In plain English
When you send a message to an AI chatbot, nothing happens for a moment — and then words start appearing. Time to First Token (TTFT) is the duration of that silence: the milliseconds between the moment your request leaves the client and the moment the very first character of the response arrives.
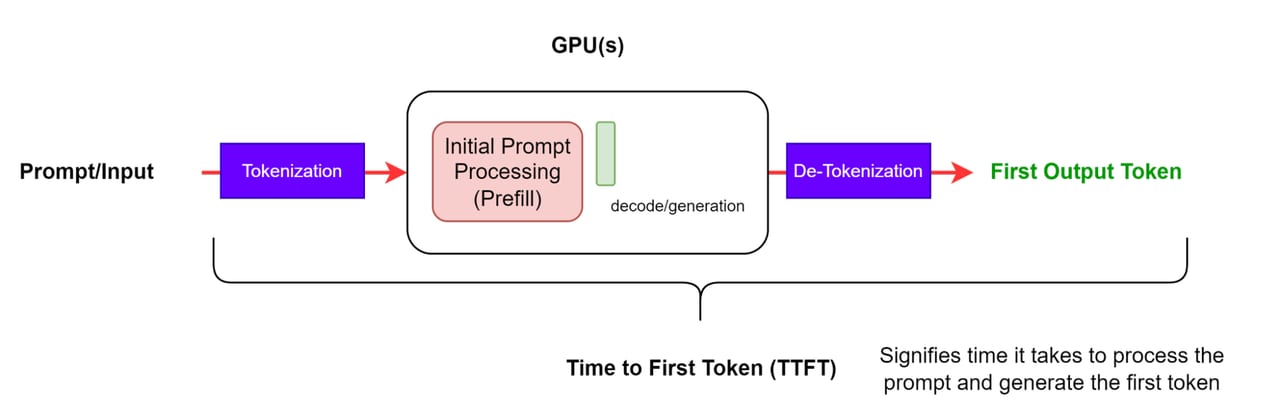
Think of it like ordering food at a restaurant. TTFT is the wait between placing your order and the first dish touching the table. Once that first plate arrives you know the kitchen is working. Tokens per second (TPS) is how fast the dishes keep coming after that. And total latency is the full time from sitting down to the last bite. All three numbers tell you something different about your experience.
Concretely, an LLM inference request moves through two back-to-back phases: a prefill phase where the model reads your entire prompt at once, and a decode phase where it generates the reply one token at a time. TTFT is dominated by the prefill phase. TPS is a measure of decode speed. Total latency adds them together.
Why it matters
Not every latency metric matters equally for every product. The right one to optimize depends on what your users are actually waiting for.
TTFT drives perceived responsiveness
For interactive products — chatbots, coding assistants, voice interfaces — users form their first impression during the silent gap before the first token arrives. Research from Microsoft's Azure AI team shows that once the first token appears, users shift their cognitive attention from "is it working?" to "what is it saying?", dramatically reducing perceived wait time. A TTFT under ~200 ms feels nearly instant; over 1 second starts to feel sluggish even if the model then streams at 150 tokens per second.
TPS controls reading comfort
Once streaming starts, tokens per second determines whether the output keeps up with the reader. Humans read prose at roughly 200–300 words per minute, which is only 3–5 words per second. At 50+ tokens per second the model almost always outruns the human eye, so TPS stops being the bottleneck for reading comfort. However, TPS still matters when the response is consumed programmatically — batch document processing, tool-call parsing, or code generation where the full text must be complete before the next step runs.
Total latency is what counts for automation
In batch pipelines, scheduled jobs, or multi-step agentic workflows where no human is watching a cursor blink, TTFT is irrelevant — the task can't proceed until the full response is available anyway. Here, end-to-end latency (or equivalently, throughput measured in requests per minute) is what drives cost and turnaround time.
| Use case | Primary metric | Why |
|---|---|---|
| Chat / assistant UI | TTFT | Users feel the silence before streaming starts |
| Streaming code completion | TTFT + TPS | First suggestion must appear fast; slow stream causes IDE lag |
| Voice / real-time | TTFT | Must receive first token before text-to-speech can start |
| Batch classification | Total latency / throughput | No human waits; cost per 1 k items is what matters |
| Agentic pipelines | End-to-end latency | Each LLM hop blocks the next; TTFT adds up across steps |
| Reasoning models (with thinking) | Total latency | Thinking happens inside; TTFT may be 10-150 s intentionally |
How it works
Every LLM request follows the same two-phase pipeline. Understanding the phases makes it obvious why TTFT and TPS are fundamentally different problems.
Prefill: parallel and compute-bound
During prefill the entire prompt is processed in one forward pass through the model. Because all input tokens are known in advance, the GPU can process many tokens in parallel — this phase is compute-bound: faster chips, more chips, or smaller models all reduce prefill time. The output of prefill is the KV cache: a set of stored key-value vectors for every prompt token at every layer. These vectors are what the decode phase reads on every future step.
