In plain English
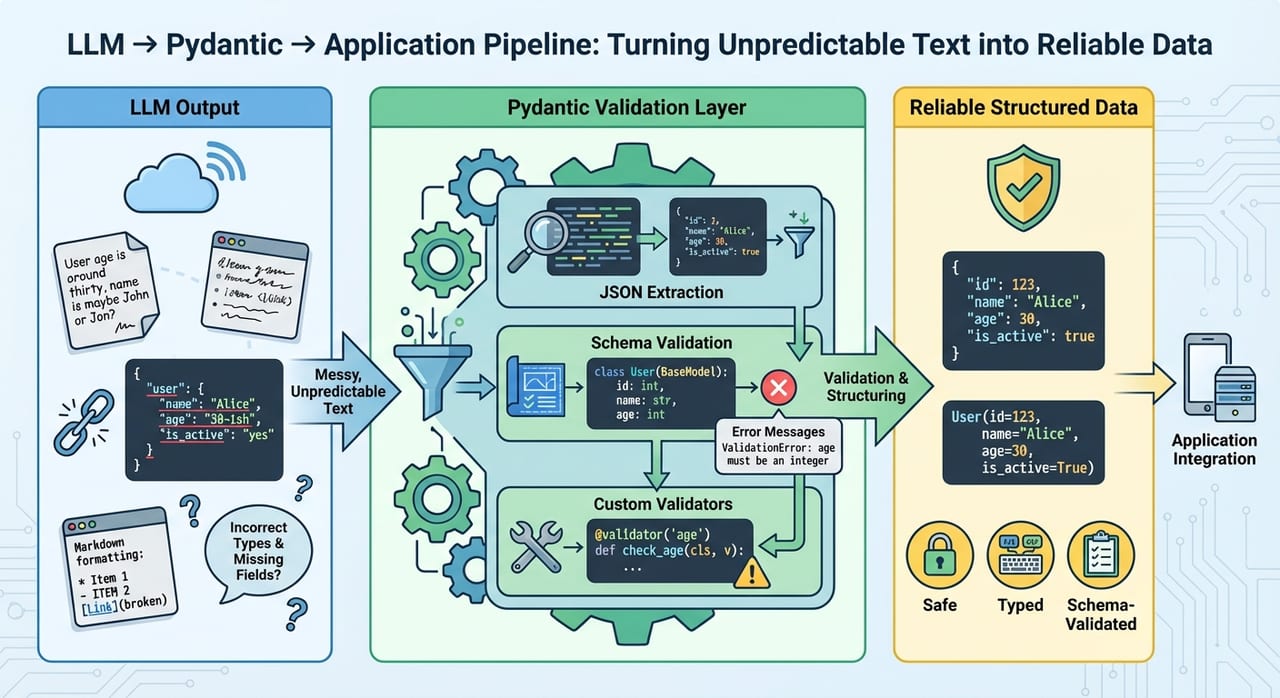
Schema validation for LLM output is the practice of taking whatever text a model returns and running it through a typed shape definition — a schema — that says exactly what fields must be present, what types they must be, and what values are acceptable. If the output matches, you get a proper typed object. If it doesn't, you know immediately and can act on the failure instead of letting bad data flow downstream.
The classic analogy: imagine ordering a pizza delivery with a very specific checklist — large, pepperoni, no olives, cut into 8 slices, delivered before 7 pm. The delivery driver (the LLM) is enthusiastic and usually gets it right, but occasionally forgets the extra cheese, sends a calzone, or writes your address in the notes field. Schema validation is the person at the door with the checklist. They compare what arrived against what was ordered, and if it doesn't match they send it back before it lands on the table.
In practice this means you define a schema in code — using Zod (TypeScript), Pydantic (Python), or raw JSON Schema — and then parse the model's JSON string through it at runtime. The schema becomes the contract between your app and the model. Your downstream code never touches unvalidated output; it only ever sees a fully typed, guaranteed-correct object.
