In plain English
Imagine a talented colleague who always blurts the first thing that comes to mind. Ask them a simple question — "what's your email?" — and the instant answer is great. Ask them to audit a 50-page contract for legal gaps, and their instant answer is almost certainly wrong. What you actually want is for them to sit down, read carefully, make notes, and then give you a verdict. The reading-and-note-taking phase is invisible to you; you only see the final verdict.
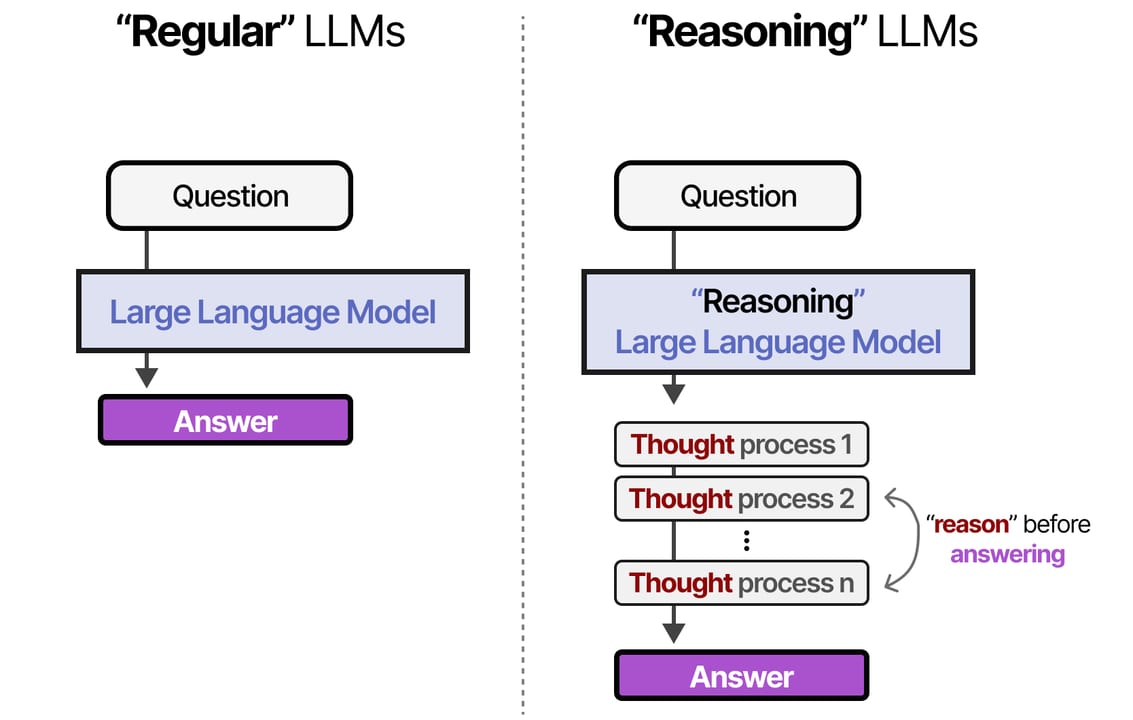
Reasoning models work exactly like that careful colleague. Before producing the response you see, they generate a private scratchpad — a long internal monologue of scratch work, self-corrections, and intermediate conclusions. In the API this scratchpad is called thinking tokens (Anthropic) or reasoning tokens (OpenAI). You never see them in the final reply, but they shape it deeply: the model arrives at its answer only after working through the problem on that invisible notepad.
Two of the most prominent families are OpenAI's reasoning-capable GPT-5 series and Anthropic's Claude models with extended thinking enabled (the Opus and Sonnet tiers). Both let you control how much thinking the model does — spending more tokens for harder problems and fewer for easy ones.
Why it matters
Standard LLMs generate one token at a time, and each token gets roughly the same, fixed amount of computation from the network's layers. On a simple factual question that works fine. On a problem that genuinely requires ten sequential logical steps — a mathematical proof, a code-debugging session, a multi-constraint planning task — the model must compress all that reasoning into the tokens it outputs. When those tokens are few, many steps get skipped or conflated, and the answer is wrong in a confident-sounding way.
Reasoning models solve this by converting time into accuracy. By generating thousands of thinking tokens before the visible answer, the model effectively runs a much deeper computation on the same input. Benchmarks bear this out: on AIME (a hard math olympiad) and graduate-level science questions (GPQA Diamond), reasoning models dramatically outperform standard models of comparable parameter count.
Why should a builder care?
- Multi-step code generation or debugging. The model can plan the solution, write pseudocode, catch type errors in the thinking phase, and only then produce clean code.
- Complex document analysis. Comparing clauses across a contract, identifying policy contradictions, or scoring a rubric with many interdependent criteria.
- Agentic pipelines. Planning which tools to call, in what order, with what arguments — without forcing you to chain many API calls together.
