In plain English
A plain language model does one thing: you give it text, it gives you text back. Evaluating it is almost easy — compare its answer to the right answer. An AI agent is different. It doesn't just answer; it acts. It reads a request, decides to call a tool, looks at the result, decides to call another tool, and loops like that until the job is done. So judging an agent only by its final sentence is like grading a chef on the last bite of a meal while ignoring whether they set the kitchen on fire along the way.
Picture hiring a new assistant to book a flight. You could check only one thing: did a ticket show up in your inbox? That is the final result. But you would also care that they booked the right flight, didn't spend twenty minutes on the wrong website first, didn't accidentally buy a second ticket, and didn't rack up a huge bill in the process. Each of those is a different kind of question, and a good performance review covers all of them. Evaluating an agent is exactly this kind of multi-angle review.
Why it matters
If you build with agents, the day will come when one works perfectly in your demo and falls apart in production. Without measurement, you are flying blind: you can't tell whether a prompt tweak helped or hurt, whether a new model is actually better for your task, or whether the agent quietly costs ten times more than you think. Evaluation turns vague feelings ("it seems smarter now") into numbers you can compare across versions.
The big trap is leaning on accuracy alone. Accuracy — did the final answer match the expected one — is borrowed from simple classification tasks, and it hides everything that makes agents risky:
- Right answer, wrong path. An agent can stumble to a correct result through a chaotic, lucky route that breaks the moment the inputs change. Accuracy gives it full marks and tells you nothing about the fragility.
- Right answer, ruinous cost. Two agents both succeed, but one used 3 tool calls and 2,000 tokens while the other looped 40 times burning 80,000 tokens and thirty seconds of latency. Accuracy scores them identically.
- Silent side effects. An agent that acts can send an email, delete a row, or charge a card. "The final text looked fine" does not mean it didn't do something harmful on the way.
- No partial credit. Many real tasks are multi-step. A binary right/wrong final score can't tell the difference between an agent that got 4 of 5 steps right and one that failed immediately.
This is why mature teams measure agents across several families of metrics at once — task outcome, the steps in between, how it used its tools, and what it all cost. The rest of this article walks through each family and then scores one real run end to end.
How it works
Agent evaluation works on two levels at the same time. Outcome-level evaluation asks "did the whole task succeed?" — one verdict per run. Process-level (or trajectory) evaluation zooms into the run and scores the individual steps: was each tool call correct, was the order sensible, did the agent waste moves? You need both, because outcome tells you whether it worked and process tells you why.
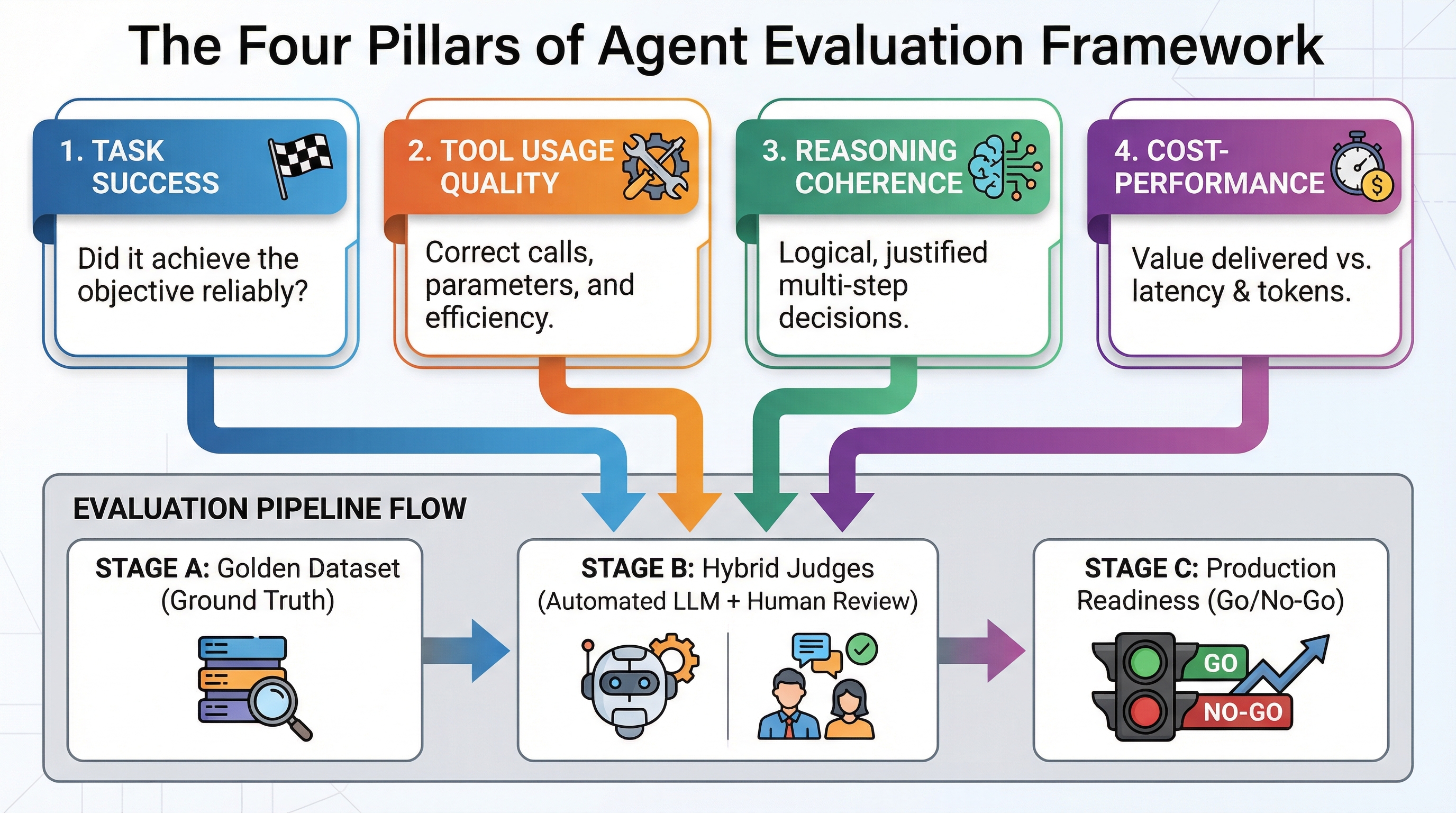
The four metric families
Almost every agent metric you'll meet fits into one of four buckets. Think of them as four lenses on the same run.