Why it matters
LLMs produce text — plausible, fluent, confident text. When you ask for JSON you usually get something that looks like JSON. But "looks like JSON" is not the same as "is valid JSON that matches my schema". Common failure modes include missing commas, unescaped quotes, truncated output (the model hit its token limit mid-object), hallucinated field names, and values of the wrong type — a string where you needed a number, or null where you needed a list.
These failures are invisible until they crash your pipeline. A json.loads() call throws on malformed JSON, but a structurally valid JSON object with the wrong keys or types flows silently into your database, your email sender, or your payment processor — and the bug only surfaces when a customer notices a $0.00 charge or a missing confirmation.
The compounding problem in agents
Single model calls are bad enough. In a multi-step agent pipeline, failures compound fast. If each step has a 5% schema failure rate, a 12-step agent run has roughly a 46% chance that at least one step produces invalid output. Without schema validation and repair at every step, agent pipelines degrade quickly at scale.
Why prompts alone are not enough
The instinctive fix is to make the prompt more explicit: "reply ONLY with valid JSON", "do not include any explanation". That helps, but it is a request, not a guarantee. A well-prompted model still fails occasionally — especially under long contexts, creative generation, or adversarial inputs. Schema validation is the enforcement layer that runs after the model, regardless of whether the prompt was followed.
How it works
The mechanics split into two concerns: defining the schema (what shape do I expect?) and handling failures (what do I do when the model returns something wrong?). The happy path is straightforward — parse the JSON, run it through the schema, get a typed object. The interesting engineering is in the retry-and-repair loop that kicks in on failure.
When the schema check fails you have two options: repair or retry. Repair means applying a heuristic fixer — a library like json_repair that patches missing commas, unescaped quotes, and truncated structures without making another model call. Retry means sending the model a new request that includes the validation error so it can self-correct. In practice you often do both: repair first (fast, free), and if the repaired output still fails the schema, retry once with the error fed back into the prompt.
Constrained decoding: preventing failures at the source
The deepest defence is constrained decoding — a technique where the provider compiles your JSON Schema into a finite state machine and only allows tokens that keep the output on a valid path through that machine at every generation step. Invalid tokens get their log-probabilities set to negative infinity, so the model literally cannot produce malformed output. OpenAI launched this as Structured Outputs in August 2024, and current frontier models reliably produce schema-conformant output with it enabled. Other providers followed with similar approaches. When constrained decoding is available, you still validate on your side — but you'll rarely need to repair.
- Parse raw text after the call
- Works with any provider/model
- Needs repair or retry on failure
- Catches wrong types and values
- Full schema expressiveness
- Valid JSON guaranteed at generation
- Provider must support it (OpenAI, Anthropic, Gemini)
- Rarely needs retries
- Some schema features unsupported (recursive types, etc.)
- Still validate field values yourself
The validation toolkit: Zod, Pydantic, Instructor, and more
Several libraries have become the standard tools for this job, each with a slightly different design philosophy.
Pydantic (Python)
Pydantic is the dominant choice for Python. You declare a class that inherits from BaseModel, annotate fields with Python types, and call MyModel(**json.loads(text)). Pydantic validates types, applies default values, runs @field_validator functions for custom business rules, and raises a ValidationError with a machine-readable list of every broken field when parsing fails. That structured error is exactly what you feed back to the model in a retry prompt.
from pydantic import BaseModel, field_validator, ValidationError
import json
class ExtractedEvent(BaseModel):
title: str
date: str # YYYY-MM-DD
confidence: float # 0.0 – 1.0
@field_validator("confidence")
@classmethod
def clamp(cls, v: float) -> float:
if not (0.0 <= v <= 1.0):
raise ValueError("confidence must be between 0 and 1")
return v
raw = '{"title": "Launch party", "date": "2026-07-01", "confidence": 0.92}'
try:
event = ExtractedEvent(**json.loads(raw))
print(event.title, event.confidence) # Launch party 0.92
except ValidationError as e:
# e.errors() is a list of dicts — perfect for a retry prompt
print(e.errors())Instructor (Python)
Instructor wraps the OpenAI, Anthropic, and 15+ other SDKs with a thin layer that automatically converts your Pydantic model to a JSON Schema, injects it into the API call, and runs validation + retry in a loop. With max_retries=3, Instructor will feed validation errors back to the model automatically, creating a self-healing call that resolves most failures without any extra code. It has over 3 million monthly downloads and is the most popular structured-output library in Python as of 2026.
