
Overview
Gemini 3.5 Flash is Google's fast, cost-efficient model in the Gemini Flash line, announced at Google I/O 2026 and made generally available on May 19, 2026 as the API model gemini-3.5-flash. It is the current flagship of the Flash tier, positioned as Google's most intelligent model for sustained agentic and coding work, and it is the first Flash-tier model to outperform a previous Pro tier (Gemini 3.1 Pro) on Google's published coding and agentic benchmarks.
Gemini 3.5 Flash accepts text, images, audio, video, and PDFs/documents as input and returns text, with a 1 million-token context window and up to roughly 64K output tokens. Reasoning depth is adjustable through a thinking_level setting (minimal, low, medium, high), and Google reports the model delivers output around four times faster than other frontier models, making it well suited to high-throughput agent and tool-use loops.
The model is available through the Gemini API, Google AI Studio, Vertex AI, the Gemini app, Google Search AI Mode, and Google's Antigravity agentic IDE, and it is selectable in third-party tools such as Cursor. Its knowledge cutoff is January 2025; for newer information Google recommends the built-in search grounding tool.
| Released | 2026-05-19 |
|---|---|
| License | Proprietary |
| Weights | API only |
| Parameters | Not disclosed |
| Context | 1M |
| Max output | 64K |
| Architecture | Multimodal Gemini model built on Gemini 3 Flash. Reasoning depth is controllable through a thinking_level parameter (minimal, low, medium, high; medium is the default) rather than a numeric token budget, and the model dynamically allocates more compute to harder problems. It preserves intermediate reasoning across turns ("thought preservation") and natively supports function calling, structured output, code execution, and search grounding. Google has not disclosed the parameter count. |
| Knowledge cutoff | January 2025 |
| Modalities | Text, Vision, Audio, Video, PDF |
| Status | Generally available |
Benchmarks
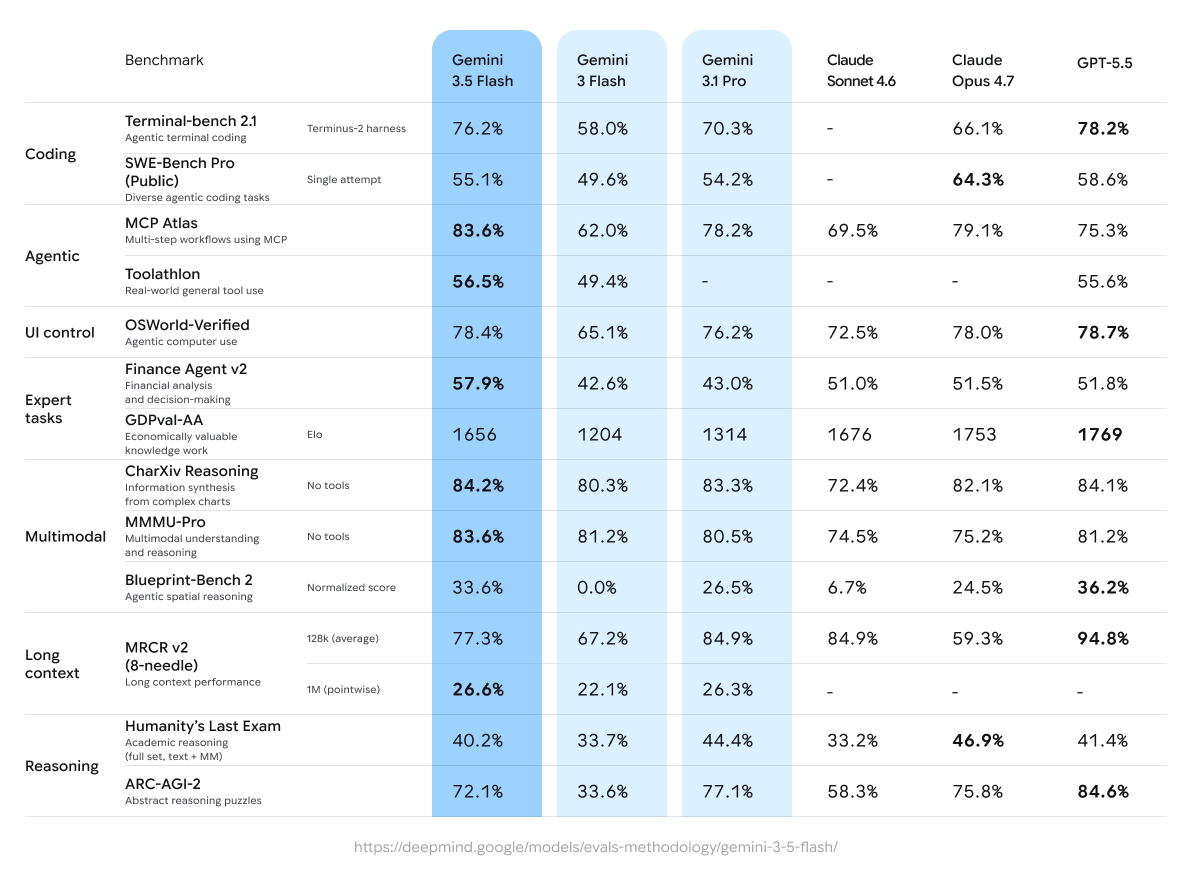
Gemini 3.5 Flash benchmark comparison (results as of May 2026).