- Math, science, and symbolic reasoning. Anything where the answer depends on a series of provably correct intermediate steps.
- When you've hit the accuracy ceiling on a standard model. If prompt engineering, few-shot examples, and chain-of-thought tricks still produce errors, a reasoning model is the next lever to pull.
How it works
When you call a reasoning model, the request goes through two phases. First the model generates a reasoning trace — a long sequence of tokens that is essentially the model "thinking out loud" to itself, exploring approaches, checking sub-results, and correcting mistakes. Second, it generates the final visible response, conditioned on everything in that trace. The two phases are sequential: the answer tokens literally see the thinking tokens as context.
The reasoning tokens occupy real space in the context window and are billed as output tokens — the most expensive kind. A response showing 600 visible output tokens might have consumed 4,000 thinking tokens underneath, so the actual bill is for 4,600 output tokens. You can see this in the API response's usage object.
Controlling the thinking budget
Both OpenAI and Anthropic expose a budget knob. OpenAI calls it reasoning.effort (values: low, medium, high). Anthropic's budget_tokens parameter sets a hard cap on how many thinking tokens Claude can use for a request — the minimum is 1,024 and the maximum tracks the model's overall output limit. Raising the budget improves accuracy on hard tasks at higher cost and latency; lowering it saves money and is fine for easier tasks.
import anthropic
client = anthropic.Anthropic() # reads ANTHROPIC_API_KEY
# Extended thinking on Claude — budget_tokens controls how hard it thinks
response = client.messages.create(
model="claude-opus-4-8",
max_tokens=16000,
thinking={
"type": "enabled",
"budget_tokens": 10000 # up to 10k tokens of private reasoning
},
messages=[{
"role": "user",
"content": "A train leaves Chicago at 08:00 going 90 mph toward NYC. "
"Another leaves NYC at 09:30 going 70 mph toward Chicago. "
"The cities are 790 miles apart. When and where do they meet?"
}]
)
# Thinking blocks come back separately from text blocks
for block in response.content:
if block.type == "thinking":
print("[thinking]", block.thinking[:200], "...")
elif block.type == "text":
print("[answer]", block.text)import openai
client = openai.OpenAI() # reads OPENAI_API_KEY
# Reasoning effort on an OpenAI GPT-5 series model
response = client.chat.completions.create(
model="gpt-5.5",
reasoning_effort="high", # low | medium | high
messages=[{
"role": "user",
"content": "Find the bug in this merge sort implementation: ..."
}]
)
print(response.choices[0].message.content)
# Note: reasoning tokens are NOT returned in the response object
# but are visible in response.usage.completion_tokens_detailsReasoning model vs standard model: the tradeoff table
Choosing between a reasoning model and a standard model is fundamentally a tradeoff between cost + latency and accuracy on hard tasks. Neither is universally better.
- Fast — seconds per response
- Cheaper per token
- Output tokens = visible output
- Great for conversational tasks, summarisation, simple Q&A
- Chain-of-thought prompting can close some gap
- Slower — can take tens of seconds
- Thinking tokens billed at output rate
- Hidden tokens multiply real cost 2-5x
- State-of-the-art on math, code, science, planning
- Little benefit added by CoT prompting on top
| Task type | Recommended model |
|---|---|
| Short factual answer | Standard |
| Summarisation or rewriting | Standard |
| Customer support reply | Standard |
| Multi-step math or science | Reasoning |
| Complex code generation or review | Reasoning |
| Legal/contract analysis with rubric | Reasoning |
| Agentic tool-use planning | Reasoning |
| Creative writing | Standard (reasoning adds little) |
| Simple classification | Standard |
| Debugging a subtle logic error | Reasoning |
Research has found that reasoning models can generate more than 100 times the tokens of a standard model on the same prompt, and incur over 20 times the latency. That's fine for a nightly code-review job; it's crippling for a real-time chat widget. Match the tool to the latency and cost budget.
Pitfalls and gotchas
Reasoning models are powerful but they introduce several failure modes that don't exist with standard models.
Over-thinking easy problems
Set reasoning_effort to high or budget_tokens to 32k on a question like "What is the capital of France?" and the model may spin through thousands of tokens of unnecessary verification before answering "Paris." You pay for all of it. Effort/budget knobs exist precisely to prevent this — calibrate them per task type, not globally.
Thinking tokens are still billed even when wrong
A high thinking budget does not guarantee a correct answer — it makes correct answers more likely on hard tasks. If the model still gets it wrong after 10,000 thinking tokens, you pay for the thinking and the wrong answer. Validate outputs, especially in automated pipelines.
