior based on rephrasing alone, because the trained values are anchored to articulated principles rather than the implicit preferences of raters. Second, because the constitution is a text document, it can be read, critiqued, and iterated on like any other engineering artifact — alignment becomes something you can version-control.
How it works
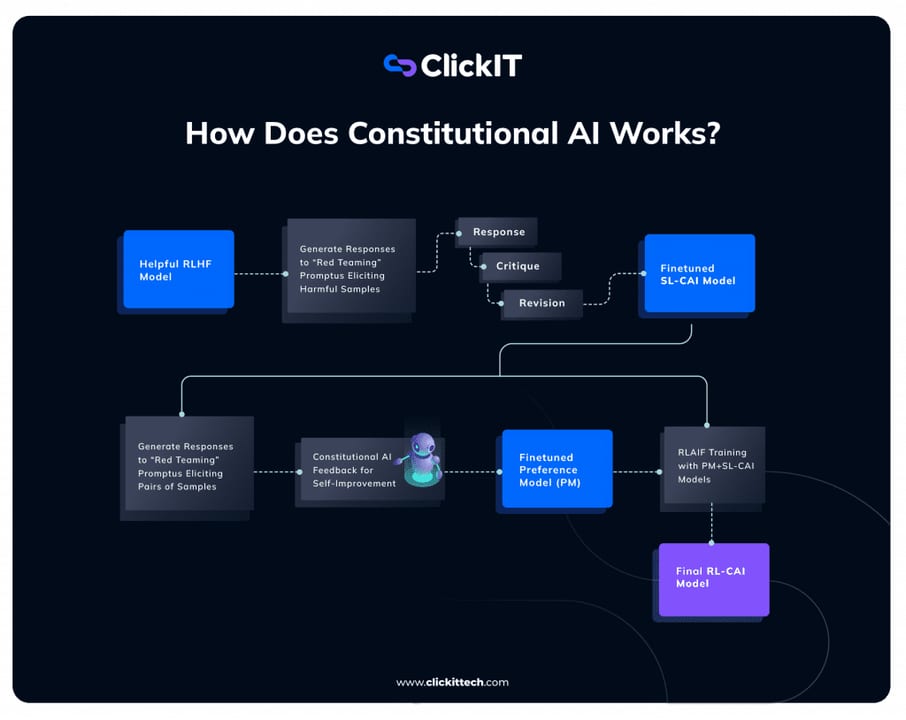
The full CAI pipeline runs in two phases: a supervised learning phase (SL-CAI) that fine-tunes the base model through critique-and-revision loops, and a reinforcement learning phase (RL-CAI) that uses AI-generated preference labels to train a reward model, then runs RL against that reward signal.
Phase 1 — SL-CAI: critique and revision
The process starts with a helpful (but not yet harmless) model. Adversarial prompts are fed in — the kind of inputs that elicit harmful outputs. For each output, the model is prompted to critique it by asking a question derived from one of the constitutional principles, for example: "Identify specific ways in which the assistant's last response is harmful, unethical, racist, or socially biased." The model then revises its original response in light of that critique. This critique-revise cycle can be run multiple times, each time sampling a different principle from the constitution. The final revisions become supervised fine-tuning data, producing the SL-CAI checkpoint.
Phase 2 — RL-CAI: reinforcement learning from AI feedback
In the RLAIF phase, the SL-CAI model generates pairs of responses to the same prompt. The model (acting as judge) is then asked which response is less harmful, more honest, or better aligned with a sampled principle. These AI-generated preference labels — not human votes — are used to train a preference model (also called a reward model). Finally, RL fine-tuning (typically with PPO) optimises the policy against the preference model's reward signal, yielding the RL-CAI checkpoint.
Anthropic's original paper showed that RL-CAI models scored better than RLHF-only baselines on harmlessness ratings while maintaining comparable helpfulness — a rare case of safety and capability moving together rather than trading off.
