In plain English
When you ask a language model to "reply with JSON," it usually does — usually. Most of the time you get clean JSON, but every so often the model wraps it in a code fence, adds a chatty "Sure, here you go!" before it, renames a field, drops a required key, or returns a number where you expected a string. Your code then tries to parse that text, throws an error, and the whole request fails. At small scale you shrug; at thousands of calls a day, those rare failures become a constant headache.
OpenAI Structured Outputs removes that whole class of problem. Instead of asking nicely in the prompt and hoping, you hand the API a JSON Schema — a formal description of the exact shape you want — and the model is forced to produce output that matches it. You set response_format to a json_schema with strict: true, and the response is guaranteed to be valid JSON that conforms to your schema. No stray prose, no missing fields, no surprise types.
Think of the difference between asking a new hire to "fill out the form however you like" versus handing them a paper form with labelled boxes and no room to write outside the lines. In the first case you get creative, inconsistent answers you have to clean up. In the second, every answer lands in the right box because there is physically nowhere else for it to go. Structured Outputs is that pre-printed form: the model can only write inside the boxes your schema defines.
Why it matters
Modern apps rarely want a chatty paragraph from a model — they want data. You extract fields from an invoice, classify a support ticket, pull structured arguments for a database query, or generate the inputs to another program. In every one of these, the model's output is not the final product; it is a step that feeds the next line of code. And code needs predictable shapes.
Before schema enforcement existed, teams built a fragile ritual around every "give me JSON" call:
- Beg in the prompt. Add lines like "Respond ONLY with valid JSON, no markdown, no explanation." This helps, but never reaches 100%.
- Strip the junk. Write regex to peel off code fences and leading prose before parsing.
- Try, catch, repair. Wrap the parse in a try/catch, and on failure send the broken output back to the model asking it to fix itself — an extra call that costs money and time.
- Validate by hand. Even after parsing, re-check that every required field is present and every type is correct, because "valid JSON" is not the same as "the JSON I asked for."
Structured Outputs collapses that entire pipeline into one guarantee enforced by the provider. When the API itself promises the output matches your schema, you can delete the strip-repair-revalidate code and parse straight into a typed object. Fewer moving parts means fewer bugs, lower latency (no repair round-trips), and lower cost (no wasted retry calls).
The deeper point is where the guarantee lives. A prompt instruction is a request the model may or may not honour. Provider-level enforcement is a constraint applied while the text is being generated — the model is not free to break it. That shift, from hoping to guaranteeing, is what makes Structured Outputs worth reaching for in any production system that consumes model output as data.
How it works
The magic is not in the prompt — it is in how the model picks each token. A language model generates text one token at a time, each time choosing from its whole vocabulary. Structured Outputs adds a gatekeeper to that loop: at every step it looks at the JSON produced so far, works out which next tokens could still lead to a schema-valid result, and blocks all the others. The model can only ever choose a token that keeps the output on a path your schema allows. This technique is called constrained decoding.
Because the schema is enforced during generation rather than checked after, an invalid response is not something the API has to retry — it is something it cannot produce in the first place. That is the core difference from prompt-only approaches.
What you actually send
You attach a response_format of type json_schema to your request, give it a name, set strict: true, and include the JSON Schema describing your object. Here is a compact example that extracts a person's details from free text:
from openai import OpenAI
client = OpenAI()
schema = {
"type": "object",
"properties": {
"name": {"type": "string"},
"age": {"type": "integer"},
"role": {"type": "string", "enum": ["engineer", "designer", "manager"]},
},
"required": ["name", "age", "role"],
"additionalProperties": False,
}
resp = client.chat.completions.create(
model="<a-model-that-supports-structured-outputs>",
messages=[
{"role": "system", "content": "Extract the person's details."},
{"role": "user", "content": "Dana is a 34-year-old product designer."},
],
response_format={
"type": "json_schema",
"json_schema": {
"name": "person",
"strict": True,
"schema": schema,
},
},
)
# Guaranteed to be JSON matching `schema` — parse it directly.
import json
person = json.loads(resp.choices[0].message.content)
print(person["role"]) # one of: engineer | designer | managerTwo fields do the heavy lifting. strict: true is what turns on real enforcement — without it you are back to a hint. "additionalProperties": false tells the schema that no keys beyond the ones you listed are allowed, which is what stops the model from inventing extra fields. In strict mode the provider typically expects every property to be listed in required too; to make a field optional you give it a type that also allows null rather than leaving it out.
