
Overview
Claude Sonnet 4.6 is Anthropic's mid-tier model released on February 17, 2026, and it became the default model on the Free and Pro plans at claude.ai and Claude Cowork on launch day. It is a hybrid reasoning model: it can answer quickly or use adaptive (extended) thinking for harder problems, and its depth is tunable through the effort parameter.
The headline of Sonnet 4.6 is that it closes much of the gap to flagship models. In Anthropic's early testing, developers preferred Sonnet 4.6 over Sonnet 4.5 by a wide margin, and even preferred it to the larger Opus 4.5 model 59% of the time. It posts 79.6% on SWE-bench Verified and 72.5% on OSWorld for computer use, within a point or two of Opus 4.6 on those developer-facing tasks, while keeping the same $3 / $15 per million token pricing as Sonnet 4.5.
Sonnet 4.6 ships with a 1 million token context window in beta, 64K max output tokens, and supports text and image (vision) input. It is available through claude.ai, Claude Code, the Claude API, Claude Platform on AWS, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry.
| Released | 2026-02-17 |
|---|---|
| License | Proprietary |
| Weights | API only |
| Context | 1M |
| Max output | 64K |
| Architecture | Proprietary transformer; hybrid reasoning model with adaptive (extended) thinking and effort control. |
| Knowledge cutoff | August 2025 |
| Modalities | Text, Vision, PDF |
| Status | Generally available |
Benchmarks
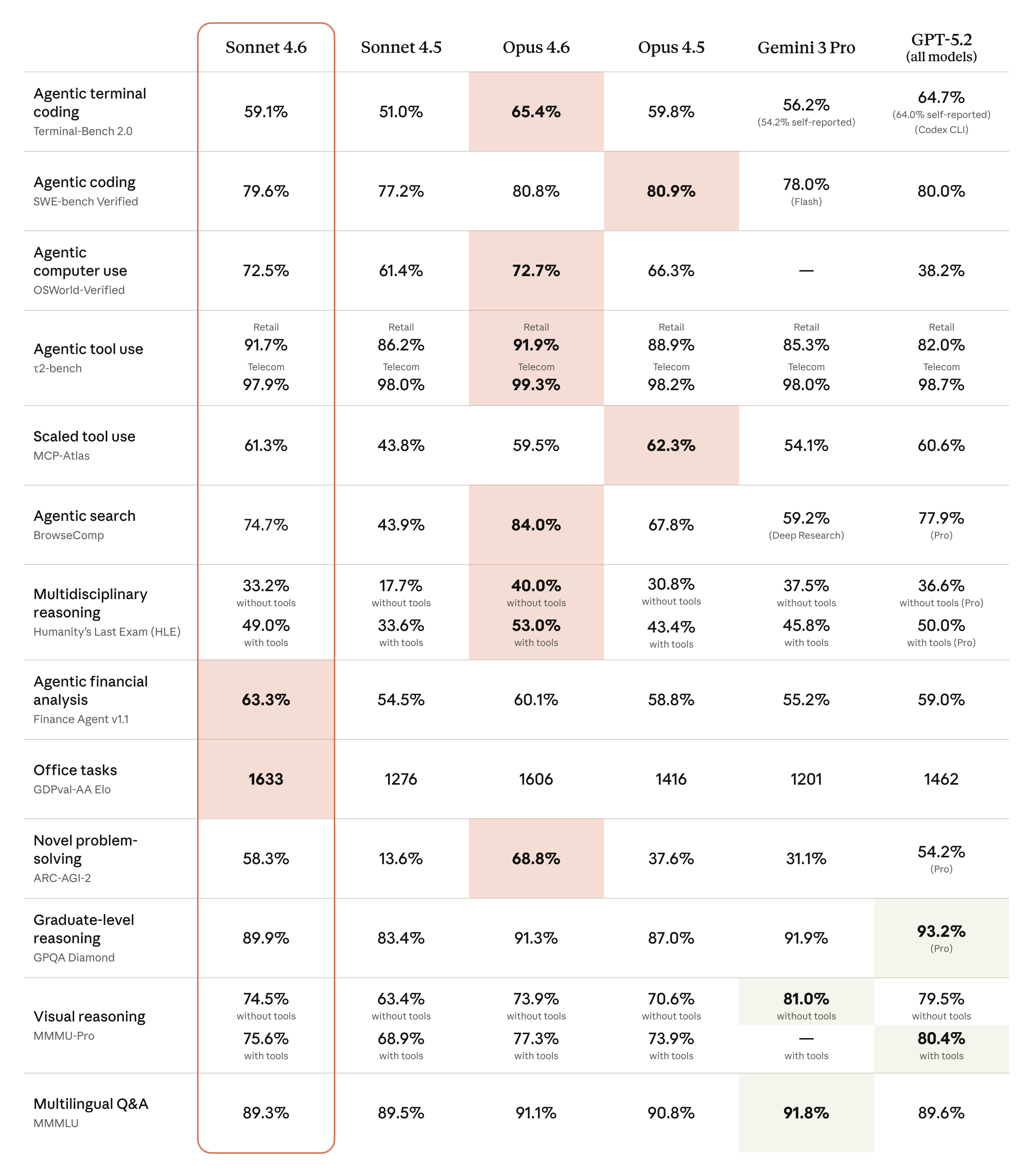
Claude Sonnet 4.6 benchmark comparison vs. Sonnet 4.5, Opus 4.6, Opus 4.5, Gemini 3 Pro, and GPT-5.2 (as published by Anthropic).