import instructor
from anthropic import Anthropic
from pydantic import BaseModel
client = instructor.from_anthropic(Anthropic())
class Sentiment(BaseModel):
label: str # "positive" | "negative" | "neutral"
score: float # 0.0 – 1.0
# Instructor handles: schema injection, parsing, validation, retry
result = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=128,
messages=[{"role": "user", "content": "I loved the new release!"}],
response_model=Sentiment,
max_retries=3,
)
print(result.label, result.score) # positive 0.97Zod (TypeScript)
Zod is the TypeScript equivalent. You define schemas with a fluent builder API, call schema.parse(JSON.parse(text)), and get a fully typed value back — or a ZodError with structured field-level errors. Zod v4 (released 2025) added a built-in .toJSONSchema() method that converts any Zod schema to JSON Schema, which you can pass directly to OpenAI's response_format parameter or Anthropic's tool schema. This eliminates the need for the third-party zod-to-json-schema package, which was officially deprecated after Zod v4 shipped.
import { z } from "zod";
import OpenAI from "openai";
const EventSchema = z.object({
title: z.string(),
date: z.string().regex(/^\d{4}-\d{2}-\d{2}$/),
confidence: z.number().min(0).max(1),
});
// Zod v4: convert schema to JSON Schema for the API
const jsonSchema = z.toJSONSchema(EventSchema);
const client = new OpenAI();
const response = await client.chat.completions.create({
model: "gpt-5.5",
response_format: { type: "json_schema", json_schema: { name: "event", strict: true, schema: jsonSchema } },
messages: [{ role: "user", content: "Extract the event from: Launch party on July 1st 2026, very confident." }],
});
// Validate at runtime despite the API guarantee — catches value-level errors
const parsed = EventSchema.parse(JSON.parse(response.choices[0].message.content!));
console.log(parsed.title, parsed.confidence);Vercel AI SDK (TypeScript)
The Vercel AI SDK ships a generateObject function that accepts a Zod schema, selects the best available structured-output mechanism per provider (constrained decoding if available, function calling otherwise), and returns a validated typed object. AI SDK 5 (released July 2025) added agentic loop control and SSE-based streaming. Production deployments report 99.8% successful extraction rates with automatic retries on the rare failures.
| Library | Language | Key strength | Retry built-in? |
|---|---|---|---|
| Pydantic | Python | Field validators, ecosystem breadth | No — add yourself or use Instructor |
| Instructor | Python | Multi-provider, auto-retry loop | Yes (max_retries) |
| PydanticAI | Python | Agent-first, type-safe tool responses | Yes |
| Zod | TypeScript | Fluent builder, built-in JSON Schema export (v4) | No — pair with retry wrapper |
| Vercel AI SDK | TypeScript | Provider abstraction, streaming, agent loop | Yes (generateObject) |
| json_repair | Python / Rust | Heuristic fixer, drop-in for json.loads | N/A — repair only |
Retry-and-repair patterns
Knowing that validation failed is only half the job. Knowing what to do next is where production reliability comes from. The failure actions form a ladder from cheapest to most expensive:
- Heuristic repair first. Libraries like
json_repair(Python, with a Rust portfast-json-repairfor performance) fix the most common LLM JSON mistakes — missing commas, unclosed brackets, trailing prose, unescaped newlines — without making another model call. Use this as a first pass before any retry. - Retry with the error message. If repair still fails schema validation, send a new request that includes the original bad output and the
ValidationErrororZodErrordetails. Structured error messages (field path + reason) give the model a concrete fix. Research shows that self-correcting retries resolve 85–95% of validation failures on the second attempt for capable models. - Retry with a stricter prompt. If the model keeps misunderstanding the schema, rephrase the schema description in the prompt — add examples, simplify field names, or split a complex schema into two sequential calls.