| Benchmark | Gemini 3.5 Flash | Gemini 3 Flash | Gemini 3.1 Pro | Claude Sonnet 4.6 | Claude Opus 4.7 | GPT-5.5 |
|---|---|---|---|---|---|---|
| Terminal-bench 2.1 (Agentic terminal coding, Terminus-2 harness) | 76.2% | 58% | 70.3% | — | 66.1% | 78.2% |
| SWE-Bench Pro (Public) (Diverse agentic coding tasks, single attempt) | 55.1% | 49.6% | 54.2% | — | 64.3% | 58.6% |
| MCP Atlas (Multi-step workflows using MCP) | 83.6% | 62% | 78.2% | 69.5% | 79.1% | 75.3% |
| Toolathlon (Real-world general tool use) | 56.5% | 49.4% | — | — | — | 55.6% |
| OSWorld-Verified (Agentic computer use) | 78.4% | 65.1% | 76.2% | 72.5% | 78% | 78.7% |
| Finance Agent v2 (Financial analysis and decision-making) | 57.9% | 42.6% | 43% | 51% | 51.5% | 51.8% |
| GDPval-AA (Economically valuable knowledge work) | 1656 Elo | 1204 Elo | 1314 Elo | 1676 Elo | 1753 Elo | 1769 Elo |
| CharXiv (Information synthesis from complex charts, no tools) | 84.2% | 80.3% | 83.3% | 72.4% | 82.1% | 84.1% |
| MMMU-Pro (Multimodal understanding and reasoning, no tools) | 83.6% | 81.2% | 80.5% | 74.5% | 75.2% | 81.2% |
| Blueprint-Bench 2 (Agentic spatial reasoning, normalized score) | 33.6% | 0% | 26.5% | 6.7% | 24.5% | 36.2% |
| MRCR v2 (8-needle) (Long context 128k, average) | 77.3% | 67.2% | 84.9% | 84.9% | 59.3% | 94.8% |
| MRCR v2 (1M) (Long context 1M, pointwise) | 26.6% | 22.1% | 26.3% | — | — | — |
| Humanity's Last Exam (Academic reasoning, full set, text + MM) | 40.2% | 33.7% | 44.4% | 33.2% | 46.9% | 41.4% |
| ARC-AGI-2 (Abstract reasoning puzzles) | 72.1% | 33.6% | 77.1% | 58.3% | 75.8% | 84.6% |
This model's scores
- Terminal-Bench 2.1 (agentic coding)76.2%
- SWE-Bench Pro55.1%
- MCP Atlas (multi-step workflows)83.6%
- MMMU-Pro (multimodal reasoning)83.6%
- ARC-AGI-272.1%
- CharXiv Reasoning (chart understanding)84.2%
- Artificial Analysis Intelligence Index55%
Scores on a 0–100 scale (25-point gridlines); higher is better. Each benchmark links to its published source.
Pricing
| Input | $1.50 / 1M tokens per 1M tokens |
|---|---|
| Cached input | $0.15 / 1M tokens per 1M tokens |
| Output | $9.00 / 1M tokens per 1M tokens |
Paid tier; output price includes thinking tokens. Context caching also incurs $1.00 per 1M tokens per hour of storage. A free tier is available with usage limits.
Strengths
- Frontier agentic and coding performance that surpasses Gemini 3.1 Pro on Terminal-Bench 2.1, MCP Atlas, and Finance Agent v2
- Very high output speed (Artificial Analysis measured ~280+ tokens/sec, roughly 70% faster than Gemini 3 Flash)
- 1 million-token context window for long-document and multi-file reasoning
- Native multimodal input across text, image, audio, video, and PDF
- Controllable reasoning via thinking_level plus dynamic compute allocation
- Built-in tool use: function calling, structured output, code execution, and search grounding
Best for
- Coding agents and autonomous multi-step software tasks (e.g. terminal and SWE-style workflows)
- Tool-using and MCP-driven agents that need fast, cheap iterations
- Long-context document analysis and summarization across up to 1M tokens
- Multimodal understanding of charts, images, audio, and video
- High-volume production workloads where latency and cost matter
- Structured data extraction and function-calling pipelines
How to access
| Provider | Model ID |
|---|---|
| Google Gemini API ↗ | gemini-3.5-flash |
| Google Vertex AI ↗ | gemini-3.5-flash |
| OpenRouter ↗ | google/gemini-3.5-flash |
Gemini Flash — every version
The full lineage of the Gemini Flash line, newest first. Every version has its own page — click any to compare specs, benchmarks and pricing.
| Version | Released | Context | License |
|---|---|---|---|
| Gemini 3.5 Flashcurrent | 2026-05-19 | — | Proprietary |
| Gemini 3 Flash | 2025-12-17 | — | Proprietary |
| Gemini 2.5 Flash | 2025-04-17 | — | Proprietary |
| Gemini 2.0 Flash | 2025-01-30 | — | Proprietary |
| Gemini 1.5 Flash | 2024-05-14 | — | Proprietary |
FAQ
When was Gemini 3.5 Flash released?
Google announced Gemini 3.5 Flash at Google I/O 2026 and made it generally available on May 19, 2026, as the API model gemini-3.5-flash.
What is the context window and output limit of Gemini 3.5 Flash?
It has a 1 million-token input context window and can produce up to about 64K output tokens. It accepts text, images, audio, video, and PDFs as input and returns text.
How much does Gemini 3.5 Flash cost?
On the paid tier it is $1.50 per 1M input tokens and $9.00 per 1M output tokens (output includes thinking tokens), with cached input at $0.15 per 1M tokens. A free tier with usage limits is also available.
How does Gemini 3.5 Flash compare to Gemini 3.1 Pro?
It is the first Flash-tier model to beat a previous Pro tier on Google's published benchmarks, outperforming Gemini 3.1 Pro on Terminal-Bench 2.1, MCP Atlas, and Finance Agent v2 while running roughly four times faster.