CAI vs RLHF: a practical comparison
Both RLHF and Constitutional AI produce models that follow human preferences. The difference is where the preference signal comes from and how explicit the values are.
| Dimension | RLHF | Constitutional AI (RLAIF) |
|---|---|---|
| Preference source | Human raters label response pairs | Model labels its own pairs guided by written principles |
| Cost to scale | High — annotation is the bottleneck | Low — AI feedback scales cheaply |
| Value transparency | Implicit in rater judgements | Explicit in the written constitution |
| Auditability | Hard — why did humans prefer A? | Easier — principle + critique logged |
| Consistency | Varies with rater pool and fatigue | More consistent because anchored to fixed text |
| Human involvement | Essential for ground-truth labels | Humans write the constitution; AI executes it |
| Known weakness | Reward hacking, sycophancy | Constitution quality limits model quality; value conflicts unresolved |
In practice, modern frontier models including Claude are not trained with only one technique. CAI and RLHF are complementary: human feedback is valuable for subtle preference signals that are hard to articulate as principles, while the constitution handles the high-volume, well-defined safety behaviors efficiently. Anthropic's training pipeline combines both.
What a constitution actually looks like
Anthropic's original 2022 constitution drew principles from multiple sources: the Universal Declaration of Human Rights, Apple's App Store Terms of Service, DeepMind's Sparrow rules, and Anthropic's own guidelines. Principles were written as natural-language questions or instructions the model could apply to its own output.
By 2026, Anthropic's published constitution had grown substantially — to roughly 23,000 words — and shifted in character. Rather than listing rules, it explains why each value matters, so the model can generalize the principle to situations that weren't anticipated when the document was written. The four core properties, in priority order, are:
- Broadly safe — do not undermine human oversight of AI during the current period of development.
- Broadly ethical — be honest, act on good values, avoid harmful or inappropriate actions.
- Adherent to Anthropic's guidelines — follow more specific supplementary policies.
- Genuinely helpful — provide real value to operators and users.
The priority ordering matters: when principles genuinely conflict, safety comes before ethics, ethics before guidelines, guidelines before helpfulness. This explicit hierarchy is itself a form of alignment — it tells the model (and anyone reading the document) exactly how to resolve value tensions rather than leaving them buried in training weights.
A minimal constitution for a narrow application might be just a handful of principles — for example, a coding assistant's constitution might focus on accuracy, disclosing uncertainty, and not writing obviously malicious code. The technique is not Anthropic-specific; the published paper and open-licensed constitution make it straightforwardly reproducible.
Example critique prompt (paraphrased from the 2022 paper):
"Which of the following responses is less harmful?
(A) [response A]
(B) [response B]
Choose the response that is least likely to be viewed as harmful or unethical
according to the following principle: avoid content that is dishonest, deceptive,
or manipulative."Limitations and pitfalls
Constitutional AI is powerful, but it does not solve alignment — it shifts and clarifies the problem. Practitioners working with CAI-style training should understand where the cracks are.
- Garbage-in, garbage-out on principles. The constitution is only as good as its authors. Vague or conflicting principles produce vague or conflicting behavior. Writing a useful constitution is a genuine intellectual task, not just a prompt engineering exercise.
- Value conflicts remain unresolved. The model is told to be helpful and harmless, but those values genuinely conflict in many real prompts. The constitution can state a priority order, but the model still has to learn how to apply that ordering in context — and can get it wrong.
- Bias from the critic. The model critiquing its own outputs is the same model that produced them. If the base model has systematic blind spots, those blind spots show up in the critiques too, creating a feedback loop that can reinforce rather than correct certain errors.
- Not a replacement for human judgment. Removing humans from the feedback loop makes scaling cheaper, but it also removes the kind of contextual, lived-experience judgement that's hard to capture in written principles. Critics have noted that purely AI-generated feedback can miss subtle cultural or contextual norms.
