In plain English
A benchmark is a fixed test — a set of math problems, coding tasks, or trivia questions with known answers — that everyone runs their model against to compare scores. The whole point is that a high score should mean the model is genuinely good at that kind of task.
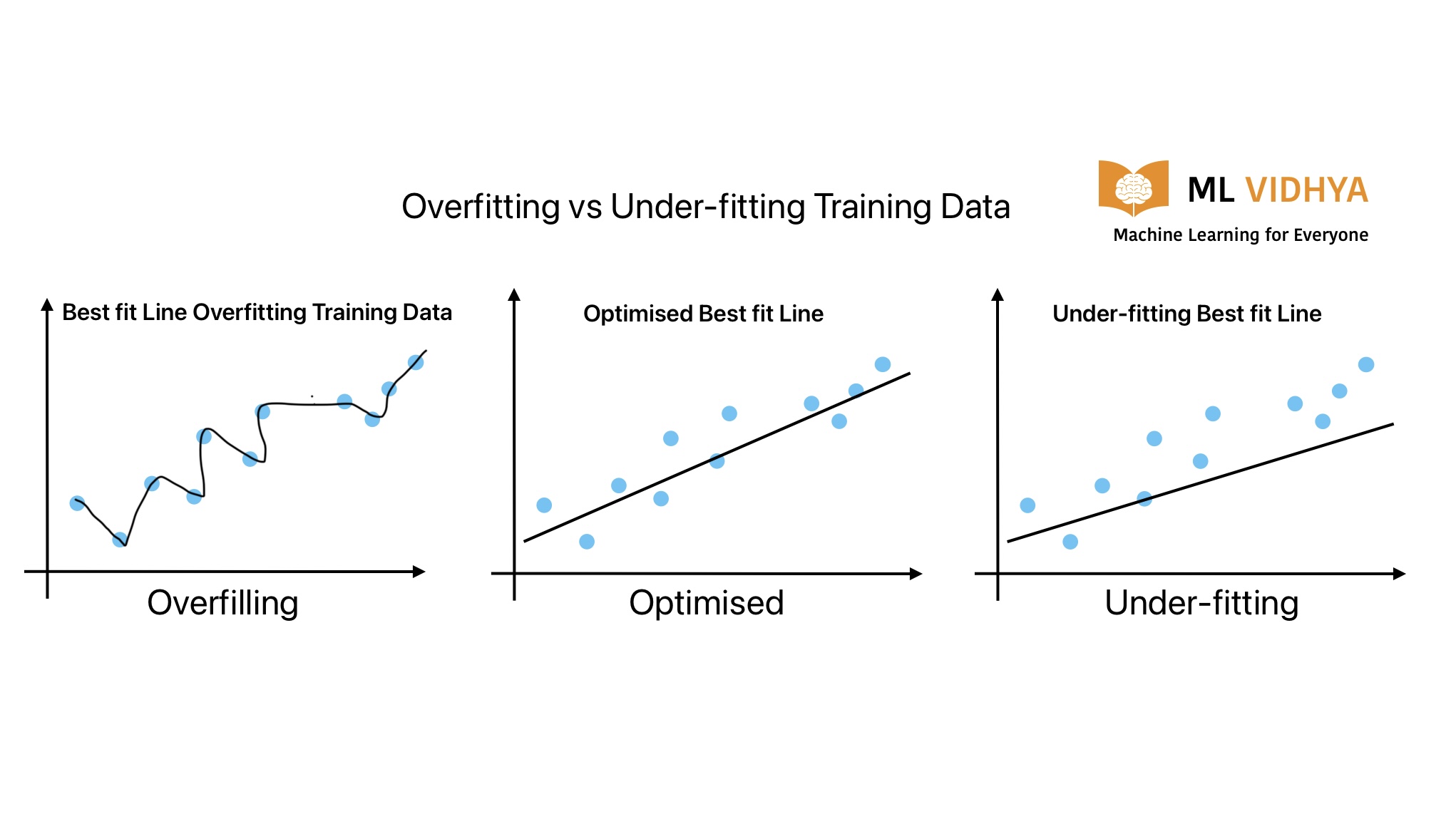
Benchmark overfitting is what happens when a model gets really good at the test itself instead of the ability the test was meant to measure. The score climbs, but the underlying skill doesn't. The model has learned the quirks, formats, and shortcuts of that specific benchmark — and those tricks don't transfer to the messy real questions users actually ask.
