
Overview
Tiny Aya is a family of open-weight multilingual language models released by Cohere Labs (Cohere's research arm) on 17 February 2026, unveiled at the India AI Summit. Every model in the family is a compact 3.35-billion-parameter transformer that covers 70 languages, including many lower-resourced ones across Africa, South Asia, Europe, Asia-Pacific and West Asia. The whole point of Tiny Aya is that it is small enough to run offline on everyday hardware like a laptop, so multilingual AI works in connectivity-constrained markets without sending data to a server.
The release ships five models. Tiny Aya Base is the pretrained foundation model. Tiny Aya Global is the globally balanced instruction-tuned variant, and three region-specialised instruction models tune the balance further: Tiny Aya Earth (best for West Asian and African languages), Tiny Aya Fire (best for South Asian languages such as Hindi, Bengali, Urdu, Tamil and Telugu) and Tiny Aya Water (best for European and Asia-Pacific languages). All share the same 3.35B size, an 8K-token input and output window, and a transformer that mixes sliding-window local attention (window 4096) with periodic global attention layers.
The models are open weights under a CC-BY-NC 4.0 (non-commercial) licence and are text-only. You can download them from Hugging Face (including GGUF quantizations for llama.cpp, Ollama and LM Studio), Kaggle and Ollama, and the four instruction-tuned variants are also callable through the Cohere API Chat endpoint as tiny-aya-global, tiny-aya-earth, tiny-aya-fire and tiny-aya-water. According to Cohere's technical report, Tiny Aya was pretrained on 6 trillion tokens using 256 Nvidia H100 GPUs, with region-aware post-training to lift quality on lower-resourced languages.
| Released | 2026-02-17 |
|---|---|
| License | CC-BY-NC 4.0 |
| Weights | Open weights |
| Parameters | 3.35B |
| Context | 8K |
| Max output | 8K tokens |
| Architecture | Auto-regressive optimized transformer; three layers use sliding-window attention (window size 4096) with RoPE for local context, and every fourth layer uses global attention without positional embeddings. Released as a pretrained base plus four instruction-tuned variants (SFT + preference training). |
| Modalities | Text |
| Status | Generally available |
Benchmarks
This model's scores
- WMT24++ translation (ChrF, 55 langs)46ChrF
- FLORES translation (ChrF, 66 langs)43.5ChrF
- mDolly open-ended generation86.9win rate
- Global MMLU (42 langs)44.9%