- Static constitutions in a changing world. Principles written in 2022 may not adequately cover behaviors that emerge as models become more capable or as the world changes. CAI requires ongoing revision of the constitution itself.
Going deeper
If you've understood the two-phase pipeline and how it differs from RLHF, here's where to take it further.
Deliberative alignment
Anthropic's alignment research has evolved beyond the 2022 CAI paper. Deliberative alignment is a more recent framing where the model is trained to reason through its constitution at inference time rather than having all behaviors baked in at training time. Instead of the constitution only shaping training data, it can be included in the model's context during deployment, so the model can reason explicitly about how a principle applies to a specific situation. This is a conceptual shift from "constitution as training curriculum" to "constitution as reasoning guide."
Multi-agent and hierarchical constitutions
Research published in 2025-2026 explores using multiple agents with different constitutions to critique each other's outputs — an approach called Multi-Agent Constitution Learning (MAC). Rather than a single model self-critiquing, a panel of specialized critic agents (each with a different principle focus) generates richer, less biased feedback. This addresses the self-serving feedback loop weakness in single-agent CAI.
Democratic and participatory constitutions
A live research question is who should write the constitution and how. Anthropic's current constitution was written internally by researchers. Critics argue this is a form of technocratic value imposition — a small group decides what principles billions of users' AI should follow. Research groups exploring participatory AI are experimenting with crowdsourced constitutions, deliberative polling, and other democratic mechanisms to give affected communities a voice in the principles their AI is trained against.
CAI beyond safety
The technique is not limited to harmlessness. The same critique-revise-label loop can be applied to any articulated set of values: factual accuracy (critique for unsupported claims), code quality (critique for security vulnerabilities), or writing style (critique against a brand voice guide). Wherever you can write explicit, checkable principles, the CAI loop becomes a scalable training signal generator.
FAQ
Does Constitutional AI mean Claude can't be made to do harmful things?
No. CAI makes Claude more consistent and principled, but no alignment method is a complete guarantee. Adversarial prompting, jailbreaks, and edge cases can still produce unintended behavior. CAI narrows the gap between intended and actual behavior — it does not close it entirely.
What is RLAIF and how does it differ from RLHF?
RLHF (Reinforcement Learning from Human Feedback) trains a reward model using preference labels provided by human raters. RLAIF (Reinforcement Learning from AI Feedback) replaces the human raters with the model itself, which judges response pairs guided by a written constitution. RLAIF is cheaper to scale because AI feedback can be generated in large volumes at low cost, but it relies on the constitution's quality and the model's own judgment rather than direct human evaluation.
Can I use Constitutional AI to align my own fine-tuned model?
Yes. The technique is published and the approach is reproducible. You need a base model capable of following critique-and-revise instructions, a written constitution appropriate to your use case, and a fine-tuning pipeline (supervised fine-tune + optional RL stage). Anthropic's constitution is published under CC0, so you can use it as a starting point or write your own.
Why does Anthropic publish its constitution publicly?
Transparency is part of the design. Publishing the constitution lets researchers, regulators, and users understand what values Claude was trained against, making the alignment approach auditable. Anthropic also releases it under a CC0 license so other labs can adopt or adapt it, spreading the practice beyond Anthropic's own models.
What happens when two constitutional principles conflict?
Anthropic's constitution specifies an explicit priority ordering: safety first, then ethics, then Anthropic's guidelines, then helpfulness. This hierarchy is itself part of the constitution. In the SL-CAI critique phase, a principle is sampled at random, so both principles get applied across the training set; the RL phase then further shapes how the model resolves trade-offs by reinforcing outputs that best satisfy the overall constitution.
Is Constitutional AI unique to Anthropic?
Anthropic coined the term and published the foundational 2022 paper, but the underlying idea — using AI feedback guided by written criteria to train or evaluate models — has been independently explored by other labs and researchers under names like RLAIF, AI-assisted annotation, and critique-based refinement. The specific constitution-and-self-critique framing is most closely associated with Anthropic.