In plain English
LlamaIndex and LangChain are the two most widely used Python frameworks for building LLM-powered apps, and both can produce a working RAG pipeline. The confusion is understandable — they overlap in the middle, they both support agents, and tutorials often use them interchangeably. But they started from different places and still have different centers of gravity, and that matters when you're choosing what to build on.
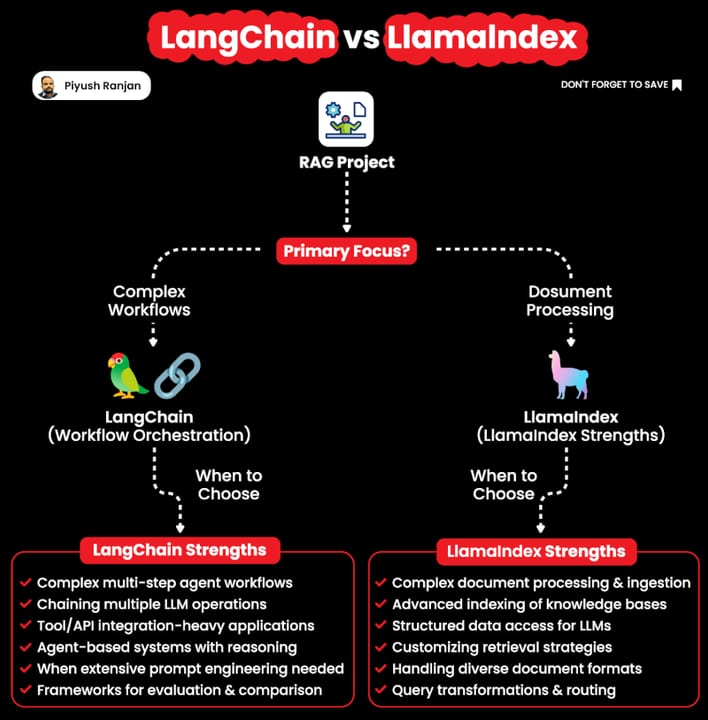
Here's the clearest analogy: think of LlamaIndex as a specialist librarian and LangChain as a general-purpose workflow engine. The librarian's entire job is acquiring documents, filing them intelligently, and retrieving the exact right page when you ask. The workflow engine can do that too, but it's really a platform for wiring together any combination of steps, tools, models, and APIs into a reusable, composable chain. Both are useful — you'd just hire them for different projects.
LlamaIndex (formerly GPT Index) was built from day one to make retrieval-augmented generation as clean as possible: load documents, index them, query them, get cited answers. It ships sensible RAG defaults out of the box and lets you swap every component as requirements grow. LangChain is older, broader, and more general — it gives you a composable interface for chaining LLM calls, tools, memory, and agents across hundreds of providers. LangChain 1.0 (released October 2025) unified its agent story under LangGraph, a graph-based runtime for stateful, multi-step workflows.
Why this choice matters
Picking the wrong foundation is expensive to undo. RAG pipelines aren't a single function call — they're composed of a loader, a chunker, an embedding model, a vector store, a retriever, optional rerankers, a prompt template, and a response synthesizer. Swap the framework and you're rewriting most of that glue code.
The risk runs in both directions. Teams that reach for LangChain's breadth to build a pure document Q&A system often end up with more boilerplate than the problem needs — LangChain needs roughly 30–40% more code for an equivalent RAG pipeline compared to LlamaIndex's high-level API. Teams that build everything on LlamaIndex's data layer then find themselves inventing agent orchestration from scratch when requirements evolve beyond "answer questions about these docs."
A third path has emerged as the 2026 best practice: use both, each in its lane. LlamaIndex handles the data layer — ingestion, chunking, indexing, retrieval tuning, and evaluation. LangChain (via LangGraph) handles the orchestration layer — multi-step agent logic, tool routing, memory, and human-in-the-loop flows. Understanding where each framework is strong makes that split obvious.
How each framework is built
Both frameworks model a RAG application as a pipeline, but they carve up the stages differently. LlamaIndex makes every stage of the data pipeline a first-class citizen. LangChain makes every stage of the invocation pipeline — prompt assembly, model call, output parsing, tool dispatch — a first-class citizen.