Don't add chain-of-thought instructions on top of reasoning models
Prompting a reasoning model with "think step by step" or "reason before answering" is redundant — the model already does this internally. In some cases explicit CoT instructions interfere with the model's built-in reasoning strategy, producing worse results. Let the thinking budget do its job; use your prompt tokens for instructions, constraints, and context instead.
Interleaved thinking and streaming
Claude's API supports interleaved thinking (beta as of 2025), where thinking blocks alternate with text blocks across a multi-step agentic turn. When max_tokens is above about 21,000, the Anthropic SDK requires streaming — a synchronous request that long will time out. For thinking budgets above 32k, batch processing is recommended over live requests.
Going deeper
How reasoning models are trained. The thinking capability is not just switched on at inference time — it is trained in. OpenAI's o1 paper describes reinforcement learning where the model is rewarded for producing reasoning traces that lead to verifiably correct answers on math and code tasks. Over many training steps the model learns to hone its chain of thought, recognize mistakes early, and allocate more thinking to harder sub-problems. The specific content of the internal reasoning is intentionally opaque: OpenAI and Anthropic do not expose the full trace to prevent gaming the reward signal.
Scaling laws for thinking. Accuracy on math benchmarks improves roughly logarithmically with the number of thinking tokens allocated, which means doubling the budget gives diminishing returns. Practical implication: there is often a sweet spot — a budget that captures most of the accuracy gain at a fraction of the maximum cost. Profile your specific task with a small eval set at budget levels of 1k, 4k, 16k, and 64k before committing to a default.
Adaptive thinking. Claude Opus 4 introduced effort controls (low, high, xhigh, max) and adaptive thinking, where the model decides internally how much reasoning to spend based on perceived task complexity, rather than always consuming the full budget_tokens. This further reduces waste on mixed-difficulty workloads.
Test-time compute scaling. Reasoning models are a concrete example of a broader research direction: scaling inference-time compute rather than only training-time compute. The original Transformer scaling laws focused on parameters and training tokens. Reasoning models show that you can trade inference FLOPs for quality independently — a smaller model thinking for a long time can match a larger model answering instantly. This opens architectures that are parameter-efficient but inference-expensive, which is a meaningful shift for deployment economics.
Where the field is heading. Three threads to watch: latent reasoning (performing the step-by-step computation in hidden activations rather than token sequences, trading interpretability for speed), verifier-guided search (using a separate model or formal checker to score candidate reasoning traces and select the best), and speculative thinking (drafting a cheap reasoning pass with a small model, then refining only the uncertain steps with an expensive one). The thinking-token paradigm established in 2024 is still early; the mechanisms for controlling it are actively improving every quarter.
FAQ
Are reasoning models the same as chain-of-thought prompting?
They share the same root idea — spend tokens reasoning before answering — but they are different mechanisms. Chain-of-thought is something you elicit with words in a prompt; the reasoning appears as visible output text. Reasoning models generate private thinking tokens through a trained behavior, not a prompt instruction. The thinking is hidden, controlled via API parameters, and does not pollute your response.
Do I get charged for thinking tokens I never see?
Yes. Thinking tokens and reasoning tokens are billed at the output token rate even though they are not returned to you. A typical extended-thinking request might use 2-5x more tokens than the visible answer alone. Check the usage object in the API response — completion_tokens_details on OpenAI and the usage field on Anthropic both break out the thinking token count.
Can I read the thinking trace to debug my prompts?
On Anthropic models the thinking trace is returned as thinking blocks in the response content array, so you can log and inspect it. On OpenAI's GPT-5 series the reasoning tokens are not returned — you only see the total count in the usage object. In both cases the trace is a useful debugging aid but not a guaranteed faithful record of every step the model took internally.
How do I choose between `reasoning_effort` low / medium / high on OpenAI models?
Start at medium (the default in ChatGPT). Use low for tasks that are fast and cheap to iterate on, or where latency is critical. Use high only for tasks where your eval set shows a meaningful accuracy improvement over medium — the cost and latency jump substantially. On AIME 2024 math problems, for example, moving from low to high raises accuracy by roughly 10-30 percentage points, which is worth it. For a customer-service summarisation task the gap is typically negligible.
Do reasoning models make prompt engineering obsolete?
No. Clear task instructions, well-structured context, relevant examples, and output format constraints all still matter — the model needs to understand what problem it is reasoning about. What reasoning models do reduce is the need for explicit "think step by step" phrases and elaborate CoT scaffolding; those are superseded by the built-in thinking budget. Good prompting and good thinking budgets are complementary, not competing.
When should I use a reasoning model inside an agent vs a standard model?
Use a reasoning model for the planning and decision steps of an agent — choosing which tools to call, in what order, with what arguments, and how to interpret results. Use a standard model for fast-turnaround sub-tasks like extracting a value from a JSON blob, formatting output, or generating short text. A common pattern is a reasoning model as the "orchestrator" and standard models as cheap "worker" nodes.