Think of a student cramming for a driving theory exam by memorizing the answer to every question in the official practice booklet. They ace the test with a perfect score. But put them on a real road with an unexpected situation the booklet never covered, and they freeze. They optimized for passing the exam, not for driving well. The exam was supposed to be a proxy for driving skill; once the student games it, the score stops telling you anything about the road.
Why it matters
Benchmark scores drive enormous decisions. A new model that tops a leaderboard gets headlines, funding, and customers. So there is huge pressure to make the number go up — and that pressure is exactly what causes overfitting.
The deep reason is a principle called Goodhart's law: when a measure becomes a target, it stops being a good measure. The moment a benchmark turns from a thermometer (something you read) into a goal (something you push on), people start optimizing the number directly, and the number drifts away from the real thing it was supposed to track.
Here is why a builder should care, concretely:
- You pick the wrong model. You read a leaderboard, choose the top scorer, ship it — and users complain it feels worse than the model ranked third. The benchmark and your real workload diverged.
- Progress looks faster than it is. A field can show steady benchmark gains while real-world capability barely moves, because everyone is grinding the same few tests. The graph goes up; the product doesn't get better.
- Your own evals can rot too. This isn't just a big-lab problem. If you tune your prompts and your model against your one internal eval set over and over, you'll eventually overfit that set and stop measuring real quality.
- Comparisons stop being fair. Two models with identical scores can have wildly different real ability if one was optimized hard for that benchmark and the other wasn't.
How it works
Overfitting to a benchmark almost never comes from a single decision to cheat. It builds up gradually through ordinary, well-intentioned engineering — each step reasonable on its own, but together they bend the model toward the test.
The optimization loop that drifts
A team picks a benchmark to track. They train a model, measure the score, change something — the training data mix, the prompt format, a fine-tuning pass — and keep whatever made the number go up. Repeat hundreds of times. Each kept change that helped this benchmark but not real ability quietly bakes the test's quirks into the model.
Nothing here is dishonest. The team never sees the hidden test answers. But over many rounds, the model learns the benchmark's surface patterns: its preferred answer format, its common question phrasings, the kinds of distractors it uses, even the topics it happens to favor. Skill on that one test rises; transfer to new questions does not.
Why the score and the real skill split apart
A benchmark is only a sample of a much bigger space of real tasks. When you optimize against the sample directly, you improve on the sample's specific quirks rather than the whole space behind it. The benchmark score and the true ability start as close partners and then diverge — the gap between them is exactly the overfitting.
The tell-tale signature is a model that scores far higher on the public benchmark than on a fresh, equivalent set of questions it has never been tuned against. If a model gets 92% on the well-known test and 71% on brand-new problems of the same difficulty, that 21-point gap is the overfitting laid bare. On a benchmark it has never optimized against, an overfit model is roughly average; only on its target test does it shine.
Overfitting vs contamination
These two failures get lumped together because both make a benchmark score lie. But they are different mechanisms with different fixes, and telling them apart helps you reason about why a score might be inflated.
| Benchmark overfitting | Benchmark contamination | |
|---|---|---|
| What happens | Model is optimized hard toward one benchmark's quirks | Test questions or answers leaked into training data |
| Did the model see the answers? | No — the lab plays fair | Yes — directly or indirectly |
| Is it intentional? | Usually not; it creeps in over many tuning rounds | Often accidental (web scraping), sometimes deliberate |
| Root cause | Goodhart's law — the measure became the target | Data leakage into the training set |
| How to detect | Big gap vs a fresh, equivalent held-out test | Model recalls exact test items / scores spike on memorized data |
| Main fix | Rotate/refresh benchmarks; test on private data | Decontaminate training data; use hidden or live tests |
They can also stack. A benchmark that has been around for years tends to suffer from both: its items have slowly seeped into training corpora across the web (contamination), and the whole field has been grinding against it (overfitting). That's why veteran benchmarks like older multiple-choice knowledge tests are treated with suspicion long before any single model is accused of anything.
How to spot and avoid it
You can't see inside a lab's training runs, but you can check whether a score generalizes. The core move is always the same: compare performance on the public benchmark against performance on something it could not have been tuned for.
Reading other people's scores skeptically
- Cross-check across benchmarks. A genuinely strong model tends to do well across many tests. A model that dominates one leaderboard but sits mid-pack elsewhere is a classic overfitting pattern.
- Prefer fresh and private tests. Live, rotating evaluations like Chatbot Arena and held-out, frequently-refreshed benchmarks are much harder to overfit than a static public test that hasn't changed in two years.
