In plain English
When you wire up an LLM judge, you face an immediate fork in the road: do you hand it two answers and ask which one wins, or do you hand it one answer and ask how good it is? Those two designs go by different names — pairwise comparison and rubric scoring (also called pointwise evaluation) — and the choice shapes what your scores actually measure.
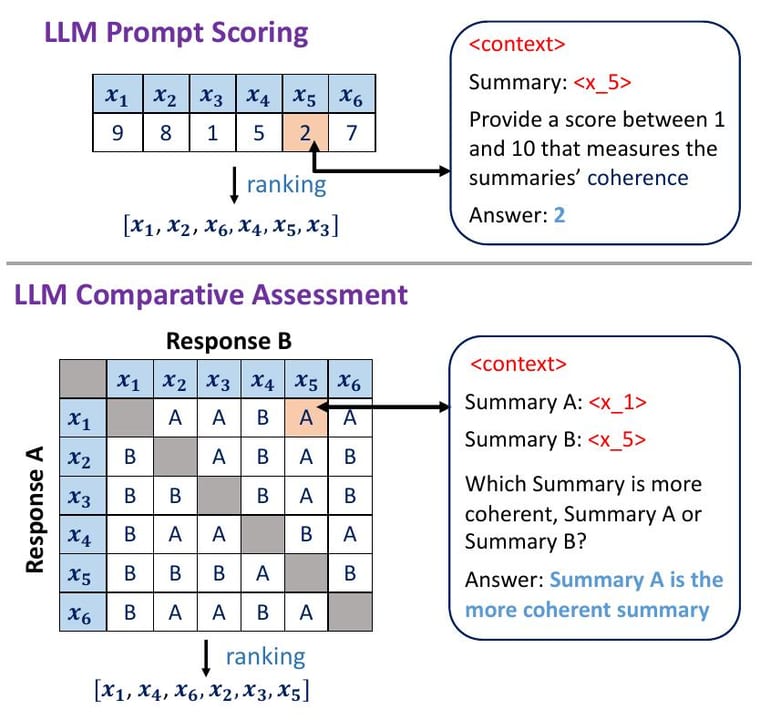
Think of how awards ceremonies work. Film critics use both modes all the time. When the nominees are announced and a critic picks the best picture, that is pairwise (relative) thinking: "compared to the others, this one wins." When a reviewer writes a four-star review of a single film, that is rubric (absolute) thinking: "against my internal standard for what a great film looks like, this scores four out of five." Neither mode is wrong — they just answer different questions.
LLM judges work the same way. Pairwise presents the judge with a prompt and two candidate responses and asks: "which answer is better, A or B?" Rubric scoring presents the judge with a single prompt-response pair and a grading rubric and asks: "rate this answer on clarity, correctness, and tone — return a score from 1 to 5." The mechanics, the biases, the costs, and the questions each can answer are all different. Getting the pattern right is as important as writing a good rubric.
Why it matters
Most teams that reach for an LLM judge are trying to answer one of two practical questions. The first is a comparison question: "Is this new prompt better than the old one?" or "Does model B outperform model A on our task?" The second is a quality question: "Is this individual response good enough to show the user?" or "Did our output regress on helpfulness this week?" These questions need different judge designs, and using the wrong one gives you noisy, misleading signal.
Choosing pairwise when you actually need absolute quality is a common mistake. Pairwise can tell you that response A beats response B, but it cannot tell you that both are terrible — the winner is just the less-bad option. Conversely, using a single rubric score when you just need to pick between two model versions is expensive and fragile, because 1-to-5 scales are notoriously hard for models to calibrate consistently. Scale drift — where the same judge gives the same answer a "3" today and a "4" next week — erodes any longitudinal comparison you try to make.
The stakes go beyond analysis. If your judge feeds a training loop — generating preference data for fine-tuning or RLHF — the wrong pattern can introduce systematic bias into the model itself. A rubric that drifts will produce inconsistent preference labels; a pairwise judge that ignores absolute quality will train the model to "sound like a winner" rather than "be correct." Understanding the tradeoffs lets you match the pattern to the task rather than hoping it works.
Who needs to care about this choice
- Prompt engineers running A/B tests — pairwise is the right tool, but you need to know its position-bias failure mode first.
- Teams shipping eval dashboards — rubric scoring scales linearly and gives you per-criterion breakdowns, but you must manage scale drift over time.
