
Overview
GLM-5.2 is Z.ai's flagship open-weight foundation model, released in June 2026 under the MIT license. It is a Mixture-of-Experts model (744B total / 40B active parameters per Artificial Analysis) built for long-horizon tasks, and ships with a 1M-token context window — up from 200K on GLM-5.1.
The model is positioned for project-scale engineering: Z.ai reports it can sustain long, messy coding-agent trajectories, adhere more reliably to engineering standards, and achieve higher success rates in development scenarios. It exposes multiple thinking-effort levels to trade off latency against accuracy.
On the Artificial Analysis Intelligence Index, GLM-5.2 became the leading open-weights model, scoring 51 and sitting on the Pareto frontier of intelligence versus cost per task. It is available through Z.ai's API and Coding Plan and as open weights on the zai-org Hugging Face repository.
| Released | 2026-06-16 |
|---|---|
| License | MIT |
| Weights | Open weights |
| Parameters | 744B total · 40B active |
| Context | 1M |
| Max output | 128K |
| Architecture | Mixture-of-Experts |
| Modalities | Text |
| Status | Available |
Benchmarks
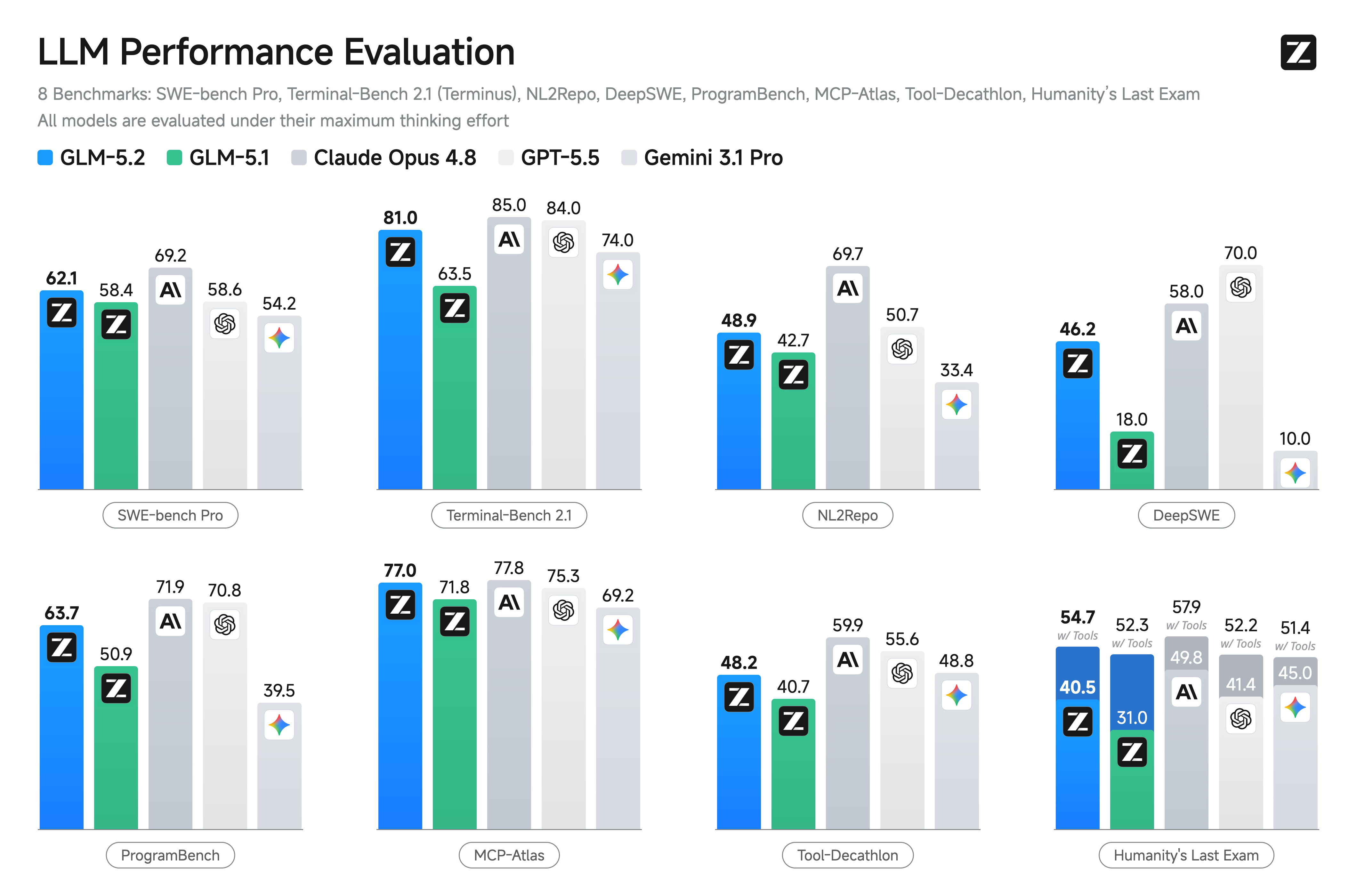
GLM-5.2 vs peers across reasoning, coding and agentic benchmarks (official Z.ai launch table). All models evaluated at their maximum thinking effort. * = third-party / vendor-reported figure as marked by Z.ai. Dashes are missing cells.