- Fallback to a safe default. If all retries exhaust, return a well-defined fallback value rather than propagating
nullor crashing. Log the failure for your observability pipeline.
import json
from json_repair import repair_json # pip install json-repair
from pydantic import BaseModel, ValidationError
from anthropic import Anthropic
client = Anthropic()
class Summary(BaseModel):
headline: str
bullet_points: list[str]
confidence: float
def call_llm(prompt: str) -> str:
msg = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=512,
messages=[{"role": "user", "content": prompt}],
)
return msg.content[0].text
def extract_summary(text: str, max_retries: int = 2) -> Summary:
base_prompt = (
f"Summarize this text as JSON with fields: "
f'headline (str), bullet_points (list of str), confidence (float 0-1).\n\n{text}'
)
prompt = base_prompt
last_error = None
for attempt in range(max_retries + 1):
raw = call_llm(prompt)
# Step 1: heuristic repair (free, no extra call)
repaired = repair_json(raw)
try:
return Summary(**json.loads(repaired))
except (json.JSONDecodeError, ValidationError) as e:
last_error = e
# Step 2: feed structured error back for self-correction
prompt = (
base_prompt
+ f"\n\nYour previous output was invalid: {e}\n"
+ f"Previous output was: {raw}\nPlease fix and try again."
)
raise ValueError(f"Failed after {max_retries + 1} attempts: {last_error}")For TypeScript, the pattern is identical in structure: catch the ZodError, extract error.errors (an array of {path, message} objects), serialize them into a natural-language correction prompt, and retry. Most teams cap retries at 1–2 to limit latency blowout; beyond two retries the model is usually confused about the schema itself and a prompt rewrite is a better fix.
Common pitfalls and tradeoffs
Schema validation looks simple but has a handful of non-obvious failure modes that trip up production systems.
Over-constraining the schema
A very strict schema — requiring an enum with 20 values, a regex-validated string, AND a specific date format — leaves the model very little room and increases failure rates significantly. When you see persistent validation failures, the first question should be "is my schema too strict for what I actually need?" Often you can validate the critical fields strictly and accept a wider type for less critical ones.
Confusing JSON Schema features with provider support
Not all JSON Schema features are supported by every provider's constrained decoding. OpenAI's strict mode does not support recursive schemas, unevaluatedProperties, or certain $ref patterns. If your Zod or Pydantic schema uses advanced features and you convert it to JSON Schema for API injection, test it manually — the API may silently accept the schema but generate output that doesn't actually conform.
Treating schema validation as the whole story
A schema can guarantee amount: number, but it cannot guarantee amount is the correct number for this customer's order. Schema validation is a structural guarantee, not a semantic one. For semantic correctness — "did the model hallucinate a policy clause?" — you need an LLM-as-judge or human review, not a Pydantic model.
Latency cost of retry loops
A retry means another full model call — adding the model's response latency to your user-facing request. With p99 latencies of 2–10 seconds on frontier models, a two-retry loop can turn a 3-second response into a 9-second one. Use json_repair as the first pass (milliseconds), keep retries to one maximum on the hot path, and consider moving complex extractions to a background queue where latency is invisible.
| Failure mode | Cause | Fix |
|---|---|---|
| JSON parse error | Trailing prose, truncated output, markdown code fences | Run json_repair before schema validation |
| Wrong type on a field | Model outputs '"true"' instead of true | Pydantic coercion (model_config = {"coerce_numbers_to_str": ...}), or loosen schema |
| Missing optional field | Model omits a field it thinks is irrelevant | Set Pydantic default=None or Zod .optional() for truly optional fields |
| Persistent failure after retries | Schema too complex or ambiguous to the model | Split into two sequential calls; add an example in the prompt |
| Constrained decoding strips decimals | Provider bug with float constraints | Accept string and parse to float in a validator |
Going deeper
Once you have a working validation loop, several advanced patterns become relevant — especially as you move from single-call apps to multi-step pipelines and agents.