- Global MGSM (35 langs)52.8%
Scores on a 0–100 scale (25-point gridlines); higher is better. Each benchmark links to its published source.
Strengths
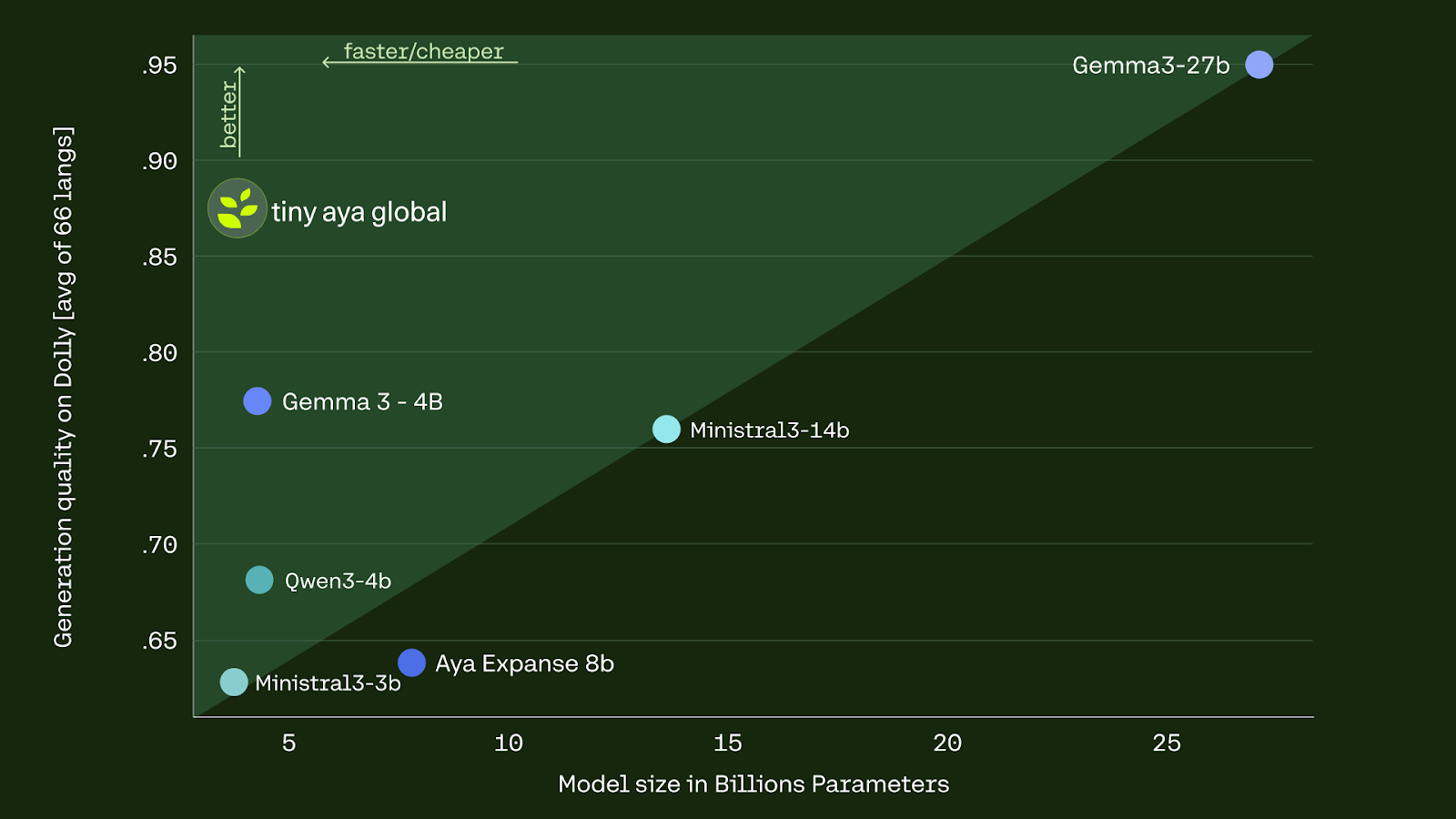
- Genuinely small (3.35B) and quantizable to GGUF, so it runs offline on a laptop or modest GPU
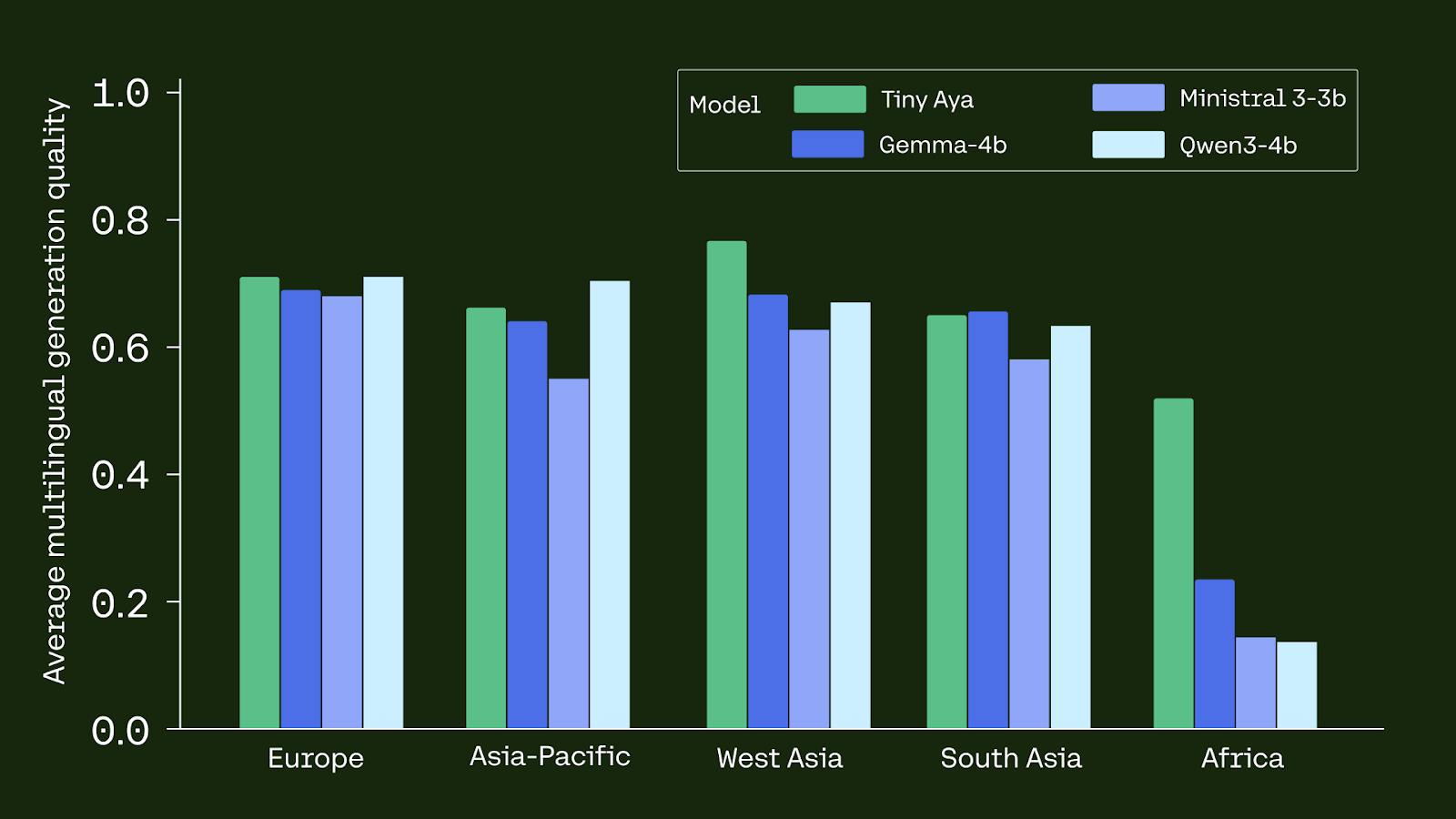
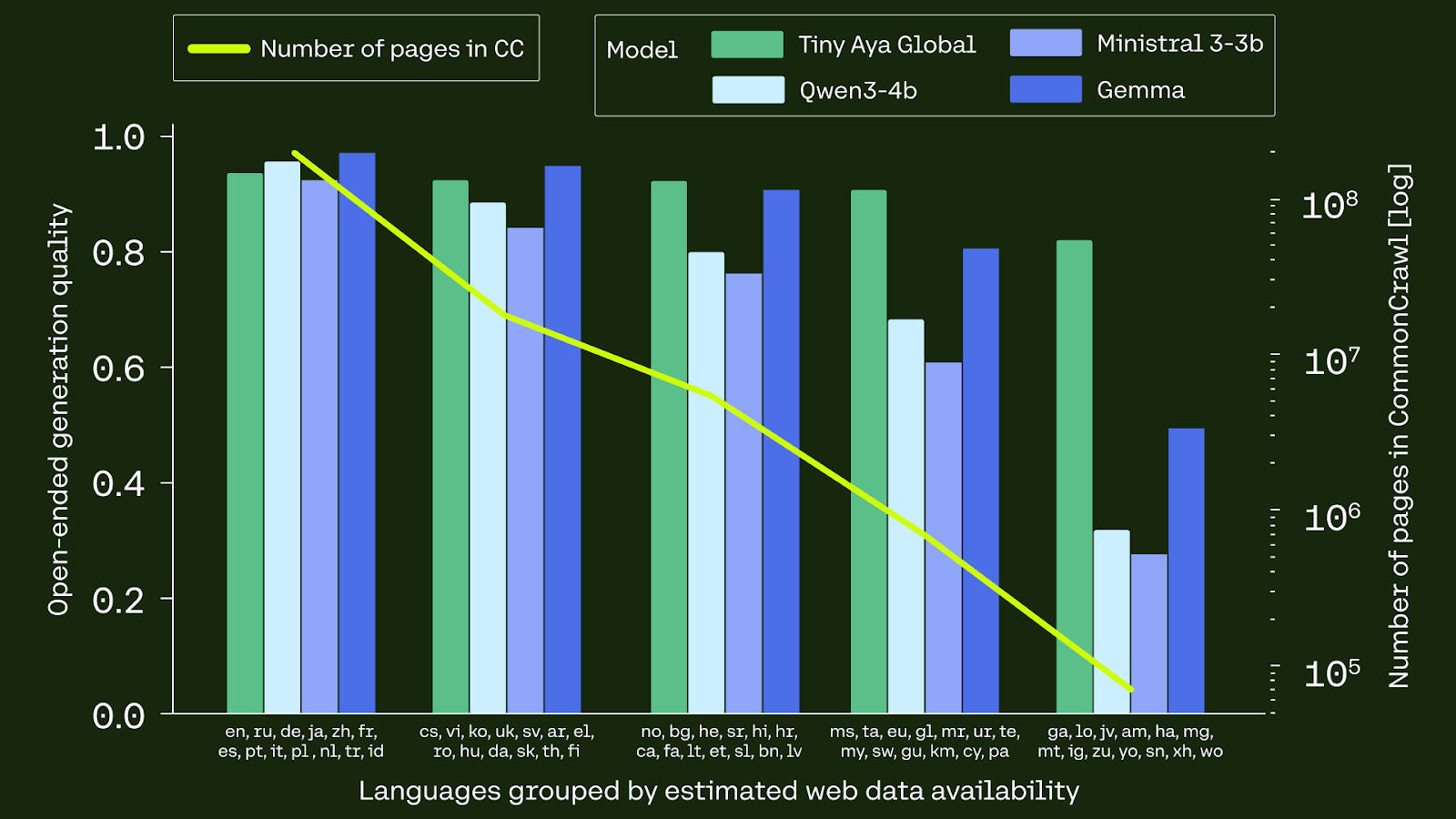
- Broad coverage of 70 languages with deliberate focus on lower-resourced ones
- Leads its size class on translation: 46.0 ChrF on WMT24++ vs 41.9 for Gemma 3 4B, winning 46 of 55 languages
- Region-specialised Earth/Fire/Water variants squeeze out extra translation quality per region
- Open weights plus a published technical report; instruction variants also available via the Cohere API
Best for
- Offline, on-device translation in connectivity-constrained markets
- Local-language chat and assistants for multilingual or lower-resourced-language audiences
- Privacy-sensitive multilingual apps that must run without sending data to the cloud
- Summarization and cross-lingual tasks across 70 languages
- Region-targeted deployments (South Asia, Africa, Europe/Asia-Pacific) using the specialised variants
How to access
FAQ
How big is Tiny Aya and how many languages does it cover?