| Benchmark | GLM-5.2 | GLM-5.1 | Qwen3.7-Max | MiniMax M3 | DeepSeek-V4-Pro | Claude Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|---|---|---|---|
| HLE (Humanity's Last Exam) | 40.5% | 31% | 41.4% | 37% | 37.7% | 49.8% | 41.4% | 45% |
| HLE w/ Tools | 54.7% | 52.3% | 53.5% | — | 48.2% | 57.9% | 52.2% | 51.4% |
| CritPt | 20.9% | 4.6% | 13.4% | 3.7% | 12.9% | 20.9% | 27.1% | 17.7% |
| AIME 2026 | 99.2% | 95.3% | 97% | — | 94.6% | 95.7% | 98.3% | 98.2% |
| HMMT Nov. 2025 | 94.4% | 94% | 95% | 84.4% | 94.4% | 96.5% | 96.5% | 94.8% |
| HMMT Feb. 2026 | 92.5% | 82.6% | 97.1% | 84.4% | 95.2% | 96.7% | 96.7% | 87.3% |
| IMOAnswerBench | 91% | 83.8% | 90% | — | 89.8% | 83.5% | — | 81% |
| GPQA-Diamond | 91.2% | 86.2% | 90% | 93% | 90.1% | 93.6% | 93.6% | 94.3% |
| SWE-bench Pro | 62.1% | 58.4% | 60.6% | 59% | 55.4% | 69.2% | 58.6% | 54.2% |
| NL2Repo | 48.9% | 42.7% | 47.2% | 42.1% | 35.5% | 69.7% | 50.7% | 33.4% |
| DeepSWE | 46.2% | 18% | 18% | 20% | 8% | 58% | 70% | 10% |
| ProgramBench | 63.7% | 50.9% | — | — | 47.8% | 71.9% | 70.8% | 39.5% |
| Terminal-Bench 2.1 (Terminus-2) | 81% | 63.5% | 75% | 65% | 64% | 85% | 84% | 74% |
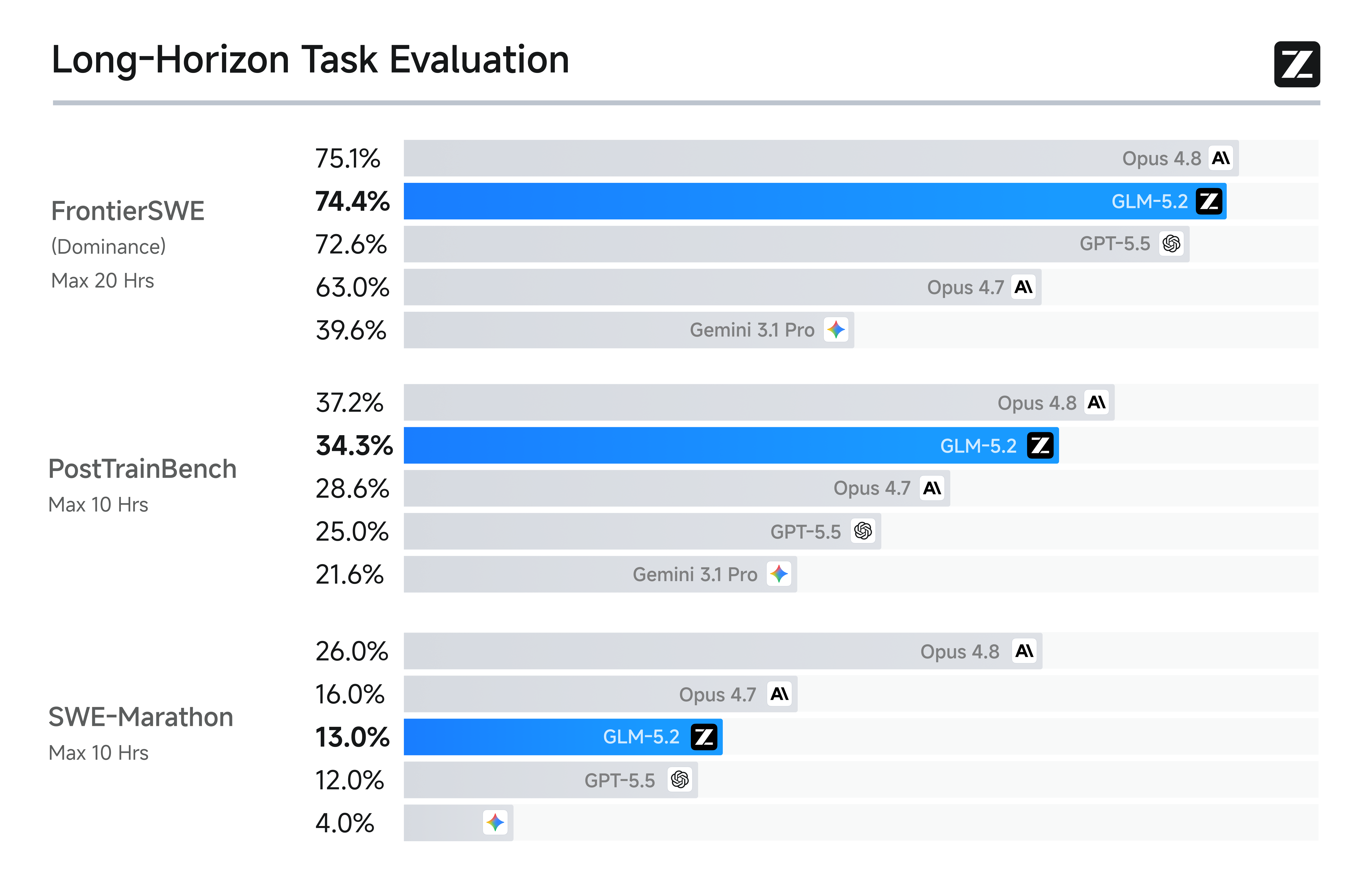
| FrontierSWE | 74.4% | 30.5% | — | — | 29% | 75.1% | 72.6% | 39.6% |
| PostTrainBench | 34.3% | 20.1% | — | — | — | 37.2% | 28.4% | 21.6% |
| SWE-Marathon | 13% | 1% | — | — | — | 26% | 12% | 4% |
| MCP-Atlas (Public Set) | 76.8% | 71.8% | 76.4% | 74.2% | 73.6% | 77.8% | 75.3% | 69.2% |
| Tool-Decathlon | 48.2% | 40.7% | — | — | 52.8% | 59.9% | 55.6% | 48.8% |
This model's scores
- AIME 202699.2%
- GPQA-Diamond91.2%
- SWE-bench Pro62.1%
- Terminal Bench 2.182.7%
- ProgramBench63.7%
- MCP-Atlas (Public Set)76.8%
Scores on a 0–100 scale (25-point gridlines); higher is better. Each benchmark links to its published source.
Pricing
| Input | $1.40 / 1M tokens |
|---|---|
| Cached input | $0.26 / 1M tokens |
| Output | $4.40 / 1M tokens |
Strengths
- Leading open-weights model on the Artificial Analysis Intelligence Index (score 51).
- 1M-token context that stably sustains long-horizon coding-agent work.
