In plain English
An agentic workflow is a multi-step LLM pipeline where code decides what to do next — not a human typing at a chat window. Unlike a fully autonomous agent (which picks its own sequence of actions at runtime), a workflow follows a predefined graph of LLM calls and tools that a developer designed in advance.
Think of a workflow as a factory line versus a freelancer. A factory line stamps out the same sequence of steps every time — fast, predictable, easy to inspect. A freelancer figures out the sequence on the fly — flexible, but slower and harder to audit. Workflows are the factory line; fully autonomous agents are the freelancer. Most real jobs belong on a factory line.
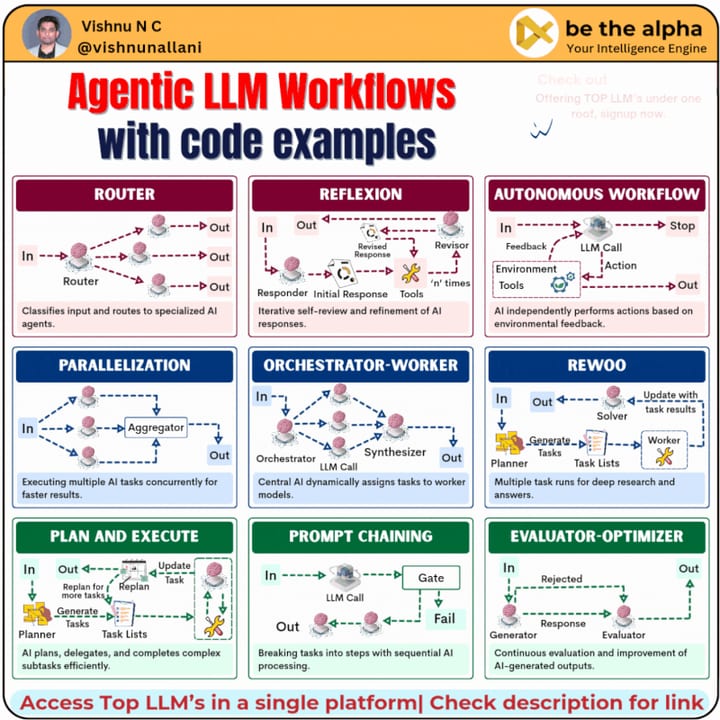
In December 2024, Anthropic's engineering blog published Building Effective Agents, which named five canonical workflow patterns that their teams saw repeatedly across production deployments: prompt chaining, routing, parallelization, orchestrator-workers, and evaluator-optimizer. These five patterns (and combinations of them) cover the vast majority of LLM use cases that actually ship.
Why it matters
Fully autonomous agents are powerful but expensive to run, expensive to debug, and prone to cascading errors — a single bad tool call early in a run can corrupt every step that follows. Workflows trade flexibility for predictability. That predictability is exactly what you want in production.
Choosing an agent when a workflow would have worked typically costs five to twenty times more per task and produces harder-to-audit results. The five workflow patterns give builders a vocabulary for matching a task shape to the right control structure — so the decision is no longer "agent or not?" but "which pattern?".
- Cost control — a workflow's LLM calls are bounded and predictable; an autonomous agent's are not.
- Debuggability — each step's input and output can be logged separately, making failures obvious.
- Latency — you can parallelize independent steps without waiting for a planner to invent that idea at runtime.
- Reliability — programmatic checks between steps catch bad outputs before they propagate.
- Composability — patterns stack cleanly; a routing step can dispatch to a chain, which fans out to parallel calls.
How each pattern works
Each pattern solves a distinct structural problem. Below is a brief sketch of all five, followed by a diagram showing how they relate, then a deeper look at each one.
- Prompt Chaining
- Routing
- Parallelization
- Orchestrator-Workers
- Evaluator-Optimizer
- A → B → C (sequential)
- Input → classifier → branch A or B
- Input → [A, B, C] → merge
- Orchestrator → [worker 1, worker 2 ...] → merge
- Generator ⇄ Evaluator (loop)
- Tasks with dependent sub-steps
- Inputs that need specialized handling
- Independent sub-tasks or redundant checks
- Complex tasks needing dynamic delegation
- Tasks with measurable quality criteria
1. Prompt chaining
The simplest pattern: the output of one LLM call becomes the input of the next. Each call handles a single, focused sub-task — extract, then transform, then format. Because each step is small, it is far easier to prompt well and to validate the output before proceeding.
Intermediate steps also act as natural checkpoints. A programmatic gate ("does the extracted JSON have all required fields?") can halt the chain before a bad intermediate result corrupts downstream steps. This is the key difference from asking one big prompt to do everything at once.