TTFT is therefore primarily determined by: prompt length (more tokens = more prefill work), model size, GPU compute, and any time spent waiting in a request queue before the GPU becomes free. A 10 k-token prompt takes noticeably longer to prefill than a 200-token one on the same hardware.
Decode: sequential and memory-bound
Decode is inherently sequential. The model generates one token, appends it to the context, generates the next, and repeats. Each step must read the entire KV cache accumulated so far — which is why long outputs slow down as generation progresses. This phase is memory-bandwidth-bound: the bottleneck is how fast the GPU can read weights and the growing KV cache from HBM, not raw compute. Adding more compute doesn't help much; wider memory buses and quantized KV caches do.
Inter-token latency (ITL)
A third metric you'll see is inter-token latency (ITL): the average time between successive tokens during decode, measured in milliseconds. TPS = 1000 / ITL_ms. ITL is the decode-phase counterpart to TTFT, and it's what fluctuates when the server is heavily loaded — you'll see it spike mid-stream if a new batch of requests is scheduled alongside yours.
- Prefill phase duration
- Compute-bound
- Scales with prompt length
- Drives perceived responsiveness
- Optimize: smaller models, chunked prefill, prompt caching
- Decode phase step time
- Memory-bandwidth-bound
- Scales with output length + batch size
- Drives streaming smoothness
- Optimize: KV quantization, smaller KV cache, speculative decoding
- TTFT + all decode steps
- Both phases combined
- Scales with prompt + output length
- Drives batch job throughput
- Optimize: balance both phases; reduce output tokens where possible
Measuring in practice
Any OpenAI-compatible streaming endpoint gives you enough timestamps to measure all three metrics client-side. The pattern is the same whether you're hitting GPT, Claude, Gemini, or a self-hosted vLLM instance.
import time
import openai
client = openai.OpenAI() # set OPENAI_API_KEY in env
request_start = time.perf_counter()
first_token_time: float | None = None
token_count = 0
with client.chat.completions.create(
model="gpt-5.5",
messages=[{"role": "user", "content": "Explain transformers in 200 words."}],
stream=True,
) as stream:
for chunk in stream:
if chunk.choices[0].delta.content:
if first_token_time is None:
first_token_time = time.perf_counter()
token_count += 1
end_time = time.perf_counter()
ttft_ms = (first_token_time - request_start) * 1000
total_ms = (end_time - request_start) * 1000
decode_ms = (end_time - first_token_time) * 1000
tps = token_count / (decode_ms / 1000) if decode_ms > 0 else 0
print(f"TTFT: {ttft_ms:.0f} ms")
print(f"Tokens/sec: {tps:.1f}")
print(f"Total latency: {total_ms:.0f} ms")
print(f"Output tokens: {token_count}")For load-testing at scale, purpose-built tools give you histograms automatically. LiteLLM can proxy any provider and log per-request TTFT. Locust with a custom LLM task and llmperf (an open-source benchmark harness) are common choices for stress-testing self-hosted inference endpoints. The Anyscale inference docs publish full definitions for TTFT, ITL, and throughput that align with the community standard.
Provider benchmarks and tradeoffs
TTFT and TPS often pull in opposite directions at the provider level. As of mid-2026, benchmarks from GMI Cloud and BenchLM measuring standardized 500-token prompts with 200-token outputs reveal a clear pattern:
| Model tier | Typical TTFT | Typical TPS | Best for |
|---|---|---|---|
| Small/fast (e.g. Haiku 4.5, Llama-4-Scout) | < 700 ms | 80-150 tok/s | Interactive chat, voice, low-latency agents |
| Mid-size (e.g. GPT-5.4 mini, Gemini 3.5 Flash) | 700 ms – 1.5 s | 80-120 tok/s | Balanced workloads, coding assistants |
| Large (e.g. GPT-5.5, Claude Sonnet 4.6) | 1-3 s | 40-80 tok/s | Quality-critical tasks where latency is secondary |
| Reasoning (e.g. Gemini 3 Deep Think, with thinking) | 10-150 s | 30-80 tok/s | Complex multi-step problems; TTFT is intentional |
Reasoning models are the important outlier here. Their TTFT is deliberately high because the model runs an internal chain-of-thought "thinking" pass before emitting the first visible token. For these models, TTFT is not a performance problem to solve — it is the feature.
One frequently overlooked factor is prompt length sensitivity. TTFT roughly scales linearly with the number of input tokens because prefill work grows with context length. A model that achieves 600 ms TTFT on a 200-token prompt may take 3 s+ on a 5 k-token RAG prompt stuffed with retrieved documents. If your product uses long system prompts or retrieval-augmented context, measure TTFT at your actual prompt lengths, not the provider's headline benchmark.
