In plain English
An LLM gateway is a layer that sits between your application and every model provider you call — OpenAI, Anthropic, Google, Bedrock, whatever — and gives all of them a single, consistent front door. Instead of your code talking directly to each vendor's SDK and URL, it talks to the gateway, and the gateway handles the conversation with whichever provider is on duty.
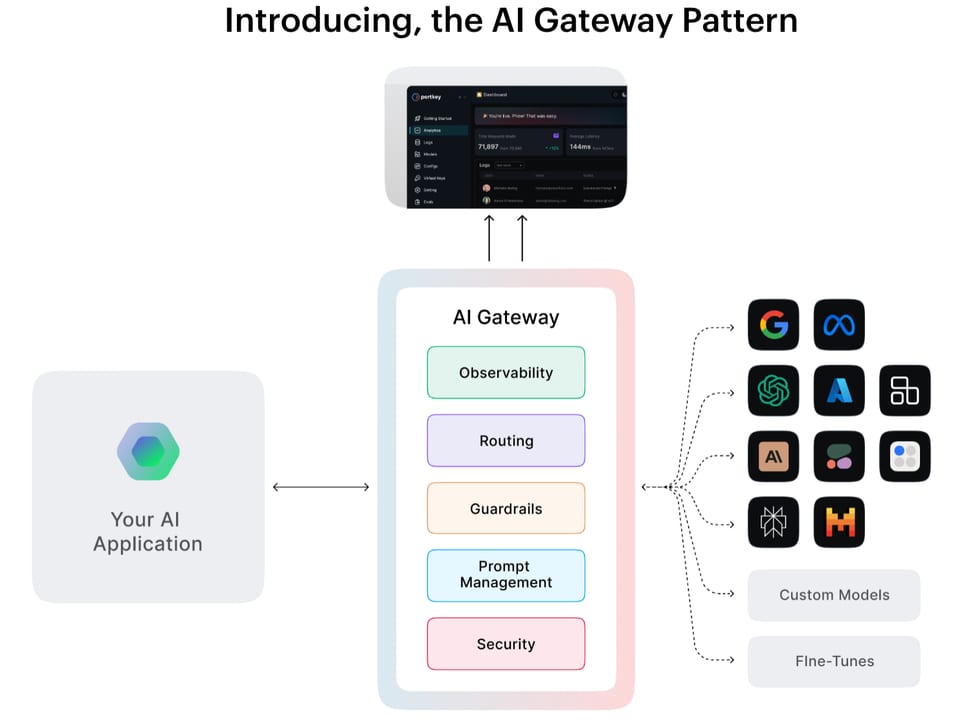
Think of it like the concierge desk at a large hotel. Guests (your app) walk up to one desk and ask for whatever they need. The concierge (the gateway) figures out which staff member, floor, or outside vendor handles that request, logs the interaction, watches the clock, and makes sure the guest isn't charged twice. The guest never has to know that the restaurant, the spa, and the valet are all different companies — they just talk to the desk.
In practice, a gateway is usually a lightweight HTTP server — sometimes called an LLM proxy — that you run yourself (open-source tools like LiteLLM) or subscribe to as a managed service (Portkey, OpenRouter). Every LLM call your app makes goes through it, and along the way the gateway can log the request, count the tokens and dollars, cache repeated answers, retry on a 429, fall over to a backup model, and apply guardrails — all without changing a single line of your application logic.
Why it matters
Every app that calls an LLM provider has the same invisible problems lurking: vendor APIs each have different SDKs and parameter names, rate limits hit at unpredictable moments, the bill can explode without warning, and if one provider goes down your whole product goes down with it. A gateway turns all of those into solved problems at the infrastructure layer so your application code stays simple.
The problems a gateway solves
- Vendor lock-in. Hard-coding the OpenAI SDK into 40 files means switching to Claude requires touching 40 files. A gateway gives you one interface; provider swaps are a config change, not a refactor.
- Rate-limit pain. LLM providers throttle by requests-per-minute and tokens-per-minute. A gateway queues and retries automatically, and distributes load across multiple API keys or deployments so you hit the wall less often.
- Cost surprises. Without centralized tracking, LLM spend is invisible until the invoice arrives. A gateway counts every token for every call and every team, so you can set hard budgets before the damage is done.
- Reliability. When Anthropic returns a 503 at 2 AM, a gateway can silently re-route the request to Bedrock or Azure OpenAI and return a response — no pager alert needed.
- Scattered logs. Running three services each calling OpenAI directly means three sets of logs to search. Route everything through a gateway and you get one unified trace of every call.
You may not need all of these on day one. A solo prototype calling one provider for a few hundred users is usually fine without a gateway. The inflection point is typically when you cross three or more services calling LLM APIs or a monthly LLM spend above a few thousand dollars — that's when the overhead of a gateway pays for itself in the first incident it prevents.