# Minimal prompt chain: extract → rewrite → format
def summarise_for_twitter(whitepaper: str) -> str:
# Step 1 — extract key points
points = llm(f"Extract the 3-5 most important findings from:\n{whitepaper}")
# Programmatic gate — stop if extraction failed
assert len(points.strip()) > 20, "Extraction returned too little content"
# Step 2 — rewrite for a general audience
casual = llm(f"Rewrite these findings in plain English for a non-expert:\n{points}")
# Step 3 — format as tweet thread
tweets = llm(f"Format this as a numbered tweet thread (max 280 chars each):\n{casual}")
return tweets2. Routing
A router inspects the input and dispatches it to the most appropriate downstream handler. The router itself is usually a cheap LLM call (or even a simple classifier) that assigns a category — billing, technical, general — and then code branches accordingly. Each branch can have its own system prompt, tool set, and even model choice.
Routing shines when different input types genuinely need different treatment. A single unified prompt that tries to handle both simple FAQ questions and complex multi-step technical queries will be mediocre at both. Routing lets you specialize without duplicating the entry point.
3. Parallelization
When a task can be split into independent sub-tasks, run them concurrently instead of sequentially. This pattern has two sub-variants:
- Sectioning — decompose the input into independent chunks (e.g., different sections of a document), process each in parallel, then merge the results.
- Voting — run the same prompt multiple times with independent context and aggregate via majority vote. Useful when correctness matters more than cost — for example, a content safety check or a factual verification step.
In terms of latency, parallelization turns n × (call time) into roughly 1 × (call time) + merge overhead. For three or more concurrent calls this is almost always worthwhile. The tradeoff is that the aggregation step must be designed carefully — poorly merged outputs can be worse than a single sequential output.
4. Orchestrator-workers
An orchestrator LLM receives a complex task and decomposes it into sub-tasks at runtime, then dispatches each sub-task to a worker (another LLM call, a tool, or even a nested workflow). Workers are stateless and domain-specific; they know nothing of each other. The orchestrator then merges the results.
This is the pattern closest to a full agent — the orchestrator makes dynamic decisions about how to decompose the work. The key distinction from full autonomy is that the orchestrator's action space is still bounded by the workflow code: it can only delegate to the workers the developer has defined, not invent arbitrary new tool calls.
5. Evaluator-optimizer
A generator produces an initial output. An evaluator (a second LLM call, or the same model with a different prompt) scores or critiques it. If the score is below a threshold, the critique is fed back to the generator and the loop repeats. This continues until quality criteria are met or a max-iteration limit is hit.
The insight behind this pattern is that it is hard for a single prompt to be simultaneously creative and self-critical. Separating the generator and evaluator roles lets each model focus: the generator can take risks, and the evaluator can be ruthlessly precise. This is particularly valuable for code generation, translation quality, and structured data extraction where "good enough" is well-defined.
Combining patterns
The patterns are designed to be composable. A real pipeline almost always combines two or more of them. A few common combinations:
- Route → chain: classify the input type, then run a specialized multi-step chain for that category.
- Orchestrator → parallelize: the orchestrator decomposes a task and dispatches independent sub-tasks to workers that run in parallel.
- Chain → evaluate: run the full pipeline, then apply an evaluator-optimizer pass on the final output before returning it.
- Parallelize → vote → chain: gather multiple independent perspectives, pick the best via voting, then feed the winner into a subsequent formatting chain.
When composing patterns, the main risk is latency accumulation. Each additional sequential step adds wall-clock time. As a rule, run parallel branches wherever possible, keep sequential chains short, and place the evaluator-optimizer loop only on the sub-task that most benefits from refinement — not on the entire pipeline.
| Combination | When to reach for it | Watch out for |
|---|---|---|
| Route → chain | Different input types need different multi-step handling | Router misclassification misdirects the whole chain |
| Orchestrate → parallelize | Many independent sub-tasks of similar type | Orchestrator becoming a bottleneck at high throughput |
| Chain → evaluate | Final output has a measurable quality bar | Infinite loops if the evaluator threshold is too strict |
| Parallelize (vote) | High-stakes correctness checks | Cost: N parallel calls instead of 1 |
Workflow vs. full agent: when to escalate
A workflow encodes the control flow in code; an agent encodes it in the model's reasoning at runtime. Workflows win when the task's shape is known in advance. Agents win when the required sequence of steps cannot be predicted until the model has started working through the problem.
The practical heuristic: if you can write the control-flow graph on a whiteboard before you start, use a workflow. If you genuinely cannot — for example, an open-ended research task where the number and type of searches depends on what each search reveals — then you need an agent.
