In plain English
When you use an LLM as a judge, you hand a model some output and ask it to grade it: is this answer correct? rate its helpfulness 1 to 5. The fastest way to write that prompt is to ask for the number directly. But the fastest prompt is usually the worst one.
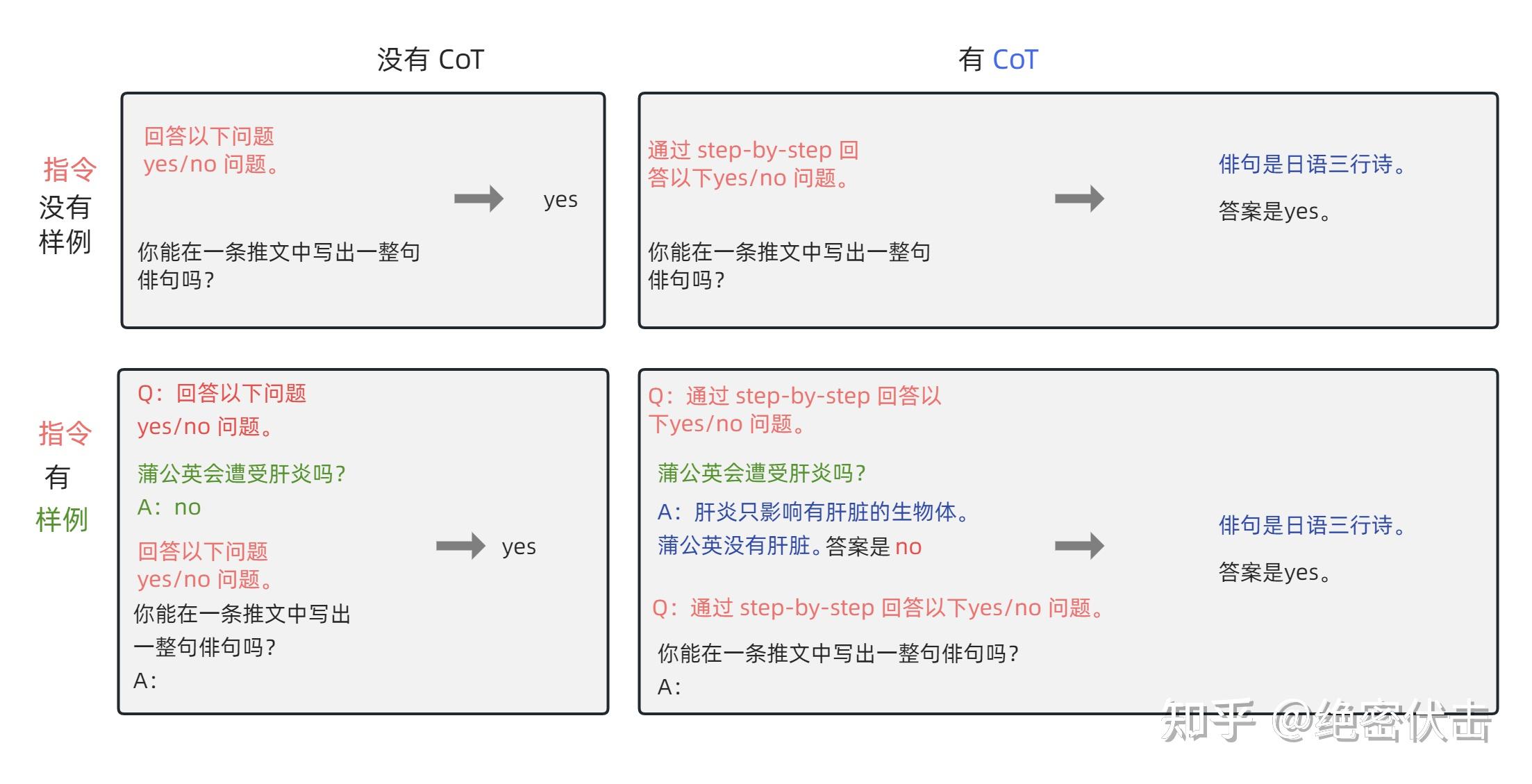
A chain-of-thought judge prompt flips the order. Instead of asking for a score up front, you ask the judge to reason first — walk through the criteria, point out what's good and bad, check the answer against a rubric — and only then commit to a score. The reasoning is the model's working; the score is the conclusion it reaches after doing that work.
Think of two ways to grade an exam. The lazy grader skims a page and scribbles a number in the corner. The careful grader reads the answer, marks each point in the margin, notes where the student went wrong, then totals the marks. Both produce a number, but only the second one can show you why. A chain-of-thought judge is the careful grader: the marks in the margin are the model's reasoning, and the total is the score.