How it works
When your application makes a chat completion request, it sends the request to the gateway's local URL instead of the provider's endpoint. The gateway receives the request, applies its rules, forwards the call to the selected provider, and streams or returns the response back to your app. Your app sees a standard OpenAI-compatible response regardless of which provider actually served it.
The six jobs a gateway does on every request
| Job | What happens | Why it helps |
|---|---|---|
| Auth & key management | App sends one gateway API key; gateway holds all vendor secrets | Rotate provider keys in one place without redeploying apps |
| Caching | Hash the prompt; return a stored response on a cache hit | Cuts costs 30–50% on workloads with repeated queries |
| Routing | Pick the right model/provider based on latency, cost, or rules | Cheapest model that meets SLA; geo-routing for compliance |
| Retry & fallback | On 429/503, retry or switch to a backup provider transparently | Keeps the app alive through transient outages |
| Logging & observability | Record prompt, response, tokens, latency, and cost per call | One searchable audit trail; feed into dashboards or LLM evals |
| Rate limiting & budgets | Enforce per-team or per-user token quotas | Prevent runaway costs; multi-tenant fairness |
Caching comes in two flavors. Exact caching stores the hash of the request and returns the identical response — useful for FAQ bots where the same question recurs. Semantic caching embeds the prompt and does a nearest-neighbor search: if an incoming question is close enough to a cached one, the cached answer is returned. Semantic caching is more complex to run but can dramatically reduce provider calls for support or search workloads.
Fallback chains are how reliability is achieved without app-level try/catch logic. You declare a priority list — say ["gpt-5.5", "claude-sonnet-4-6", "gpt-5.4-mini"] — and the gateway tries each in order on any non-retriable error or timeout. The app just gets an answer.
LiteLLM, Portkey, and OpenRouter compared
Three tools dominate real-world LLM gateway usage. They occupy different positions on the hosted-vs-self-hosted and simple-vs-enterprise axes, so the choice usually comes down to where you sit on those two dimensions.
LiteLLM
LiteLLM is an open-source Python project (MIT license, 18 000+ GitHub stars as of mid-2026) that translates 100+ provider APIs into a single OpenAI-compatible interface. You can use it as a Python SDK in-process or deploy the standalone proxy server. Because you self-host it, you keep full control of your data and API keys — popular in enterprises with strict data-residency rules. It supports load balancing across multiple API keys for the same provider, per-model spend tracking, and a SQLite or Postgres backend for logs.
# Install and start the LiteLLM proxy
pip install litellm[proxy]
litellm --model anthropic/claude-sonnet-4-6 --port 4000
# Your app now calls http://localhost:4000 with the OpenAI SDKPortkey
Portkey started as a managed cloud gateway but open-sourced its core (Apache 2.0) in early 2025. It positions itself as the "control plane for AI" — the differentiating emphasis is on production safety: 50+ built-in guardrails, PII redaction, jailbreak detection, audit logs, prompt versioning with environment promotion, and team-level RBAC. The managed platform handles over 10 billion LLM requests per month with a stated 99.9999% uptime and sub-40ms added latency. It's the go-to for regulated industries or teams that need governance tooling out of the box.
OpenRouter
OpenRouter is a managed marketplace gateway launched in 2023. Rather than asking you to run infrastructure, it provides a hosted endpoint that routes your request to the cheapest or fastest available provider for the model you request. You pay per token through OpenRouter's billing layer — no per-provider accounts needed. It adds roughly 25–30ms of overhead and can automatically fall over across 50+ cloud providers. It's the simplest path to multi-provider access, especially for side projects or early prototypes.
| Tool | Hosting model | Best for | Guardrails/governance |
|---|---|---|---|
| LiteLLM | Self-hosted (open source) | Teams that need data control and broad provider coverage | Basic; pluggable |
| Portkey | Managed + self-hostable | Teams needing enterprise safety, prompt governance, RBAC | 50+ built-in guardrails |
| OpenRouter | Managed SaaS | Quickest path to multi-model; single billing account | Minimal |
| Cloudflare AI Gateway | Managed edge | Teams already on Cloudflare; near-zero setup + edge caching | Basic |
| Helicone | Managed + self-hostable (Rust) | Observability-first teams; cheapest cost-visibility layer | Minimal |
Do you actually need a gateway?
The honest answer is: probably not yet. A single-provider app with one team, modest traffic, and no regulatory requirements gains little from a gateway. The operational overhead — another service to run, another thing to monitor — is real, and it's dead weight if you're not hitting the problems it solves.
Add a gateway when you hit these thresholds
- Three or more services call LLM APIs independently — tracking spend and debugging failures across scattered codebases is the first pain point a gateway fixes.
- Monthly LLM spend exceeds a few thousand dollars — at that point per-team budgets and token tracking pay for themselves in the first overage they catch.
- You need provider redundancy — if your product cannot tolerate a primary provider outage, fallback routing is the solution.
- You serve multiple teams or tenants — per-team rate limits and audit logs become compliance requirements, not nice-to-haves.
- Your model roster is actively changing — gateways make model swaps a config edit; doing it in application code is error-prone at scale.
