
Overview
Gemma 4 is Google DeepMind's open-weight model family, released on April 2, 2026 under a commercially permissive Apache 2.0 license. It spans five sizes for different deployment targets: the on-device E2B (2.3B effective) and E4B (4.5B effective) models, a 12B encoder-free unified multimodal model, a 26B Mixture-of-Experts model that activates only ~3.8B parameters at inference, and a 31B dense flagship (30.7B parameters). Weights are downloadable from Hugging Face, Kaggle and Ollama, with day-one support across transformers, llama.cpp, vLLM, MLX and LiteRT-LM.
The 31B dense model is the flagship of the line. It accepts text and image input (with variable resolution), generates text output, and offers a 256K-token context window. Across the family, all models natively process images and video; the smaller E2B, E4B and 12B unified models add native audio input for speech recognition and understanding. Gemma 4 is trained on over 140 languages and ships with native function calling, configurable thinking modes and system-prompt support.
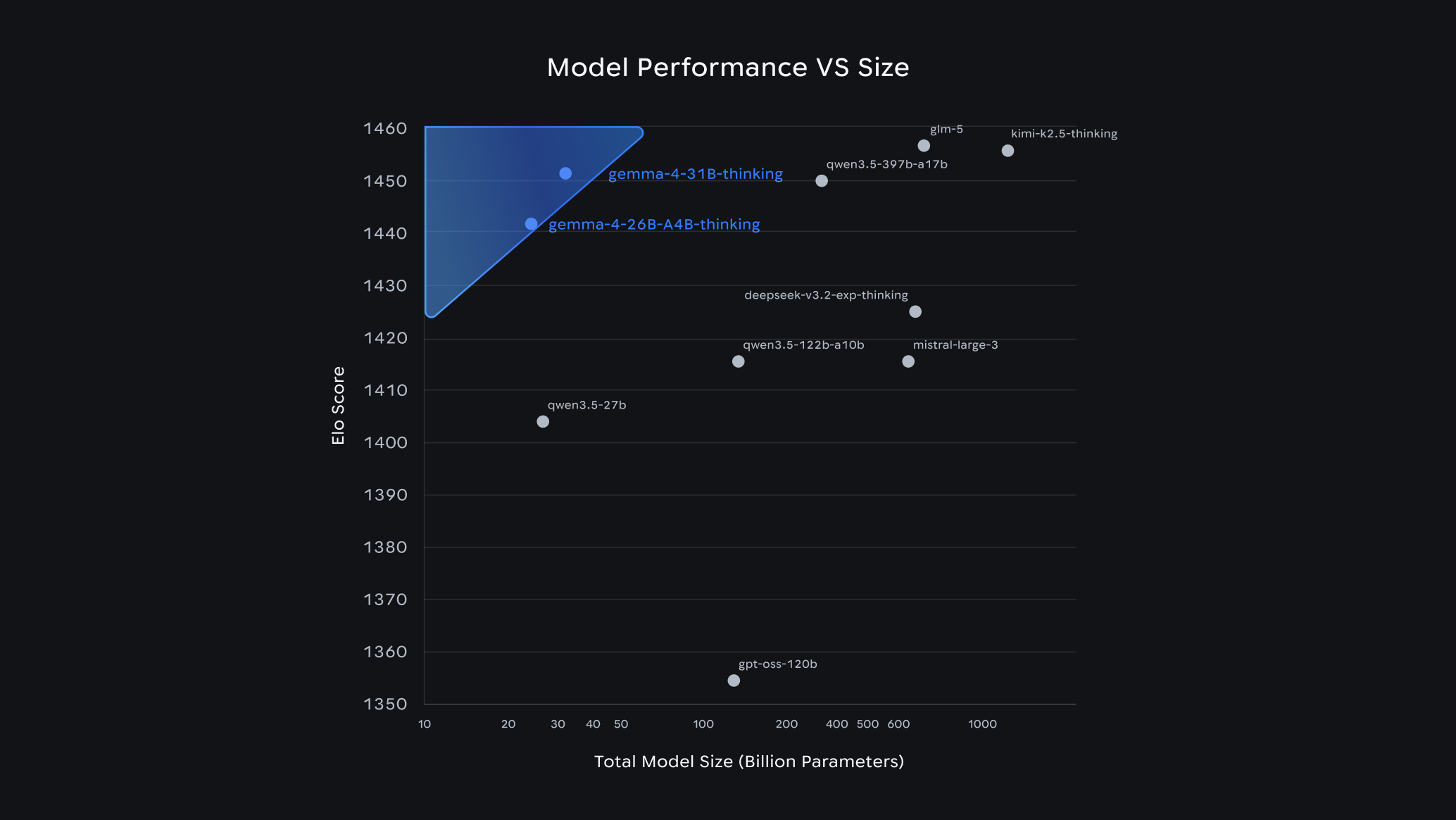
Despite their open weights and modest footprint, Gemma 4 models punch above their size: Google reports the 31B as a top-3 open model on the LMArena text leaderboard and the 26B MoE at #6, and the unquantized bfloat16 31B weights fit on a single 80GB NVIDIA H100. The recommended sampling settings are temperature 1.0, top_p 0.95 and top_k 64. The knowledge cutoff is January 2025.