Structured Outputs vs JSON mode vs prompt-only
Three approaches all claim to "get JSON out of the model," and beginners constantly mix them up. They offer very different levels of guarantee.
| Approach | What it guarantees | Catches a wrong shape? | When to use |
|---|---|---|---|
| Prompt-only ("reply in JSON") | Nothing — it is a polite request | No | Quick experiments, models without native support |
| JSON mode | Output is syntactically valid JSON | No — any valid JSON passes | You need parseable JSON but the shape can vary |
| Structured Outputs (strict schema) | Output is valid JSON and matches your exact schema | Yes — wrong shapes cannot be produced | Production data extraction, tool arguments, typed pipelines |
The jump from JSON mode to Structured Outputs is the important one. JSON mode promises the response will parse, but says nothing about its contents: {}, {"foo": 1}, and your intended object all satisfy it equally. You still have to validate the shape yourself. Structured Outputs folds that validation into the generation itself, so a response that parses is also, by construction, a response that fits.
- Guarantee lives in your wording
- Model may ignore it
- You strip + repair + validate
- Failures appear at runtime
- Provider guarantees valid syntax
- Shape is still up to the model
- You validate the shape yourself
- Wrong fields slip through
- Provider guarantees the schema
- Wrong shapes can't be generated
- Parse straight into a type
- No repair, no revalidation
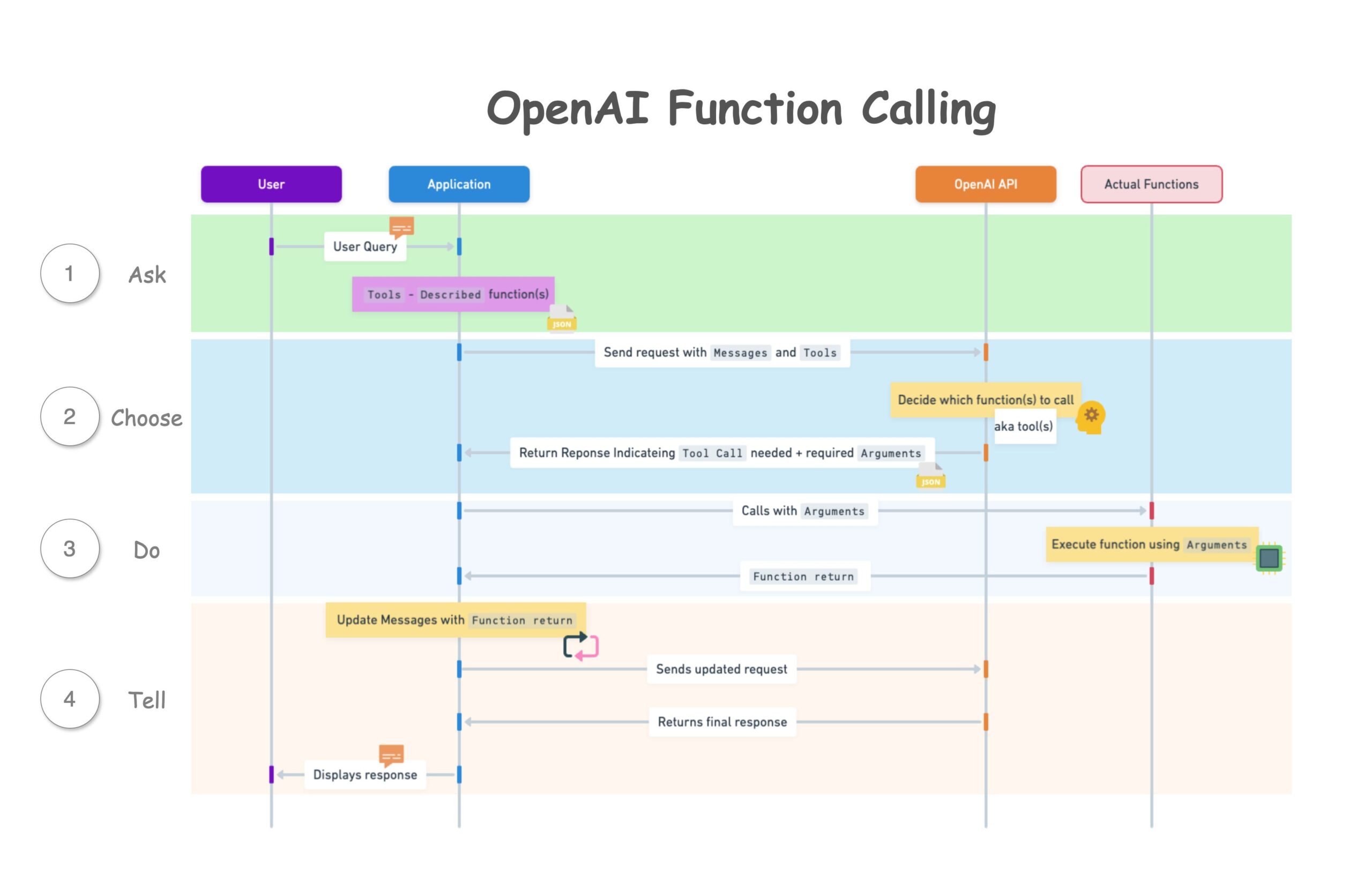
How it relates to function and tool calling
If you have used function calling (also called tool calling), Structured Outputs will feel familiar — they share the same machinery. When you define a tool, you describe its arguments with a JSON Schema, and the model returns a JSON object of arguments for you to run. That argument object is exactly the kind of structured data this feature constrains.