- Data connectors (LlamaHub)
- Node parsers & chunking
- Index types (vector, summary, KG)
- Retrievers + rerankers
- Query / chat engines
- Ingestion pipelines
- Evaluation primitives
- Model abstractions (600+ providers)
- LCEL chain composition
- Prompt templates & output parsers
- Tool definitions & dispatch
- StateGraph agent loops
- Persistent memory / checkpoints
- LangSmith observability
LlamaIndex: the data pipeline in depth
LlamaIndex models your data as Documents (one per source file) that are parsed into Nodes (small retrievable chunks). Nodes carry metadata — source path, page number, any custom tags — and are embedded into a VectorStoreIndex by default. At query time, the QueryEngine embeds the question, searches for nearest nodes, and passes them to a ResponseSynthesizer that prompts the LLM and returns an answer with cited source nodes. The whole pipeline runs in about five lines of code; each stage is independently swappable.
LlamaIndex ships specialized retrieval patterns that go well beyond a single similarity_top_k call: sub-question decomposition breaks a multi-part question into smaller sub-queries run in parallel, auto-merging retrieval fetches small precise chunks then widens to their surrounding context, and hybrid search combines BM25 keyword matching with vector similarity so exact-match terms like product codes still work. These are built-in, not manual re-implementations.
LangChain: the invocation layer in depth
LangChain's core abstraction is LCEL (LangChain Expression Language) — a declarative pipe operator (|) that composes prompt templates, model calls, output parsers, and tools into a chain. Any LCEL chain is automatically streamable, batchable, and traceable without extra code. A RAG chain is typically: retriever | prompt | llm | StrOutputParser(). Adding an agent wraps that in a LangGraph StateGraph that loops until the task is done, with edges that encode conditional branching.
Since LangChain 1.0 (October 2025), create_react_agent and similar helpers run on LangGraph as their underlying runtime. LangGraph's graph-based model lets you define explicit state, conditional edges, and human-in-the-loop pause points — making complex agent behaviors reproducible and debuggable in a way that simple chain loops are not.
Feature-by-feature comparison
The table below maps the capabilities that most builders care about to the framework that handles it more natively. "Both" means meaningful built-in support exists in each; the leader is in parentheses.
| Capability | LlamaIndex | LangChain / LangGraph | Edge |
|---|---|---|---|
| 5-line RAG quickstart | VectorStoreIndex.from_documents | RetrievalQA chain | LlamaIndex (less boilerplate) |
| Document loaders / connectors | 160+ via LlamaHub | 100+ via community integrations | LlamaIndex |
| PDF table / image parsing | LlamaParse (hosted service) | Manual / third-party parsers | LlamaIndex |
| Chunking strategies | 10+ built-in node parsers | Text splitters (character, recursive) | LlamaIndex |
| Index types | Vector, summary, KG, SQL | Mainly vector store wrappers | LlamaIndex |
| Hybrid search (BM25 + vector) | Built-in | Requires custom chain | LlamaIndex |
| Sub-question decomposition | Built-in QueryEngine | Manual chain construction | LlamaIndex |
| Reranking | Built-in postprocessors | Requires wrapper code | LlamaIndex |
| Model provider integrations | 50+ (via LiteLLM bridge) | 600+ native integrations | LangChain |
| Stateful multi-step agents | Workflows (event-driven) | LangGraph StateGraph | LangChain |
| Cyclic agent loops | Supported via Workflows | First-class in LangGraph | LangChain |
| Human-in-the-loop | Supported | First-class in LangGraph | LangChain |
| Observability / tracing | LlamaTrace (beta) | LangSmith (mature) | LangChain |
| RAG evaluation built-in | Faithfulness, relevancy, etc. | Separate LangSmith evals | LlamaIndex |
| GitHub stars (mid-2026) | ~48,000 | ~130,000 | LangChain (community) |
Side-by-side code: a basic RAG query
Comparing roughly equivalent RAG implementations shows where each framework's overhead lives. Both examples load a directory of documents and answer a single question.