| Released | 2026-04-02 |
|---|---|
| License | Apache 2.0 |
| Weights | Open weights |
| Parameters | 30.7B (31B dense flagship); family spans E2B/E4B on-device, 12B unified, 26B MoE (3.8B active) |
| Context | 256K |
| Architecture | Decoder-only transformer with hybrid attention that interleaves local sliding-window and full global attention (final layer always global). The flagship is a 30.7B dense model; the family also includes a 26B Mixture-of-Experts variant (128 experts, 8 active + 1 shared, ~3.8B active params), a 12B encoder-free "unified" model that projects raw image patches and audio waveforms directly into the embedding space, and E2B/E4B on-device models using Per-Layer Embeddings (PLE). Global layers use unified KV and Proportional RoPE (p-RoPE). |
| Knowledge cutoff | January 2025 |
| Modalities | Text, Vision, Audio, Video |
| Status | Available |
Benchmarks
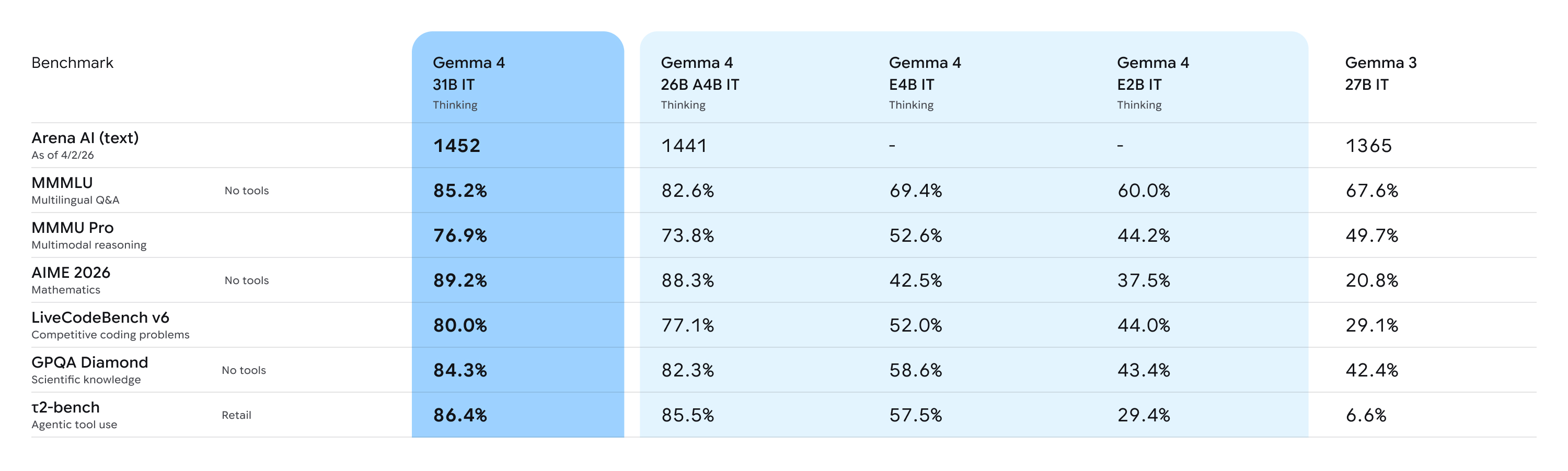
Gemma 4 benchmark comparison across Gemma 4 variants and Gemma 3 27B IT (Google blog table).