- ML engineers training reward models — the judge pattern you pick for preference labeling directly shapes what the trained model optimizes for.
- Product owners setting quality gates — rubric scoring with an explicit pass/fail threshold is the only way to enforce an absolute floor.
How it works
Let's look at the mechanical shape of each pattern before comparing them.
Pairwise comparison
In a pairwise call, you construct a single prompt that includes the original user input plus both candidate responses. The judge reads all three, reasons about which response better satisfies the user's need, and returns a verdict: A, B, or tie. The prompt typically asks for brief reasoning before the verdict so the judgment is auditable. The output is categorical, not numerical.
Because relative comparisons are easier than absolute ones — the judge can directly contrast the two answers rather than applying an internal standard — pairwise verdicts are generally more stable and correlate better with human preferences. Research on MT-Bench found that strong pairwise judges agreed with humans over 80% of the time on general-purpose comparisons.
Rubric scoring (pointwise)
In a rubric call, you submit a single prompt-response pair alongside an explicit rubric — a numbered scale with a plain-English description of what each level means. The judge reads the response, applies the rubric, and returns a score (e.g., 1–5) plus a reason. The key engineering choice is whether you score holistically (one composite score) or analytically (separate scores per criterion, like correctness, clarity, and tone). Analytic rubrics are more expensive but reveal which dimension degraded, making them far more useful for debugging.
Rubric scoring scales linearly — grading 1,000 responses costs 1,000 judge calls. Pairwise grows differently: grading every pair of N responses is O(N²) comparisons. If you have 100 candidate model outputs and want a full pairwise ranking, that's up to 4,950 judge calls. In practice, teams use tournament brackets or Elo-style sampling to keep pairwise tractable at scale.
- Input: 2 responses + prompt
- Output: A / B / tie
- Stable relative judgment
- Scales as O(N²) comparisons
- Position bias is a real risk
- No absolute quality floor
- Input: 1 response + rubric
- Output: numeric score
- Absolute quality gate possible
- Scales as O(N) calls
- Scale drift between runs
- Per-criterion diagnostic detail
Biases and failure modes
Each pattern has its own dominant failure mode. Knowing them upfront lets you design defenses before they cost you.
Position bias in pairwise
In pairwise evaluation, position bias means the judge systematically favors whichever candidate appears first (or second) in the prompt — not because it read the content more carefully, but because of where it sat. Measurements on GPT-4 found it changed its preferred answer when the order was swapped on roughly a third of cases in MT-Bench experiments. The standard mitigation is swap augmentation: run every comparison twice, once in A-B order and once in B-A order. Accept the verdict only when both orderings agree. This doubles your inference cost, but it is not optional if you want clean signal.
A related problem is verbosity bias — the judge preferring longer answers regardless of quality. This has been measured at 15 to 30 points of inflated preference for longer outputs across multiple frontier models. Explicitly instruct the rubric to penalize padding, and if your task rewards conciseness, say so in the system prompt.
Scale drift in rubric scoring
With rubric scoring, the dominant failure mode is scale drift: a "4" today means something different from a "4" three weeks from now, especially when you upgrade the judge model or tweak the rubric wording. Scale drift is insidious because your dashboard looks stable — scores hover around 3.8 — but the underlying meaning has shifted. Two defenses help. First, anchor each scale level with a short worked example in the rubric; a judge that must match its score to an example drifts far less. Second, run a small calibration set — a fixed set of human-labeled examples — on every judge version and track score drift against those anchors.
Self-preference bias in both patterns
Both patterns suffer from self-preference bias: a GPT-family judge tends to rate GPT-family outputs higher, and a Claude-family judge tends to favor Claude-family outputs. This is especially damaging when you use the same model for generation and grading. When you can, use a judge from a different model family than the one you are evaluating. Prometheus-2, an open-source judge model fine-tuned specifically for evaluation tasks, is one alternative that avoids vendor-alignment bias and supports both pairwise and direct-assessment modes.
| Bias | Affects | Mitigation |
|---|---|---|
| Position bias | Pairwise only | Swap A/B order; only count consistent verdicts |
| Verbosity bias | Both patterns | Penalize padding in rubric; prefer pairwise |
| Scale drift | Rubric scoring | Anchor scale with worked examples; calibration set |
| Self-preference | Both patterns | Use a different model family for judging |
| Sycophancy | Both patterns | Demand evidence in rubric; grade faithfulness not tone |
When to use which pattern
The patterns are complementary, not competing. Most mature eval pipelines use both. The practical question is which one to reach for first in a given situation.