- Task success rate. The headline number: of N test tasks, what fraction reached the correct end state? "End state" is the key idea — for an agent, success often isn't a string match but a condition you can check: was the calendar event created, did the SQL return the right rows, does the code pass its tests? You write a checker per task.
- Trajectory quality. Did the agent take a reasonable path? You compare its sequence of steps against a known-good reference (exact-match, in-order, or any-order overlap), or you have a judge rate whether the path was logical and free of pointless detours.
- Tool-call accuracy. At each step where the agent used a tool, did it pick the right tool, with the right arguments, at the right time? This is often where agents fail — they call a search tool when they should call the database, or pass a malformed argument.
- Efficiency. How many steps, how many tokens, how much wall-clock latency, and how many dollars did it take to reach the answer? Two agents with identical success rates can differ 10x here, and in production that gap is the whole ballgame.
Who does the grading?
Once you've decided what to measure, you need a grader. There are three, and real pipelines mix them:
| Grader | Best for | Watch out for |
|---|---|---|
| Code / rules | Checkable outcomes: API state, exact values, tests passing, JSON schema valid | Can't judge fuzzy quality like tone or 'helpfulness' |
| LLM-as-judge | Open-ended quality: was the answer faithful, was the path reasonable, was the summary good | Needs a clear rubric; can be biased or inconsistent — validate it against humans |
| Human review | The ground truth you trust most; building the first labeled set | Slow and expensive; doesn't scale to every run |
A common, practical pattern: use code checks for everything you can verify exactly, fall back to an LLM judge for the fuzzy parts, and keep a small set of human-reviewed examples to make sure your automated graders actually agree with people.
Worked example: scoring one agent run
Numbers click into place once you score a real run. Say we have a support agent and the task: "A customer with order #5521 wants to know if it shipped, and if not, cancel it." Here is the trajectory the agent produced.
Now grade it across all four families instead of just shrugging "looks right":
| Metric | Result | Why |
|---|---|---|
| Task success | Pass | End state is correct: order is cancelled, customer was told the status. A code check on the order's status confirms it. |
| Trajectory quality | Partial | The needed steps are present and in a sensible order, but Step 2 (web search) and the duplicate lookup in Step 3 are detours that shouldn't be there. |
| Tool-call accuracy | 3 / 4 | get_order, cancel_order, and the final get_order were the right tools with right args. The search_web call was the wrong tool entirely. |
| Efficiency | Below target | 4 tool calls where 2 would do; the wasted search added tokens, latency, and cost. Set a budget and this run exceeds it. |
Run this same scoring over a suite of tasks — say 50 representative ones — and you get the real picture: a task-success rate (e.g. 46/50 = 92%), an average tool-call accuracy, a distribution of step counts and costs, and a list of the trajectories that went sideways. That dashboard, not a single number, is what tells you the agent is ready.