Every Tiny Aya model is a 3.35-billion-parameter transformer that covers 70 languages, with an 8K-token input and output window. It is deliberately small so it can run on a laptop or modest GPU, including quantized GGUF builds for Ollama, llama.cpp and LM Studio.
What are the five Tiny Aya models?
Tiny Aya Base is the pretrained foundation model. Tiny Aya Global is the globally balanced instruction-tuned variant. Tiny Aya Earth is tuned for West Asian and African languages, Tiny Aya Fire for South Asian languages, and Tiny Aya Water for European and Asia-Pacific languages.
Is Tiny Aya free and open weights?
The weights are open under the CC-BY-NC 4.0 licence, which permits non-commercial use, and are downloadable from Hugging Face, Kaggle and Ollama. The four instruction-tuned variants are also callable through the Cohere API Chat endpoint; Cohere has not published a separate per-token API price for Tiny Aya.
How does Tiny Aya compare to Gemma 3 4B on translation?
In Cohere's technical report, Tiny Aya Global scores 46.0 ChrF on WMT24++ versus 41.9 for Gemma 3 4B and wins on 46 of 55 languages, and it also leads on FLORES (43.5 vs 38.9 ChrF). On reasoning-heavy benchmarks like Global MGSM it trails slightly (52.8 vs 55.4).