Going deeper
Once you understand the three-metric model, a range of advanced infrastructure techniques become intuitive.
Prompt caching
If a large portion of your prompt (a long system message, a set of retrieved documents) is repeated across many requests, the provider can cache the KV vectors for that prefix so the next request skips re-prefilling them. Anthropic, OpenAI, and Google all offer prompt caching in some form. For a 10 k-token system prompt hit 1,000 times a day, this eliminates ~90% of prefill work and dramatically reduces TTFT and cost for every cached request.
Chunked prefill and prefill-decode disaggregation
A busy inference server running many requests simultaneously faces a scheduling conflict: a long prefill operation monopolizes the GPU and blocks all decode steps for other users, causing their ITL to spike mid-stream. Chunked prefill splits long prefills into smaller chunks interleaved with decode steps, reducing the maximum ITL spike. Prefill-decode disaggregation goes further: it routes prefill work and decode work to separate GPU pools, each tuned for its phase. Microsoft published a chunked-prefill approach in 2025 showing simultaneous improvement in both TTFT and throughput. The DistServe system (OSDI 2024) demonstrated up to a 7.66x TTFT improvement on Llama-3-405B through disaggregation.
Speculative decoding
Speculative decoding uses a small, fast draft model to generate several candidate tokens in parallel, then runs the large model once to verify or reject them all in a single forward pass. When the draft is right (often 70-80% of the time), multiple tokens are committed per large-model step, effectively multiplying TPS by 2-3x without changing the output distribution. This technique helps decode-phase throughput more than TTFT, but faster decoding means less time the user waits after the first token arrives.
KV cache quantization
Because the decode phase is memory-bandwidth-bound, cutting KV cache size directly improves TPS. FP8 KV quantization halves memory versus FP16 with minimal quality loss. NVIDIA's NVFP4 format (2025) achieves even greater compression. Smaller KV caches also let the GPU serve more concurrent requests, indirectly improving TTFT by reducing queue wait times.
Building a latency SLO
Production teams typically define separate Service Level Objectives (SLOs) for TTFT and ITL rather than a single end-to-end target. A common starting point for interactive applications is p95 TTFT under 1 s and p95 ITL under 50 ms. Alert on p99 to catch tail latency spikes that averages hide. Track these metrics broken down by prompt-length bucket — a single average TTFT across short and long prompts will mask problems with retrieval-heavy requests.
FAQ
What is a good TTFT for a chat application?
For interactive applications, a TTFT under 200 ms feels nearly instant. Under 1 second is generally acceptable. Over 2 seconds starts to feel sluggish and visibly affects user engagement. Measure at your actual prompt lengths and target region, since provider benchmarks often use short test prompts that are not representative of real workloads.
Why does my TTFT increase when I add more context to my prompt?
TTFT is primarily determined by the prefill phase, which processes all input tokens before emitting the first output token. Prefill work grows roughly linearly with prompt length. Adding 5 k tokens of RAG context to a prompt can multiply TTFT by 5-10x compared to a bare short prompt on the same model and hardware. Prompt caching (supported by Anthropic, OpenAI, and Google) can largely eliminate this penalty for repeated prefixes.
Is tokens per second the same as throughput?
Not exactly. Tokens per second usually refers to the output generation speed for a single request (the decode phase). Throughput typically refers to how many total output tokens a server can produce per second across all concurrent requests. A server running 50 concurrent users at 20 tok/s each has 1,000 tok/s throughput even though each individual user only sees 20 tok/s.
Why do reasoning models have such high TTFT?
Reasoning models like Gemini 3 Deep Think, or other models with thinking enabled, run an internal chain-of-thought pass before emitting the first visible response token. This thinking phase can last tens of seconds or even minutes. The high TTFT is intentional — it is the computation that improves answer quality on hard problems. For these models, monitor total latency and answer correctness rather than optimizing TTFT.
What is inter-token latency (ITL) and how is it related to TPS?
Inter-token latency (ITL) is the average time in milliseconds between successive tokens during the decode phase. TPS and ITL are inverses: TPS = 1000 / ITL_ms. ITL is more useful when debugging streaming smoothness because it reveals individual step delays, while TPS is a summary statistic. A high ITL variance (some tokens fast, some slow) can make streaming feel choppy even if average TPS looks fine.
How do I reduce TTFT without switching to a smaller model?
The most impactful options are: (1) prompt caching — if your system prompt or RAG documents repeat across requests, caching their KV vectors can cut prefill cost by 80-90%; (2) shorten the prompt — remove boilerplate, truncate retrieved chunks to the minimum needed; (3) choose a faster provider region — geographic proximity reduces network round-trip; (4) use a dedicated provisioned endpoint — shared endpoints add queue wait time to TTFT under load.