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
docs = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(docs)
engine = index.as_query_engine(similarity_top_k=4)
response = engine.query("What is our refund policy?")
print(response) # synthesized answer
print(response.source_nodes) # cited chunksfrom langchain_community.document_loaders import DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_community.vectorstores import FAISS
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
# Load and split
loader = DirectoryLoader("data")
docs = loader.load()
splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=64)
chunks = splitter.split_documents(docs)
# Embed and store
vectorstore = FAISS.from_documents(chunks, OpenAIEmbeddings())
retriever = vectorstore.as_retriever(search_kwargs={"k": 4})
# Chain
prompt = ChatPromptTemplate.from_template(
"Answer using the context below.\n\nContext: {context}\n\nQuestion: {question}"
)
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| ChatOpenAI()
| StrOutputParser()
)
print(chain.invoke("What is our refund policy?"))The LangChain version isn't harder — just longer. You make explicit choices (splitter type, chunk size, vector store, prompt template) that LlamaIndex handles via sensible defaults. LangChain's explicitness is an advantage when you need precise control; LlamaIndex's defaults are an advantage when you want results fast.
Using both together
LlamaIndex ships a LangChainLLM wrapper that lets you use any LangChain-compatible model inside a LlamaIndex pipeline, and a LlamaIndexRetriever adapter that wraps a LlamaIndex query engine as a LangChain retriever. This means you can hand a LlamaIndex index to a LangGraph agent as a tool — the most common production hybrid pattern in 2026.
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.langchain_helpers.agents import IndexToolConfig, LlamaIndexTool
from langgraph.prebuilt import create_react_agent
from langchain_openai import ChatOpenAI
# Build the LlamaIndex retrieval layer
docs = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(docs)
# Wrap as a LangChain-compatible tool
tool_config = IndexToolConfig(
query_engine=index.as_query_engine(),
name="knowledge_base",
description="Search company policy documents",
)
tool = LlamaIndexTool.from_tool_config(tool_config)
# Hand the tool to a LangGraph agent
agent = create_react_agent(ChatOpenAI(model="gpt-5.5"), [tool])
result = agent.invoke({"messages": [{"role": "user", "content": "What is our refund window?"}]})
print(result["messages"][-1].content)When to choose which
Most decisions come down to answering two questions: Is retrieval quality the make-or-break metric? and Does the app need cyclic agent logic with state and tools beyond retrieval?
Choose LlamaIndex when...
- Your primary job is ingesting and querying varied document types — PDFs with tables, Notion pages, database rows, Slack exports.
- You need advanced retrieval patterns (hybrid search, reranking, sub-question decomposition) without writing them from scratch.
- You want to evaluate RAG quality with built-in faithfulness and relevancy evaluators.
- You're building an enterprise knowledge base or document QA system where the retrieval layer is the hardest part.
- Team velocity matters — LlamaIndex's defaults ship a working retrieval layer faster.
Choose LangChain / LangGraph when...
- You're building stateful agents that loop, branch conditionally, use multiple tools, and need explicit state management.
- Human-in-the-loop approval steps are a core product requirement.
- You need to integrate with an obscure model provider or tool — LangChain's 600+ integrations are unmatched.
- LangSmith observability and tracing are on your roadmap.
- The retrieval component is simple (a single vector search) but orchestration is complex.
Use both when...
- The product is an agent that uses document retrieval as one of several tools.
- You want LlamaIndex's retrieval quality inside a LangGraph state machine.
- You're migrating an existing LangChain app and want to upgrade just the retrieval layer.
Going deeper
Once you're past basic RAG, the divergence between the two frameworks sharpens. Here are the more advanced areas where choosing correctly saves real engineering time.
Advanced retrieval: LlamaIndex's deeper toolkit
LlamaIndex's RouterQueryEngine can dispatch a query to whichever of several indexes best fits the question — a vector index for unstructured docs, a SQL index for structured data, a knowledge-graph index for relational facts. Each route uses the right retrieval strategy. LlamaParse (a hosted add-on) parses multi-column PDFs and scanned documents into clean structured text before they enter the pipeline, which is where naive RAG pipelines most commonly break. IngestionPipeline with a document store handles incremental re-indexing: only changed documents get re-embedded, which matters once your corpus grows past a few hundred files.