- Watch for suspiciously round wins. A model that beats everyone by a wide margin on one popular benchmark, but only ties them on a newer or private one, is waving a red flag.
- Discount old benchmarks. The longer a test has been public, the more both overfitting and contamination have had time to inflate scores on it.
Protecting your own evaluations
If you build with LLMs, you run your own evals — and you can overfit them just like the big labs overfit theirs. A few habits keep your numbers honest:
- Hold out a test set you never tune against. Split your data into a development set you iterate on and a locked test set you only touch occasionally. If dev-set scores climb but the test set doesn't, you're overfitting your prompts.
- Refresh your eval questions. Periodically add new examples drawn from real production traffic so the eval keeps tracking reality instead of becoming a museum piece.
- Keep a golden dataset you trust. A small, carefully built reference set is worth more than a huge auto-generated one you've quietly tuned against.
- Don't optimize a single metric to death. If you only chase one number, expect Goodhart's law to come for it. Track several signals — accuracy, faithfulness, latency, user satisfaction — so no single proxy can be gamed alone.
Going deeper
Once the basic idea clicks, a few deeper nuances are worth knowing — they explain why this problem is structural and won't ever fully go away.
Overfitting is mostly invisible from the outside. Unlike contamination, which leaves fingerprints (a model can be caught reciting verbatim test items), overfitting rarely produces a smoking gun. The model never saw the answers; it just got steadily better at the shape of one test. That's why the community relies on indirect signals — held-out gaps, cross-benchmark inconsistency, the feel of real use — rather than a single clean detector.
The whole field overfits, not just one model. Even with no single team behaving badly, a popular benchmark drives collective overfitting: thousands of researchers tweak ideas against the same test, and only the tweaks that happen to raise that score survive and spread. The benchmark slowly stops separating good models from bad — its scores compress at the top and it gets 'saturated.' This is why useful benchmarks have a shelf life and the field keeps having to invent harder ones.
Live and adversarial benchmarks are the main defense. Tests that change constantly are far harder to overfit. Human-preference systems where fresh prompts arrive continuously, benchmarks that hide their test set and only release a leaderboard, and agent benchmarks built on real, evolving tasks all resist the optimization loop better than a frozen file of questions. The price is that they're harder to run and reproduce.
It connects to a real research debate: memorization vs generalization. Some benchmark gains reflect a model genuinely getting smarter; some reflect it getting better at that specific test. Separating the two is an open problem at the heart of how we evaluate AI. The honest stance: a benchmark is a useful, cheap proxy, but it is always a proxy. The day you forget that and treat the number as the goal, Goodhart's law starts dismantling its meaning. Next, see how LLM evals and a well-built eval suite let you measure what actually matters for your use case rather than chasing someone else's leaderboard.
FAQ
What is benchmark overfitting in AI?
It's when a model is optimized so heavily toward one specific benchmark that its score on that test no longer reflects its real ability. The model learns the test's quirks — its format, phrasing, and common patterns — rather than the general skill the test was meant to measure, so the high score doesn't transfer to real-world tasks.
How is benchmark overfitting different from contamination?
Contamination means the test questions or answers leaked into the training data, so the model has literally seen them. Overfitting is different: the lab never sees the answers and plays fair, but optimizes so hard toward that one benchmark's quirks that the score loses meaning. Contamination is cheating on the answer key; overfitting is teaching to the test.
What is Goodhart's law and how does it apply to benchmarks?
Goodhart's law says that when a measure becomes a target, it stops being a good measure. Applied to AI, the moment a benchmark turns from something you read into something you push on, people optimize the number directly and it drifts away from the real ability it was supposed to track. That drift is exactly benchmark overfitting.
Why does a model top a leaderboard but feel worse in practice?
Because the leaderboard score may be inflated by overfitting. The model was tuned toward that benchmark's specific quirks, which don't match your real workload. Your tasks are a different sample of the world than the benchmark, so a model optimized for the test can underperform on the messy questions your users actually ask.
How can I tell if a benchmark score is inflated by overfitting?
Compare the public benchmark score against performance on a fresh, equivalent set of questions the model couldn't have been tuned against. A large gap between the two is the signature of overfitting. Also cross-check across many benchmarks — a model that dominates one but sits mid-pack on others is a classic warning sign.
Can my own internal evals overfit too?
Yes. If you repeatedly tune your prompts and model against the same eval set, you'll eventually overfit that set and stop measuring real quality. The fix is to keep a locked held-out test set you rarely touch, refresh your eval questions with real production data, and avoid optimizing a single metric to death.