Reach for pairwise when...
- You are comparing two specific versions — a new prompt vs. the old one, model A vs. model B. Pairwise is the most reliable signal here because relative judgment is easier and more stable than absolute.
- The quality difference is subtle — pairwise grounds each judgment in a concrete contrast, which helps the judge distinguish answers that are close in quality.
- You are building a leaderboard — Chatbot Arena and AlpacaEval 2 both use pairwise comparisons aggregated via Elo or win-rate because they are ranking, not measuring absolute quality.
- You do not have a well-defined rubric yet — it is easier to collect pairwise preferences and derive rubric dimensions from them than to build a rubric from scratch.
Reach for rubric scoring when...
- You need an absolute quality gate — pairwise has no floor; the winner could still be unacceptable. If you need to block responses below a quality threshold, only a rubric score can enforce that.
- You are monitoring production over time — rubric scores produce time-series data you can plot. Pairwise win rates require a fixed baseline to compare against, which gets stale.
- You need to debug which dimension regressed — analytic rubrics return per-criterion scores. If your assistant's helpfulness dropped but its safety tone improved, a rubric shows you exactly where the shift happened.
- You are grading at large scale — one response per call is O(N); pairwise is O(N²). For 10,000 production responses a day, rubric scoring is the only tractable option.
- You want to feed a training signal — reward models and RLHF pipelines need scalar scores, not categorical win/loss labels.
Reference-based scoring: a third option
Both patterns have a reference-based variant where the judge receives a known-good gold answer in addition to the candidate. In pairwise, the gold answer acts as one of the two candidates; in rubric scoring, the judge is asked to score the candidate relative to the reference. Reference-based judging is significantly more stable than reference-free judging because the gold answer anchors the scale and prevents both drift and self-preference. The cost is that you need a golden dataset — curated, human-verified examples — which is not always feasible for production tasks.
Going deeper
Once you are comfortable with the basic patterns, several advanced considerations push judge reliability further.
Hybrid and multi-stage judging
Some pipelines chain the patterns. A common design is to use a rubric pass first to filter responses that clearly fail (score below a threshold), then apply pairwise comparison only to the responses that pass. This preserves the stability of pairwise while staying tractable — you only compare the candidates that cleared the quality floor. MT-Bench uses a variation of this: GPT-4 scores each response on a 10-point scale, and those scores are then used to rank models without running all pairs head-to-head.
Pairwise intransitivity and Elo aggregation
Pairwise results are not always transitive: A beats B, B beats C, but C beats A. This is common when the candidates are close in quality or have complementary strengths. Sorting N items by pairwise comparison is at best O(N log N) when comparisons are consistent — but with LLM judges, intransitivity means you cannot always guarantee a clean linear ranking. Chatbot Arena solves this with an Elo rating system that tolerates non-transitivity by treating each comparison as a match and updating ratings incrementally. If you are building a pairwise leaderboard, Elo or Bradley-Terry models are more robust than trying to derive a total order.
Dynamic rubric generation
Static rubrics — the same criteria applied to every prompt — miss quality dimensions that are task-specific. Recent work on dynamic rubric generation (including from Prometheus-2 and follow-on research) generates rubric criteria per-prompt: the judge first infers what a good answer to this specific input would need to do, writes a customized rubric, then scores against it. This trades rubric consistency for per-task precision. For highly varied pipelines — general-purpose assistants, coding assistants that handle both explanation and debugging — dynamic rubrics correlate better with human preference than a single fixed rubric applied uniformly.
Calibrating against human labels
No matter which pattern you use, validate the judge against human labels before trusting its output. Collect 100 to 200 human-labeled examples, run the judge on the same set, and measure agreement with Cohen's kappa or simple percent agreement. For pairwise, track what fraction of human A-B preferences the judge replicates. For rubric scoring, check correlation between judge scores and human ratings. Prometheus-2 (8x7B) achieved Pearson correlations of 0.6 to 0.7 with GPT-4 on 5-point Likert scales and 72 to 85% agreement with human judgments on pairwise ranking benchmarks — useful baselines when setting expectations for your own judge. Re-run calibration whenever you upgrade the judge model, revise the rubric, or shift to a new task domain.