Stateful agent patterns: LangGraph's advantage
LangGraph's StateGraph lets you model agent behavior as a directed graph where nodes are Python functions and edges are conditional transitions. This makes complex behaviors tractable: a research agent might loop search → read → synthesize until it has enough confidence, then route to a draft → human-review → publish subgraph. Each node gets the full state object; checkpoints let you persist mid-run state to a database and resume after a crash or human review. LlamaIndex's Workflows offer a similar event-driven model, but LangGraph has more production tooling around it (LangSmith traces, Studio visual debugger).
Evaluation and observability
LlamaIndex ships evaluation primitives directly: FaithfulnessEvaluator scores whether an answer is grounded in the retrieved context, RelevancyEvaluator checks whether the right chunks were retrieved, and CorrectnessEvaluator compares answers to ground-truth labels. These run as part of your test suite or CI pipeline without a separate platform. LangChain's evaluation story runs through LangSmith, a hosted platform (free tier available) with dataset management, prompt versioning, human annotation, and A/B comparison. If you're comparing LangSmith to LlamaIndex's in-library evaluators, LangSmith is more capable; LlamaIndex's evals require no external service.
| Production concern | LlamaIndex approach | LangChain approach |
|---|---|---|
| Incremental re-indexing | IngestionPipeline + DocumentStore | Manual change detection |
| Retrieval evaluation | Built-in evaluators (no platform needed) | LangSmith datasets + evals |
| PDF with tables/images | LlamaParse (paid add-on) | Third-party parsers |
| Agent state persistence | Workflow checkpoints (basic) | LangGraph + PostgreSQL checkpointer |
| Streaming responses | Supported | First-class via LCEL |
| Multi-modal RAG | Supported (image nodes) | Supported (model-dependent) |
The frameworks are converging: LlamaIndex's Workflows and LangGraph's StateGraph solve similar problems with similar ideas. The practical difference in 2026 is that LangGraph has more mature production tooling around agent orchestration, while LlamaIndex has more mature production tooling around the retrieval layer. Most ambitious RAG applications end up touching both sides of that line — which is exactly why composing them is the pattern teams keep arriving at independently.
FAQ
Is LlamaIndex or LangChain better for RAG in 2026?
LlamaIndex is the stronger choice for pure RAG — it ships advanced retrieval patterns (reranking, hybrid search, sub-question decomposition) as built-ins and needs less code to reach a working pipeline. LangChain via LangGraph is stronger when retrieval is just one tool inside a more complex stateful agent. Many production teams use both: LlamaIndex for the retrieval layer, LangGraph for orchestration.
Can I use LlamaIndex inside a LangChain agent?
Yes. LlamaIndex provides a LlamaIndexTool adapter (and a LangChainLLM wrapper for the reverse direction). A common pattern wraps a LlamaIndex query engine as a LangChain tool, then passes it to a create_react_agent call. This gives you LlamaIndex's retrieval quality inside LangGraph's agent loop.
What is the main difference between LlamaIndex and LangChain?
LlamaIndex's center of gravity is the data layer: loading, chunking, indexing, and retrieving documents, with specialized RAG patterns built in. LangChain's center of gravity is the invocation layer: composing model calls, tools, memory, and agent loops with LCEL and LangGraph. They're complementary rather than redundant.
Does LangChain work for RAG without LlamaIndex?
Absolutely. LangChain has its own document loaders, text splitters, vector store wrappers, and retrieval chains — you can build a complete RAG pipeline in LangChain alone. It just requires more explicit configuration than LlamaIndex's high-level defaults, and LangChain's retrieval primitives are less feature-rich than LlamaIndex's for advanced patterns like reranking or sub-question decomposition.
Is LlamaIndex harder to learn than LangChain?
LlamaIndex is generally easier to start with for RAG — its five-line quickstart produces a working query engine with no boilerplate. LangChain has a larger API surface and more concepts to learn (LCEL, runnables, output parsers, LangGraph), but that breadth pays off when you need complex agent behavior. Start with LlamaIndex if your first goal is document Q&A.
Do LlamaIndex and LangChain both support local open-source models?
Yes, both are model-agnostic. LlamaIndex lets you set Settings.llm and Settings.embed_model to any supported provider, including Ollama-served local models. LangChain has native integrations for 600+ providers including local inference via Ollama, LMStudio, and Hugging Face transformers. Neither requires OpenAI.