- Strong coding and software-engineering results (SWE-bench Pro 62.1, Terminal Bench 2.1 82.7).
- Strong math and reasoning (AIME 2026 99.2, GPQA-Diamond 91.2).
- Open weights under a permissive MIT license, enabling self-hosting.
Best for
- Long-horizon, project-scale coding agents over large repositories.
- Competition-grade math and scientific reasoning tasks.
- Agentic and tool-using applications needing very long context.
- Self-hosted deployments where MIT-licensed open weights are required.
How to access
| Provider | Model ID |
|---|---|
| Z.ai ↗ | glm-5.2 |
GLM (flagship) — every version
The full lineage of the GLM (flagship) line, newest first. Every version has its own page — click any to compare specs, benchmarks and pricing.
FAQ
What is GLM-5.2?
GLM-5.2 is Z.ai's flagship open-weight foundation model, released in June 2026 under the MIT license. It is a Mixture-of-Experts model with a 1M-token context window, built for long-horizon coding and reasoning tasks, and became the leading open-weights model on the Artificial Analysis Intelligence Index with a score of 51.
How long is GLM-5.2's context window?
GLM-5.2 supports a 1M-token context window, up from 200K on GLM-5.1, with a maximum output of 128K tokens. Z.ai reports the long context is stable enough to handle project-scale engineering context and sustain long, multi-step coding-agent trajectories rather than degrading on extended inputs.
How much does the GLM-5.2 API cost?
Per Artificial Analysis, GLM-5.2 is priced at $1.40 per million input tokens and $4.40 per million output tokens, with cached input at $0.26 per million tokens. It is also bundled into Z.ai's GLM Coding Plan, and the model is available as open weights on Hugging Face for self-hosting under the MIT license.
How does GLM-5.2 perform on benchmarks?
GLM-5.2 posts strong scores across coding and reasoning: SWE-bench Pro 62.1, Terminal Bench 2.1 82.7, ProgramBench 63.7, AIME 2026 99.2, and GPQA-Diamond 91.2. On the Artificial Analysis Intelligence Index v4.1 it scored 51, making it the leading open-weights model and placing it on the intelligence-versus-cost Pareto frontier.