Structuring judge output for reliability
Both patterns benefit from two structural choices that are easy to implement and reliably improve accuracy. First, ask the judge to reason before scoring — chain-of-thought before the verdict forces the model to ground the score in specifics and makes the judgment auditable. Second, require structured output (JSON) so your code never parses free text. A pairwise call might return {"reasoning": "...", "winner": "A"} and a rubric call might return {"reasoning": "...", "scores": {"correctness": 4, "clarity": 3, "tone": 5}}. Structured output combined with temperature=0 is the minimum viable reliability setup for any production judge.
import json
from anthropic import Anthropic
client = Anthropic()
PAIRWISE_PROMPT = """You are an impartial evaluator.
Given a USER PROMPT and two candidate responses (A and B),
decide which response better satisfies the user's need.
First write one sentence of reasoning. Then return ONLY JSON:
{"reasoning": "...", "winner": "A" | "B" | "tie"}"""
def judge_pair(prompt: str, a: str, b: str) -> dict:
msg = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=300,
temperature=0,
messages=[{"role": "user", "content":
f"{PAIRWISE_PROMPT}\n\nUSER PROMPT: {prompt}"
f"\n\nRESPONSE A: {a}\n\nRESPONSE B: {b}"}],
)
return json.loads(msg.content[0].text)
def swap_augmented_judge(prompt: str, a: str, b: str) -> str:
"""Run both A-B and B-A; only trust consistent verdicts."""
ab = judge_pair(prompt, a, b)
ba = judge_pair(prompt, b, a) # swapped order
# Normalize the B-A result back to A-B perspective
swap_map = {"A": "B", "B": "A", "tie": "tie"}
ba_normalized = swap_map[ba["winner"]]
if ab["winner"] == ba_normalized:
return ab["winner"] # consistent verdict
return "tie" # inconsistent = call it a tie
winner = swap_augmented_judge(
prompt="Explain backpropagation simply.",
a="Backprop computes gradients layer by layer using the chain rule.",
b="Backpropagation is a complex algorithm used in deep learning.",
)
print(winner) # "A"FAQ
Which is more accurate — pairwise comparison or rubric scoring for LLM evaluation?
Pairwise comparison tends to be more stable because relative judgments are easier for models to make than absolute ones. However, rubric scoring can be more precise when the rubric is well-calibrated with worked examples. The right choice depends on whether you need a relative ranking or an absolute quality measurement — for A/B tests, pairwise wins; for production monitoring, rubric scoring is more practical.
How do I prevent position bias when using a pairwise LLM judge?
Use swap augmentation: run the comparison twice with the candidate order reversed (A-B then B-A). Only accept the verdict when both orderings agree; count inconsistent pairs as ties. This doubles inference cost but is the standard mitigation because position bias has been measured at 10 to 15 percentage points in frontier models.
What is scale drift in rubric scoring and how do I fix it?
Scale drift means the same response receives different scores across judge runs — a "4" today becomes a "3" next week without any real quality change. Fix it by anchoring each scale level in the rubric with a brief worked example, maintaining a calibration set of human-labeled responses you re-score on every judge update, and treating large score shifts as a signal to re-validate rather than a quality finding.
Can I use both pairwise and rubric scoring in the same evaluation pipeline?
Yes — and most mature teams do. A common pattern is rubric scoring for the daily quality dashboard (linear cost, per-criterion detail) and pairwise comparison for release-gate decisions ("did this change actually improve things?"). You can also chain them: rubric scores filter out clearly failing responses, then pairwise comparison ranks the rest.
Why can't I just use pairwise scoring to check if a response is good enough to show users?
Pairwise comparison has no absolute floor — it only tells you which of two candidates is better, not whether either one meets a minimum standard. If both candidates are bad, pairwise will still pick a winner. For quality gates ("block responses below threshold X"), you need rubric scoring with an explicit minimum score.
What is Prometheus-2 and why is it relevant to choosing a judge pattern?
Prometheus-2 is an open-source LLM (7B and 8x7B variants, released May 2024) fine-tuned specifically for evaluation tasks. It supports both direct assessment (rubric scoring) and pairwise ranking in a single model, achieves 0.6 to 0.7 Pearson correlation with GPT-4 on 5-point scales, and avoids the vendor self-preference bias you get when using a proprietary judge to grade its own family's outputs.