
Overview
GLM-5V-Turbo is the multimodal vision model in Z.ai (Zhipu / GLM)'s GLM Turbo line, released 1 April 2026 and now the current flagship of that line. Unlike a text model with a bolt-on image reader, GLM-5V-Turbo treats visual perception as a core part of reasoning, planning and execution: it takes images, short video clips, design drafts and document layouts directly in context and produces code, structured actions or GUI steps as output.
The headline use case is vision-to-code. GLM-5V-Turbo is tuned to turn a design mockup, screenshot or product walkthrough into runnable front-end code, and it is explicitly integrated for agentic coding workflows such as OpenClaw and Claude Code. Architecturally it builds on the GLM-5-Turbo text base, adding the CogViT vision encoder and a Multimodal Multi-Token Prediction (MMTP) path so it keeps competitive text-only coding ability while gaining native multimodal grounding.
GLM-5V-Turbo is served only through Z.ai's API and chat platform — unlike the open-weights GLM-5 flagship, this Turbo vision variant ships proprietary with no published weights. It exposes a 200K-token context window and up to 128K tokens of output, supports thinking mode, streaming, function calling and context caching, and is priced at $1.20 per million input tokens and $4.00 per million output tokens.
| Released | 2026-04-01 |
|---|---|
| License | Proprietary (API-only) |
| Weights | API only |
| Context | 200K |
| Max output | 128K |
| Architecture | Native multimodal model built on the GLM-5-Turbo text base, pairing the CogViT vision encoder with a Multimodal Multi-Token Prediction (MMTP) decoding path. Trained with '30+ Task Joint Reinforcement Learning' spanning STEM reasoning, visual grounding, video analysis, document understanding, GUI interaction and tool use. Z.ai has not disclosed total or active parameter counts for this variant. |
| Knowledge cutoff | Not disclosed |
| Modalities | Text, Vision, Video, PDF |
| Status | Available |
Benchmarks
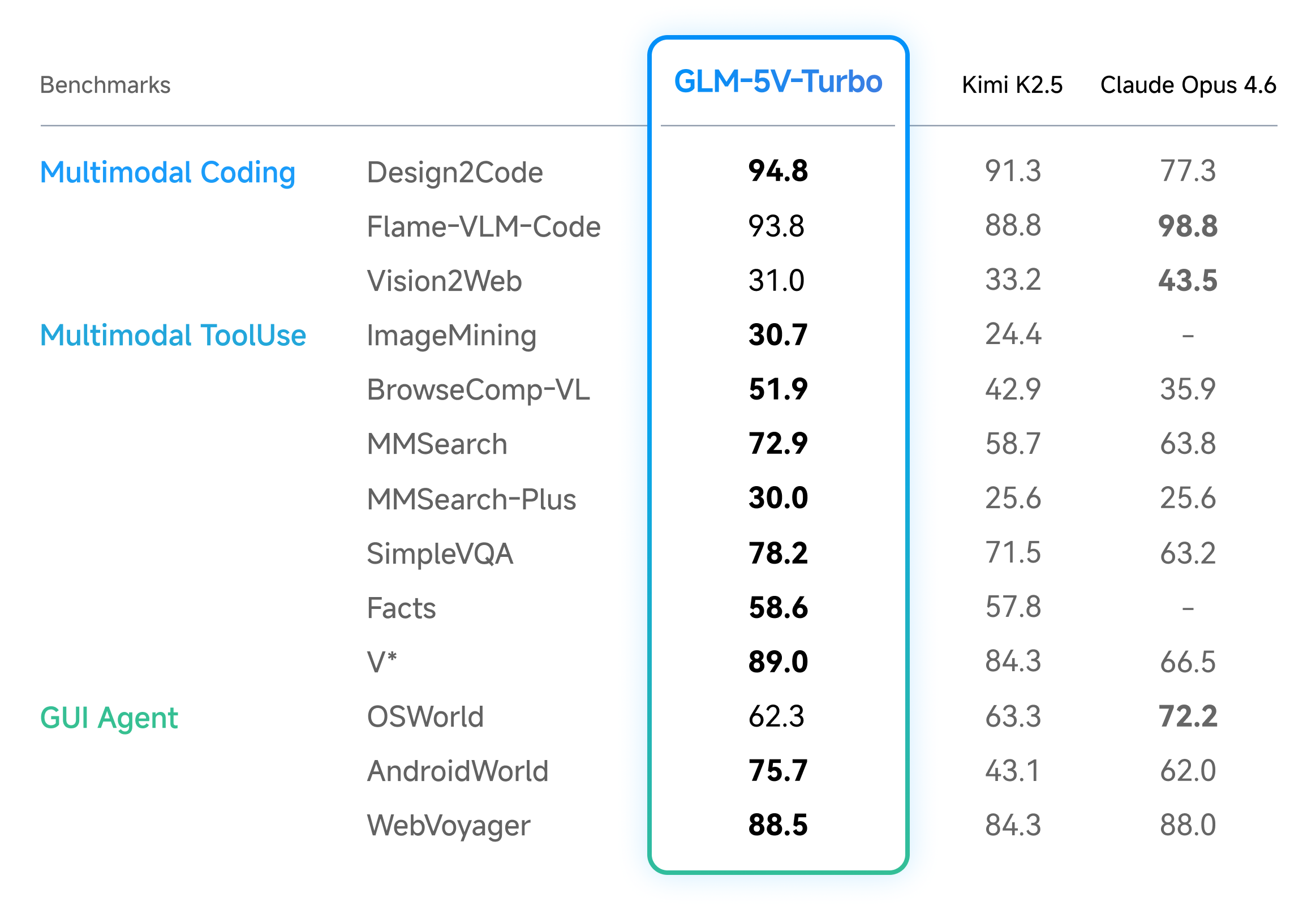
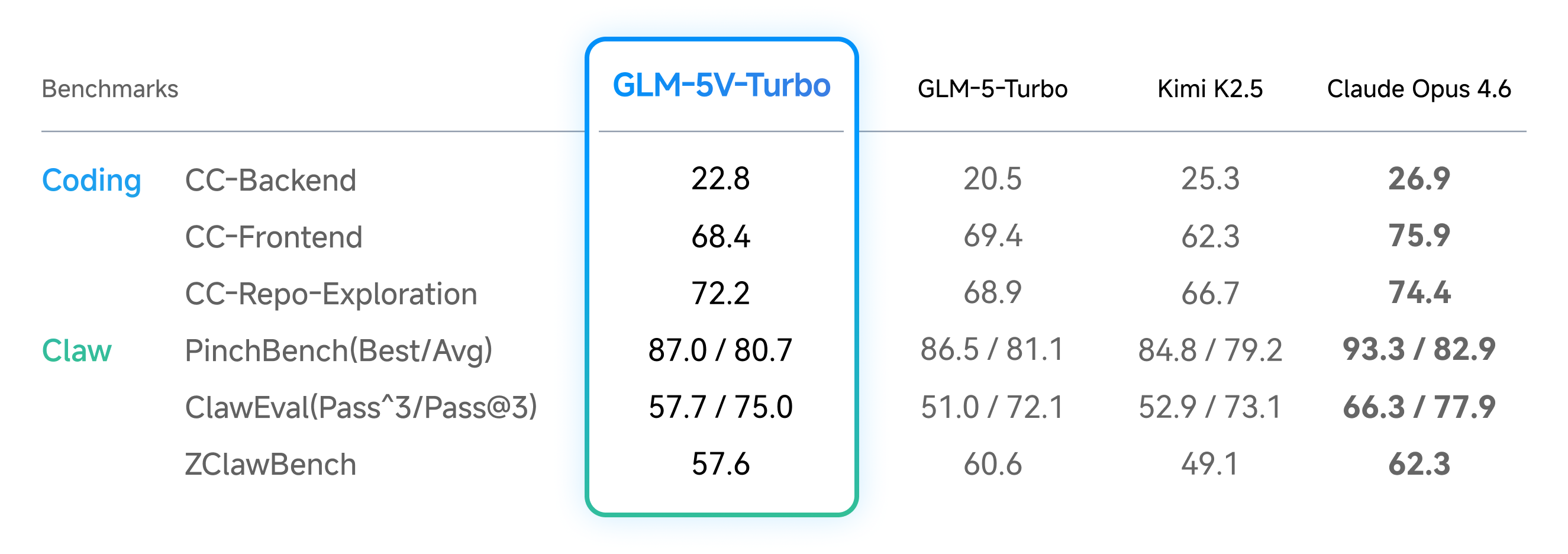
Z.ai-published benchmark comparison for GLM-5V-Turbo vs GLM-5-Turbo, Kimi K2.5 and Claude Opus 4.6 (multimodal coding/tool-use/GUI-agent table + text-coding/Claw-agent table). Values transcribed from the two readable benchmark tables on the official Z.ai docs page.