| Benchmark | Gemma 4 31B IT (Thinking) | Gemma 4 26B A4B IT (Thinking) | Gemma 4 E4B IT (Thinking) | Gemma 4 E2B IT (Thinking) | Gemma 3 27B IT |
|---|---|---|---|---|---|
| Arena AI (text), as of 4/2/26 | 1452 Elo | 1441 Elo | — | — | 1365 Elo |
| MMMLU (Multilingual Q&A, no tools) | 85.2% | 82.6% | 69.4% | 60% | 67.6% |
| MMMU Pro (Multimodal reasoning) | 76.9% | 73.8% | 52.6% | 44.2% | 49.7% |
| AIME 2026 (Mathematics, no tools) | 89.2% | 88.3% | 42.5% | 37.5% | 20.8% |
| LiveCodeBench v6 (Competitive coding) | 80% | 77.1% | 52% | 44% | 29.1% |
| GPQA Diamond (Scientific knowledge, no tools) | 84.3% | 82.3% | 58.6% | 43.4% | 42.4% |
| τ2-bench (Agentic tool use, Retail) | 86.4% | 85.5% | 57.5% | 29.4% | 6.6% |
This model's scores
- AIME 2026 (math, no tools)89.2%
- GPQA Diamond84.3%
- MMLU Pro85.2%
- LiveCodeBench v680%
- MMMU Pro (Vision)76.9%
- MRCR v2 (Long Context)66.4%
Scores on a 0–100 scale (25-point gridlines); higher is better. Each benchmark links to its published source.
Pricing
| Input | $0.12 / 1M tokens per 1M tokens (gemma-4-31b-it via OpenRouter; weights are free to self-host) |
|---|---|
| Output | $0.35 / 1M tokens per 1M tokens (gemma-4-31b-it via OpenRouter; weights are free to self-host) |
Gemma 4 weights are open and free to download and self-host under Apache 2.0. The listed price is a hosted-inference rate for the 31B instruct model on OpenRouter; rates vary by provider (Artificial Analysis lists blended prices from ~$0.08/1M). Google had not added Gemma 4 to the Vertex AI managed pricing list at launch.
Strengths
- Truly open weights under a permissive Apache 2.0 license, allowing commercial use, fine-tuning and self-hosting without a custom Gemma license
- One family covers the full deployment range — from browser/edge (E2B/E4B) to consumer GPUs and a single H100 (31B)
- Strong reasoning and math for its size (89.2% AIME 2026, 84.3% GPQA Diamond on the 31B) plus competitive coding scores
- 256K-token context on the larger models for long-document and long-context tasks
- Native multimodal input (image + video across the family; audio on E2B/E4B/12B) and 140+ language coverage
- Day-one ecosystem support: Hugging Face transformers, llama.cpp, vLLM, MLX, Ollama, LiteRT-LM
- Efficient MoE option (26B with ~3.8B active) and PLE-based on-device models for low-memory inference
Best for
- Self-hosted and on-premise LLM deployments where data must stay private
- On-device and edge AI (mobile, browser) using the E2B/E4B models
- Fine-tuning a capable base/instruct model for domain-specific tasks under a permissive license
- Multimodal applications that need image, video or audio understanding
- Long-context document analysis and retrieval-augmented generation with the 256K window
- Math, reasoning and coding assistants built on open weights
- Multilingual applications spanning 140+ languages
How to access
| Provider | Model ID |
|---|---|
| OpenRouter ↗ | google/gemma-4-31b-it |
| Hugging Face ↗ | google/gemma-4-31B |
| Ollama ↗ | gemma4 |
| NVIDIA NIM ↗ | google/gemma-4-31b-it |
Gemma (open weights) — every version
The full lineage of the Gemma (open weights) line, newest first. Every version has its own page — click any to compare specs, benchmarks and pricing.
FAQ
Is Gemma 4 open source and free to use commercially?
Gemma 4 is released as open-weight under the Apache 2.0 license, which permits commercial use, redistribution, fine-tuning and self-hosting. Unlike earlier Gemma releases that used a custom Gemma license, Apache 2.0 gives enterprises broad flexibility. The weights are free to download from Hugging Face, Kaggle and Ollama; you only pay for compute (your own or a hosted provider).
What sizes does Gemma 4 come in?
Five sizes: E2B (2.3B effective) and E4B (4.5B effective) for on-device and edge use, a 12B encoder-free unified multimodal model, a 26B Mixture-of-Experts model that activates ~3.8B parameters at inference, and a 31B dense flagship (30.7B parameters). The E2B/E4B models have a 128K context window; the 12B, 26B and 31B models support 256K.
What modalities and languages does Gemma 4 support?
All Gemma 4 models natively process text, images and video; the E2B, E4B and 12B unified models additionally accept audio input. Output is text only. The models are trained on over 140 languages and include native function calling, configurable thinking modes and system-prompt support.
How good is Gemma 4 compared with larger models?
The 31B flagship scores 89.2% on AIME 2026, 84.3% on GPQA Diamond, 85.2% on MMLU Pro and 80.0% on LiveCodeBench v6 per Google's model card, and Google reports it as a top-3 open model on the LMArena text leaderboard. The unquantized 31B fits on a single 80GB H100, and the 26B MoE delivers similar quality with only ~3.8B active parameters.