If none of those apply, the pragmatic move is a thin abstraction in your own code: one function or class that wraps all your LLM calls. This gives you the same vendor-swap benefit at zero operational cost, and when you do hit the gateway thresholds, replacing that wrapper with a gateway client is a ten-minute job.
Going deeper
Once a gateway is in place it becomes the natural enforcement point for the more advanced concerns in your LLMOps stack.
Semantic caching at scale
Exact prompt caching (hash-and-store) is straightforward but has low hit rates on varied input. Semantic caching embeds every incoming prompt into a vector, queries a vector store for near-neighbours above a similarity threshold, and returns the stored response if a match is found. Hit rates of 40–60% are realistic for customer support and internal search workloads. The engineering cost is a vector store (often Redis with a vector module, or pgvector) and a threshold-tuning exercise to avoid serving semantically-adjacent-but-wrong answers.
Model routing strategies
Simple gateways route by provider order. Advanced routing adds intelligence: route cheap classification tasks to a smaller model (GPT-5.4 mini, Haiku) and expensive reasoning tasks to a frontier model; route based on current provider latency measured by recent p95s; route by the user's geography to comply with data-residency rules. LiteLLM's router_strategy parameter supports latency-based, least-busy, and weighted-random strategies out of the box.
Gateway as guardrail layer
Because every prompt and response flows through the gateway, it is also the most efficient place to run guardrails. A pre-call hook can scan the incoming prompt for PII or policy violations; a post-call hook can scan the response before it reaches the user. This keeps safety logic centralized — you don't need to replicate it across every microservice. Portkey's managed guardrails, LiteLLM's callback hooks, and standalone guardrail libraries (Guardrails AI, Llama Guard) all integrate at this layer.
Virtual keys and multi-tenancy
Enterprise gateways support virtual API keys: your internal teams each get a gateway key that carries spend limits, allowed models, and audit metadata. The gateway maps those keys to real provider credentials that only the gateway holds. This means you can revoke a team's access, change their budget cap, or audit their usage without touching provider accounts or redeploying services. It's the pattern that makes gateways worthwhile at org scale — the control plane separates cleanly from the data plane.
# LiteLLM config.yaml — virtual key example
model_list:
- model_name: gpt
litellm_params:
model: openai/gpt-5.5
api_key: os.environ/OPENAI_API_KEY
- model_name: claude-sonnet
litellm_params:
model: anthropic/claude-sonnet-4-6
api_key: os.environ/ANTHROPIC_API_KEY
router_settings:
routing_strategy: latency-based-routing
num_retries: 3
fallbacks:
- gpt:
- claude-sonnet
litellm_settings:
max_budget: 500.00 # $500/month hard cap across all keysThe long arc of gateway adoption usually follows three stages: proxy (unified API, one provider), then router (multiple providers, fallbacks), then control plane (budgets, virtual keys, guardrails, evals). Most teams spend months at stage one before the pain of stage two arrives. That's fine — the architecture is additive and each stage compounds on the last.
FAQ
Is an LLM gateway the same as an API proxy?
A proxy forwards requests and normalizes APIs — that's the minimal version. A gateway adds routing logic, spend tracking, caching, rate limiting, guardrails, and audit trails. In everyday usage most people use the terms interchangeably, but when a vendor says "gateway" they usually mean the full feature set, not just forwarding.
Does adding a gateway make my LLM calls slower?
A self-hosted gateway on the same network typically adds 5–20ms. A managed cloud gateway (Portkey, OpenRouter) adds 25–50ms. For most chat and generation workloads where the model itself takes hundreds of milliseconds to respond, this overhead is negligible. Caching can more than compensate — cache hits return in single-digit milliseconds.
What is the difference between LiteLLM and OpenRouter?
LiteLLM is open-source software you deploy yourself — your data stays in your infrastructure and you pay each provider directly. OpenRouter is a managed hosted service — simpler to set up, you pay OpenRouter which pays providers on your behalf, but your prompts flow through their infrastructure. LiteLLM gives more control; OpenRouter gives less operational work.
Can a gateway work with streaming responses?
Yes. All major gateways (LiteLLM, Portkey, OpenRouter) support server-sent events (SSE) streaming end to end. The gateway transparently proxies the token stream from the provider to your client, logging the final assembled response and token count after the stream closes.
Do I need a gateway if I only use one model provider?
Not immediately, but there are still reasons to add one: centralized API key management, per-team spend tracking, caching, and an easy migration path if you ever want to change providers. If you're a single team on a single provider with modest traffic, a thin wrapper function in your own code usually covers the bases without the operational cost.
What is semantic caching and how does it save money?
Semantic caching stores previous LLM responses indexed by the meaning of their prompt, not the exact text. When a new request comes in, its prompt is embedded and compared against stored embeddings. If the similarity is above a threshold, the cached response is returned without calling the provider. For workloads with many near-duplicate queries — support bots, FAQ systems, internal search — hit rates of 40–60% are common, cutting provider costs proportionally.