- Workflow signals: fixed input format, bounded output format, identifiable error modes, easily stated quality criteria.
- Agent signals: open-ended task, number of steps unknown in advance, task requires following unexpected threads, human-in-the-loop for major decisions is acceptable.
Escalating to a full agent when a workflow would have done the job has real costs: autonomous agents run five to twenty times more expensive per task, are significantly harder to debug when they fail (because the path taken is discovered at runtime, not designed in advance), and have a higher rate of compounding errors — a mistake in step 2 of an 8-step autonomous run can corrupt every subsequent step silently.
Going deeper
Once you are comfortable with the five core patterns, the next layer of complexity involves dynamic workflow graphs. Where static workflows hardcode the edges between nodes at development time, dynamic graphs generate those edges at runtime — conditioned on the input — using an LLM planner or a learned routing policy. The 2025 research landscape distinguishes between template-based approaches (modifying a reusable static graph) and autoregressive approaches (sampling a full DAG for each query from scratch).
Cascade routing is a cost-optimized variant of the routing pattern that sends each query first to a cheap model, and escalates to a larger model only if the cheap model's confidence is below a threshold. Real-world deployments report 40-60% cost reductions versus always routing to the large model, with minimal quality loss on most query types.
Human-in-the-loop checkpoints are a first-class feature of production workflow design, not a fallback. For high-stakes steps — committing a database write, sending an external communication, making a financial decision — inserting an explicit approval gate transforms an otherwise autonomous loop into a supervised workflow. Anthropic refers to these as interrupts, and they are especially important in orchestrator-workers architectures where a worker mistake could cascade before the orchestrator reviews the result.
Evaluator design is the most underestimated component of the evaluator-optimizer pattern. The quality of the loop is bounded by the quality of the evaluator prompt. Common mistakes include: evaluation rubrics that are too vague for the model to act on, max-iteration limits set too low to allow real convergence, and using the same model temperature for both the generator (where creativity helps) and the evaluator (where precision is required). Effective evaluators use structured scoring (e.g., a 1-5 rubric with per-criterion breakdowns) and pass specific, actionable feedback, not just a pass/fail signal.
As of mid-2026, the emerging frontier is multi-framework interoperability: workflows that span agents built in different frameworks using the Agent2Agent (A2A) protocol — a vendor-neutral standard for inter-agent delegation. An orchestrator running in LangGraph can now delegate a sub-task to a worker running in a different vendor's stack, with the A2A protocol handling capability discovery and result passing. This makes the orchestrator-workers pattern viable at organizational scale, not just within a single codebase.
FAQ
What is the difference between an agentic workflow and an AI agent?
A workflow has a predefined control-flow graph that a developer designed in advance — the LLM fills in content at each node but does not decide the shape of the graph. An agent decides its own sequence of steps at runtime. Workflows are more predictable and cheaper; agents are more flexible but harder to audit.
When should I use prompt chaining instead of a single large prompt?
Use prompt chaining when the task has distinct sequential sub-steps and you want to validate intermediate outputs before committing to the next step. A single large prompt cannot be gated mid-execution; a chain can. Chaining also allows you to use smaller, cheaper models for simpler sub-tasks and reserve larger models only where they are needed.
How many iterations should an evaluator-optimizer loop run?
Most practitioners set a hard cap of three to five iterations. Beyond that, quality improvements tend to plateau and cost accumulates quickly. If the evaluator is still rejecting output after five rounds, the problem is usually in the generator prompt or the evaluator rubric — not a lack of iterations. Always instrument iteration counts in production.
Is the orchestrator-workers pattern the same as a multi-agent system?
They overlap but are not identical. Orchestrator-workers describes a specific control-flow pattern (one planner, multiple specialists) and can be implemented entirely within a single process. Multi-agent systems is a broader term that includes peer-to-peer agent networks, hierarchical agent trees, and cross-framework delegation. Orchestrator-workers is the most common multi-agent topology in production.
Can I combine multiple workflow patterns in one pipeline?
Yes, and this is the norm in production. Common combinations include routing into a chain, an orchestrator fanning out to parallel workers, and a chain followed by an evaluator-optimizer pass on the final output. Keep nesting shallow (at most two orchestration levels) to avoid debugging complexity and latency accumulation.
What does the voting variant of parallelization actually protect against?
Voting guards against random model errors — cases where a single LLM call gives the wrong answer not because the prompt is bad, but because the model sampled an unlikely token sequence. Running the same prompt three to five times and taking the majority answer dramatically reduces that error rate. It is most commonly used for classification, factual verification, and content safety checks where a wrong answer has a real cost.