The useful distinction is intent, not mechanism:
- Tool calling answers "which action should I take, and with what arguments?" The model may choose to call a tool, call several, or none. You are giving it capabilities and letting it decide.
- Structured Outputs answers "give me this one object back, shaped like this." There is no action to take — you simply want the model's reply itself to be a typed object you can consume directly.
Under the hood, strict schema enforcement can apply in both places: you can mark a tool's parameters as strict so the arguments are guaranteed valid, and you can use response_format so the final answer is guaranteed valid. Same constrained-decoding engine, pointed at two different parts of the conversation. Pick response_format when you want the response to be the data; pick tool calling when you want the model to do something and hand you the parameters for it.
Common pitfalls and practical tips
Schema enforcement removes malformed output, but it cannot make output correct. A few traps catch people moving from prompt-only JSON to strict schemas.
- Valid is not the same as accurate. The model is guaranteed to fill every field with a value of the right type — but it can still fill them with wrong values. If the source text never mentions an age, the model must still emit some integer for a required
agefield. Make genuinely-unknown fields nullable so the model has an honest way to say "not present." - Forgetting
additionalProperties: false. Without it, the model is free to add keys you did not ask for. Set it on every object you want locked down. - Over-deep or exotic schemas. Strict mode supports a large but not unlimited slice of JSON Schema, and providers cap nesting depth and total properties. Very deep or feature-heavy schemas may be rejected — keep them as flat and plain as the task allows.
- Relying on it for safety. A schema controls shape, not content. Retrieved or user-supplied text inside your prompt can still carry prompt injection; a valid-looking object can still contain a harmful or fabricated value. Treat the data, validate the meaning.
Going deeper
Once the basics click, a few subtleties separate a demo from a robust integration.
Strict mode supports a subset of JSON Schema. Not every keyword you might reach for is honoured under strict enforcement. Common, well-supported building blocks — objects, arrays, strings, numbers, booleans, enum, and unions expressed with nullable types — cover most real needs. More advanced validation constructs may be ignored or rejected, so check the docs before leaning on an exotic keyword, and prefer plain shapes that map cleanly onto the data you actually want.
Refusals still exist. Schema enforcement does not override the model's safety behaviour. If a request is refused, the response will not be your object but a refusal — your code should detect that case (the SDKs surface it explicitly) rather than assuming every successful call yields schema-shaped data.
It composes with streaming. You can stream a structured response token by token and still end with schema-valid JSON, because the constraint is applied as each token is produced. That lets a UI render fields as they arrive while the final object remains guaranteed-valid — handy for long objects where you do not want to wait for the whole response.
The same idea generalises beyond JSON. Constrained decoding is a general technique: a grammar can pin output to any formal language, not only JSON Schema. Provider-native Structured Outputs is the most polished, batteries-included expression of it, while inference-level grammar engines bring the same guarantee to self-hosted models. If you understand why enforcing structure during decoding beats checking it afterwards, you understand the whole family — see function calling for the closely related tool-argument case, and forcing tool use for steering when the model produces structured calls at all.
FAQ
What is the difference between OpenAI Structured Outputs and JSON mode?
JSON mode only guarantees the output is syntactically valid JSON — any valid object passes, even an empty one. Structured Outputs (strict json_schema) goes further and guarantees the output also matches your exact schema: the right fields, the right types, nothing extra. JSON mode catches broken syntax; Structured Outputs catches the wrong shape.
How do I make a field optional with strict Structured Outputs?
In strict mode the provider generally expects every property to appear in the required list, so you cannot simply omit a field. Instead, make its type allow null (for example a union of string and null) and keep it required. The model can then return null to signal "not present" while the schema stays satisfied.
Does Structured Outputs guarantee the answer is correct?
No. It guarantees the output is valid JSON in your exact shape — the right fields with the right types. It does not guarantee the values are accurate. The model can still put a wrong or invented value into a correctly-typed field, so you should still sanity-check the contents for anything important.
Is Structured Outputs the same as function calling?
They share the same schema-enforcement machinery but serve different goals. Function (tool) calling decides which action to take and produces its arguments as structured JSON. Structured Outputs makes the model's final response itself a typed object. Use tool calling to make the model do something; use Structured Outputs when you want the reply to be the data.
Do I need to write the JSON Schema by hand?
Usually not. The official SDKs let you define the shape as a typed model — a Pydantic class in Python or a Zod schema in TypeScript — and they generate the JSON Schema and parse the response back into that type for you, giving end-to-end type safety with very little boilerplate.
Why does Structured Outputs need additionalProperties set to false?
Setting "additionalProperties": false on an object tells the schema that no keys beyond the ones you listed are allowed. Without it, the model is free to add extra fields you never asked for. Strict mode typically requires it so the output shape is fully locked down.