| Benchmark | Sonnet 4.6 | Sonnet 4.5 | Opus 4.6 | Opus 4.5 | Gemini 3 Pro | GPT-5.2 |
|---|---|---|---|---|---|---|
| Agentic terminal coding (Terminal-Bench 2.0) | 59.1% | 51% | 65.4% | 59.8% | 56.2% | 64.7% |
| Agentic coding (SWE-bench Verified) | 79.6% | 77.2% | 80.8% | 80.9% | 78% | 80% |
| Agentic computer use (OSWorld-Verified) | 72.5% | 61.4% | 72.7% | 66.3% | — | 38.2% |
| Agentic tool use (t2-bench, Retail) | 91.7% | 86.2% | 91.9% | 88.9% | 85.3% | 82% |
| Agentic tool use (t2-bench, Telecom) | 97.9% | 98% | 99.3% | 98.2% | 96.8% | 98.7% |
| Scaled tool use (MCP-Atlas) | 61.3% | 43.8% | 59.5% | 62.3% | 54.1% | 60.6% |
| Agentic search (BrowseComp) | 74.7% | 43.9% | 84% | 67.8% | 59.2% | 77.9% |
| Multidisciplinary reasoning (Humanity's Last Exam, without tools) | 33.2% | 17.7% | 40% | 30.8% | 37.5% | 36.6% |
| Multidisciplinary reasoning (Humanity's Last Exam, with tools) | 49% | 33.6% | 53% | 43.4% | 45.8% | 50% |
| Agentic financial analysis (Finance Agent v1.1) | 63.3% | 54.5% | 60.1% | 58.8% | 55.2% | 59% |
| Office tasks (GDPval-AA-Elo) | 1633 Elo | 1276 Elo | 1606 Elo | 1416 Elo | 1201 Elo | 1462 Elo |
| Novel problem-solving (ARC-AGI-2) | 58.3% | 13.6% | 68.8% | 37.6% | 31.1% | 54.2% |
| Graduate-level reasoning (GPQA Diamond) | 89.9% | 83.4% | 91.3% | 87% | 91.9% | 93.2% |
| Visual reasoning (MMMU-Pro, without tools) | 74.5% | 63.4% | 73.9% | 70.6% | 81% | 79.5% |
| Visual reasoning (MMMU-Pro, with tools) | 75.6% | 68.9% | 77.3% | 73.9% | — | 80.4% |
| Multilingual Q&A (MMMU) | 89.3% | 89.5% | 91.1% | 90.8% | 91.8% | 89.6% |
This model's scores
- SWE-bench Verified79.6%
- OSWorld (computer use)72.5%
- Terminal-Bench 2.059.1%
- GPQA Diamond74.1%
- ARC-AGI-260.4%
Scores on a 0–100 scale (25-point gridlines); higher is better. Each benchmark links to its published source.
Pricing
| Input | $3.00 per million tokens |
|---|---|
| Output | $15.00 per million tokens |
Same pricing as Sonnet 4.5. Prompt caching and Batch API discounts available.
Strengths
- Near-Opus coding and computer-use quality at one-fifth of Opus pricing
- 1M token context window (beta) for large-codebase and long-document work
- Adaptive thinking plus effort control (low/medium/high/max) to trade off speed vs depth
- Strong long-horizon agent planning and instruction following
- Default model for Free/Pro tiers, so the most broadly available capable Claude
Best for
- Agentic coding and large-scale refactors in Claude Code and IDE integrations
- Computer-use and browser/desktop automation agents
- Long-context document analysis and knowledge work over the 1M-token window
- Customer support and tool-using assistants that need fast, cheap, capable responses
- Office and analyst tasks (spreadsheets, reports, research) that previously needed an Opus-class model
How to access
| Provider | Model ID |
|---|---|
| Anthropic ↗ | claude-sonnet-4-6 |
| Amazon Bedrock ↗ | anthropic.claude-sonnet-4-6 |
| Google Vertex AI ↗ | claude-sonnet-4-6 |
Claude Sonnet — every version
The full lineage of the Claude Sonnet line, newest first. Every version has its own page — click any to compare specs, benchmarks and pricing.
| Version | Released | Context | License |
|---|---|---|---|
| Claude Sonnet 4.6current | 2026-02-17 | 1M | Proprietary |
| Claude Sonnet 4.5 | 2025-09-29 | 1M | Proprietary |
| Claude Sonnet 4 | 2025-05-22 | 200K | Proprietary |
| Claude 3.7 Sonnet | 2025-02-24 | 200K | Proprietary |
| Claude 3.5 Sonnet (new) | 2024-10-22 | 200K | Proprietary |
| Claude 3.5 Sonnet | 2024-06-20 | 200K | Proprietary |
| Claude 3 Sonnet | 2024-03-04 | 200K | Proprietary |
FAQ
What is the model ID for Claude Sonnet 4.6?
On the Claude API it is claude-sonnet-4-6. On Amazon Bedrock it is anthropic.claude-sonnet-4-6, and on Vertex AI it is claude-sonnet-4-6.
How much does Claude Sonnet 4.6 cost?
It is $3 per million input tokens and $15 per million output tokens, the same pricing as Sonnet 4.5. Prompt caching and Batch API discounts can lower this further.
What is the context window?
Sonnet 4.6 has a 1 million token context window (in beta) and supports up to 64K output tokens on the standard Messages API.
How does Sonnet 4.6 compare to Opus 4.6?
On developer-facing tasks like SWE-bench Verified (79.6%) and OSWorld (72.5%), Sonnet 4.6 lands within one to two points of Opus 4.6 while costing one-fifth as much per token.