| Benchmark | GLM-5V-Turbo | GLM-5-Turbo | Kimi K2.5 | Claude Opus 4.6 |
|---|---|---|---|---|
| Design2Code | 94.8 score | — | 91.3 score | 77.3 score |
| Flame-VLM-Code | 93.8 score | — | 88.8 score | 98.8 score |
| Vision2Web | 31 score | — | 33.2 score | 43.5 score |
| ImageMining | 30.7 score | — | 24.4 score | — |
| BrowseComp-VL | 51.9 score | — | 42.9 score | 35.9 score |
| MMSearch | 72.9 score | — | 58.7 score | 63.8 score |
| MMSearch-Plus | 30 score | — | 25.6 score | 25.6 score |
| SimpleVQA | 78.2 score | — | 71.5 score | 63.2 score |
| Facts | 58.6 score | — | 57.8 score | — |
| V* | 89 score | — | 84.3 score | 66.5 score |
| OSWorld | 62.3 score | — | 63.3 score | 72.2 score |
| AndroidWorld | 75.7 score | — | 43.1 score | 62 score |
| WebVoyager | 88.5 score | — | 84.3 score | 88 score |
| CC-Backend | 22.8 score | 20.5 score | 25.3 score | 26.9 score |
| CC-Frontend | 68.4 score | 69.4 score | 62.3 score | 75.9 score |
| CC-Repo-Exploration | 72.2 score | 68.9 score | 66.7 score | 74.4 score |
| PinchBench (Best/Avg) | 87.0 / 80.7 score | 86.5 / 81.1 score | 84.8 / 79.2 score | 93.3 / 82.9 score |
| ClawEval (Pass^3/Pass@3) | 57.7 / 75.0 score | 51.0 / 72.1 score | 52.9 / 73.1 score | 66.3 / 77.9 score |
| ZClawBench | 57.6 score | 60.6 score | 49.1 score | 62.3 score |
This model's scores
- Design2Code (multimodal coding)94.8%
- AndroidWorld (GUI agents)75.7%
- OSWorld (GUI agents)62.3%
- MMSearch (multimodal tool use)72.9%
- ImageMining (visual search)30.7%
Scores on a 0–100 scale (25-point gridlines); higher is better. Each benchmark links to its published source.
Pricing
| Input | $1.20 per 1M tokens |
|---|---|
| Output | $4.00 per 1M tokens |
Same per-token pricing as the GLM-5-Turbo text model. API-only via the Z.ai platform.
Strengths
- Native multimodal grounding — images, video, design drafts and document layouts are processed as first-class reasoning inputs, not OCR'd afterthoughts.
- Vision-to-code: converts mockups, screenshots and walkthroughs into executable front-end code, the model's primary design goal.
- Built for agentic engineering — explicitly integrated with OpenClaw and Claude Code workflows, with function calling and context caching.
- Keeps competitive text-only coding ability via the GLM-5-Turbo base while adding multimodal perception.
- Large 200K context with up to 128K output, suited to long, tool-augmented multi-step tasks.
Best for
- Turning Figma/design mockups and UI screenshots directly into working front-end code.
- GUI and computer-use agents that read a screen and take multi-step actions (Android, desktop, web).
- Multimodal document understanding — extracting structure and answers from complex PDF and document layouts.
- Visual tool use and multimodal search inside agent frameworks.
- Video-grounded tasks such as reasoning over screen recordings and product walkthroughs.
How to access
| Provider | Model ID |
|---|---|
| Z.ai ↗ | glm-5v-turbo |
GLM Turbo — every version
The full lineage of the GLM Turbo line, newest first. Every version has its own page — click any to compare specs, benchmarks and pricing.
| Version | Released | Context | License |
|---|---|---|---|
| GLM-5V-Turbocurrent | 2026-04-01 | — | Open weights |
| GLM-5-Turbo | 2026-03-15 | — | Open weights |
FAQ
What is GLM-5V-Turbo?
GLM-5V-Turbo is Z.ai (Zhipu / GLM)'s native multimodal vision model, released on 1 April 2026 as the current flagship of the GLM Turbo line. It takes images, video, design drafts and documents directly in context and outputs code or structured GUI actions, with a focus on turning designs and screenshots into working front-end code.
Is GLM-5V-Turbo open weights?
No. Unlike the open-weights GLM-5 flagship, GLM-5V-Turbo ships proprietary and is available only through Z.ai's API and chat platform — Z.ai has not published downloadable weights for this Turbo vision variant.
How much does GLM-5V-Turbo cost?
Z.ai prices GLM-5V-Turbo at $1.20 per million input tokens and $4.00 per million output tokens — the same per-token rate as the GLM-5-Turbo text model. It is served via the Z.ai API using the model id glm-5v-turbo.
What context length and output limit does GLM-5V-Turbo support?
GLM-5V-Turbo supports a 200K-token context window and up to 128K tokens of output, along with thinking mode, streaming output, function calling and context caching.