Semantic validation alongside structural validation
Pydantic's @field_validator and @model_validator let you encode business rules inside the schema itself — amount >= 0, end_date > start_date, status in ('pending', 'approved', 'rejected'). Instructor's llm_validator goes further: it uses a second, cheaper model call to check criteria that are hard to express programmatically, like "does this summary faithfully represent the source?". These semantic checks turn your schema from a structural contract into a quality contract.
Streaming and partial validation
When you stream output tokens to a user, the full JSON object doesn't exist until the final token arrives. Libraries like Instructor and the Vercel AI SDK support partial streaming validation — they parse the partial JSON as it arrives, yield type-safe partial objects, and complete the validation when the stream closes. This is important for progressive UIs that fill in fields as they arrive rather than showing a spinner until the whole response is ready.
Schema versioning in long-lived pipelines
In production, your schema evolves. Adding a required field to your Pydantic model means all existing cached or stored model outputs instantly fail validation. Teams handle this with backward-compatible schema design: new fields are always Optional at first, promoted to required only after the model is fine-tuned or prompted to include them consistently. Treat your validation schema like a database migration — breaking changes need a plan.
Validation as observability signal
Every schema failure is a free signal for your LLMOps dashboard. Log the raw output, the validation error, and whether the repair or retry succeeded. Aggregate these over time: if confidence field errors spike after a model upgrade, your prompt probably needs updating. If json.JSONDecodeError rises when context length increases, the model is being truncated. Schema validation is not just error handling — it's a window into how reliably your model is following the contract.
When not to use JSON output at all
Structured output works well when you need a machine-readable result — classification, extraction, tool arguments. It is the wrong tool when the primary value is readable prose for a human. Don't force JSON on a customer-facing summary just because it's easier to test. Apply schema validation where your app actually parses and acts on the model's output, and leave prose outputs as prose.
FAQ
Why does my LLM keep returning invalid JSON even when I ask for it in the prompt?
LLMs predict the next token and can hallucinate structure, especially under long contexts or when the output budget is tight and the model truncates mid-object. A strong prompt helps but is not a guarantee. Use schema validation with a repair-and-retry loop, and consider enabling the provider's constrained-decoding mode (response_format: {type: "json_schema"} on OpenAI, tool-use schema on Anthropic) to mathematically prevent structural failures.
What is the difference between Zod and Pydantic for LLM validation?
Zod is a TypeScript library for runtime schema validation with a fluent builder API; Pydantic is the Python equivalent built on type hints. Both define schemas, parse at runtime, and produce structured errors on failure. Choose Zod for TypeScript/Node projects and Pydantic for Python. For Python, the Instructor library wraps Pydantic with automatic retry logic, making it the most ergonomic choice for LLM pipelines.
How many times should I retry a failed LLM schema validation?
One retry with the error fed back resolves 85–95% of failures for capable models. Cap at two retries on the hot path to avoid turning a 3-second call into a 9-second one. If the model still fails after two retries, the prompt or schema likely needs reworking rather than more retries.
What is constrained decoding and do I still need schema validation if my provider supports it?
Constrained decoding compiles your JSON Schema into a finite state machine and restricts which tokens the model can emit, guaranteeing structurally valid JSON. OpenAI's Structured Outputs mode uses this and achieves 100% structural compliance. However, it only guarantees structure — it cannot guarantee that amount is positive or that status is a meaningful value. Always run Pydantic or Zod field validators on top of the provider's structural guarantee.
What does json_repair do and when should I use it?
json_repair is a Python library (with a Rust port fast-json-repair) that fixes the most common LLM JSON mistakes — missing commas, unclosed brackets, unescaped quotes, trailing prose — without making another model call. Use it as a cheap first pass before any retry. It handles the majority of syntactic failures in milliseconds and costs nothing extra.
Can I validate LLM output that is streamed token by token?
Yes. Libraries like Instructor and the Vercel AI SDK support partial streaming validation — they parse the incomplete JSON as tokens arrive and yield type-safe partial objects. Full validation completes when the stream closes. This lets you build progressive UIs that render fields as they arrive rather than waiting for the entire response.