Building an eval suite you can trust
A metric is only as good as the tasks you run it on. A few practical rules for assembling the suite:
- Use real, representative tasks. Pull them from actual user logs, not from your imagination. The cases that break agents are the messy, ambiguous ones you wouldn't think to invent.
- Define success as a checkable condition, per task. "Order is cancelled" beats "answer mentions cancellation." Where you can, assert on state (the database, the API, the file), not on words.
- Cover the unhappy paths. Include tasks where the right move is to refuse, ask a clarifying question, or report that something is impossible. An agent that confidently does the wrong thing should fail your suite.
- Set explicit budgets. Decide up front the max steps, tokens, latency, and cost a task may use, and count overruns as a failure (or a separate metric). Without a budget, 'success at any cost' silently wins.
- Keep a held-out set. Don't tune your prompts against the same tasks you report scores on, or you'll just overfit to them.
If you've evaluated a RAG system before, the suite-building discipline is the same — fixed task set, automated graders, held-out data — but agents add the trajectory and cost dimensions on top of plain answer quality.
Going deeper
The four-family framework above is the foundation. A few directions worth knowing once it's second nature.
Component vs end-to-end evaluation. You can evaluate the whole agent as a black box (task in, result out) or break it apart and test pieces in isolation — just the tool-use layer, just the planner, just the retrieval step. Component tests pinpoint which part regressed; end-to-end tests tell you whether the system as a whole still works. Serious pipelines run both, the same way software has unit tests and integration tests.
Trajectory matching is genuinely hard. Comparing an agent's path to a 'golden' one sounds clean but breaks down fast: there are often many valid routes to the same answer, so exact-match is too strict, while loose overlap is too forgiving. This is why teams lean on an LLM judge with a rubric ("was each step justified by the previous observation?") rather than rigid sequence comparison — and why you must validate that judge against human labels before trusting it.
Robustness and safety as their own axes. Beyond "does it work," production agents need to be probed for what happens under adversarial input — a retrieved document carrying hidden instructions, an ambiguous request, a tool that returns an error. Measuring how often the agent does something unsafe or irreversible (and whether it recovers from tool failures) is a distinct evaluation from task success, and increasingly the one that gates a launch.
Online vs offline. Everything above is offline evaluation — a fixed suite you run before shipping. Online evaluation watches the live system: logging real trajectories, sampling them for an LLM judge or human review, and tracking success and cost as traffic and the world drift. The honest, durable lesson is that an agent is never 'evaluated once.' Because models, prompts, tools, and user behavior all keep moving, the suite is a living asset you grow as new failure modes appear — and the score you trust most is the one measured on yesterday's real traffic.
FAQ
Why isn't accuracy enough to evaluate an AI agent?
Because an agent acts over many steps, not just answers once. Accuracy only checks the final output, so it can give full marks to a run that took a wrong, lucky path, called the wrong tool, caused a side effect, or cost 10x more than needed. You also need to measure the trajectory (the steps), tool-call correctness, and efficiency.
What is task success rate for an agent?
It's the fraction of test tasks where the agent reached the correct end state — not a string match, but a condition you can check, like 'the calendar event was created' or 'the SQL returned the right rows.' You write a checker per task and report the pass rate over a suite of representative tasks.
What is trajectory evaluation?
Trajectory evaluation scores the path an agent took — its full sequence of thoughts, tool calls, and observations — instead of only the final answer. You either compare the steps against a known-good reference or have an LLM judge rate whether each step was justified and free of pointless detours. It tells you why a run worked or failed.
How do I measure an agent's cost and efficiency?
Track four things per task: number of steps (tool calls), tokens consumed, wall-clock latency, and dollar cost. Set an explicit budget for each and count overruns as a failure or a separate metric. Two agents with identical success rates can differ 10x on cost, and in production that gap usually decides which one you ship.
When should I use an LLM as a judge to evaluate agents?
Use an LLM judge for the fuzzy parts you can't check with code — whether an answer was faithful, a summary was good, or a trajectory was reasonable. Use plain code or rules whenever the outcome is exactly checkable (API state, test pass, valid JSON). Always validate the judge against a small set of human-labeled examples, since judges can be biased or inconsistent.
How many times should I run each evaluation task?
More than once. Agents are non-deterministic, so the same task can take different paths on different runs. Run each task several times and report a success rate (e.g. 9 of 10) along with the variance. A 90% agent with low variance is far more trustworthy than a 90% one whose results swing wildly.