Why it matters
A judge is only useful if you can trust its grades. If your judge is noisy or wrong, every number that depends on it — your eval dashboard, your regression checks, your "version B beat version A" claim — is built on sand. Reasoning-before-scoring is one of the cheapest, most reliable ways to make a judge better, and it pays off in three concrete ways.
- More accurate grades. Forcing the model to examine the answer against the criteria before scoring tends to align its grades more closely with what a careful human would give. A score blurted out in one token has no analysis behind it; a score that follows a paragraph of checking does.
- More consistent grades. Run the same score-first prompt twice and you can get 3 then 4 for no reason. When the model has to justify itself first, its scores wobble less from run to run, because the reasoning anchors the number instead of the number coming from a coin-flip.
- Auditable errors. This is the quiet superpower. When a chain-of-thought judge gets something wrong, the rationale tells you why — it misread the rubric, it penalized something it shouldn't have, it missed a fact. A bare number gives you nothing to debug. With reasoning, a wrong grade is a bug report.
That last point matters more than people expect. Judges drift, rubrics have holes, and prompts have bugs. If your judge only emits numbers, the only way to find these problems is to manually re-grade a sample by hand. If it emits reasoning, you can read why it scored the way it did and catch a broken judge before it quietly corrupts a whole eval run. The rationale turns your judge from a black box into something you can inspect.
How it works
The mechanism is almost embarrassingly simple: you change the order of what the prompt asks for, and you make the reasoning structured rather than free-floating. Instead of "give me a score," the prompt walks the judge through a short procedure — restate the criteria, evaluate the answer against each one, then output the score — and asks for all of it in a parseable shape.
- "Rate this answer 1–5."
- Model emits a number immediately
- No analysis behind it
- Noisy, run-to-run wobble
- A wrong grade is unexplainable
- "Check each criterion, then score."
- Model reasons, then commits
- Score follows the analysis
- More stable across runs
- A wrong grade shows its work
Why does order matter so much? Because a language model generates one token at a time, left to right, and each token it writes becomes context for the next. If the score comes first, the model has to decide it with nothing to lean on, and then any "reasoning" after it is just a story made up to fit a number it already committed to. If the reasoning comes first, the score is generated after the analysis, so it can actually be shaped by it. The reasoning has to lead, or it isn't reasoning — it's an excuse.
The rationale-then-score pattern
A solid chain-of-thought judge prompt has four moving parts, in this order:
You spell out the rubric so the judge grades against your definition of quality rather than its own vibes. You ask it to evaluate each criterion in turn — a checklist forces it to actually look, instead of forming a gut feeling. You ask for the score last. And you make the output structured (typically JSON) so your code can reliably pull the number out of a known field while keeping the rationale around for logging.
You are grading an answer against a rubric. Score from 1 to 5.
Rubric:
- Factual accuracy: every claim must be supported by the reference.
- Completeness: the answer covers all parts of the question.
- Clarity: the answer is easy to follow.
Question: {question}
Reference answer: {reference}
Answer to grade: {candidate}
First, reason step by step. For EACH rubric item, state whether the
answer meets it and quote the evidence. THEN give a final score.
Return JSON only:
{"reasoning": "<your per-criterion analysis>", "score": <1-5>}A worked example
Here's the same judge wired up in code. The only thing that makes it a chain-of-thought judge is the prompt above and the order of the JSON fields — everything else is ordinary plumbing. We log the reasoning so a wrong score is debuggable later.
import json
from anthropic import Anthropic
client = Anthropic(api_key="sk-ant-...")
RUBRIC = """\
- Factual accuracy: every claim is supported by the reference.
- Completeness: covers all parts of the question.
- Clarity: easy to follow."""
def judge(question, reference, candidate):
prompt = (
f"You grade an answer against a rubric. Score 1-5.\n\n"
f"Rubric:\n{RUBRIC}\n\n"
f"Question: {question}\nReference: {reference}\n"
f"Answer to grade: {candidate}\n\n"
"First reason step by step: for EACH rubric item say whether "
"the answer meets it and quote the evidence. THEN give a score.\n"
'Return JSON only: {"reasoning": "...", "score": <1-5>}'
)
msg = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=600, # leave room for the reasoning!
temperature=0, # determinism for grading
messages=[{"role": "user", "content": prompt}],
)
result = json.loads(msg.content[0].text)
# Keep BOTH: the score for metrics, the reasoning for auditing.
return result["score"], result["reasoning"]
score, why = judge(
"What year did the Apollo 11 mission land on the Moon?",
"Apollo 11 landed on the Moon on July 20, 1969.",
"Apollo 11 reached the Moon in 1968.",
)
print(score) # e.g. 2
print(why) # "Factual accuracy: FAILS — answer says 1968, reference says 1969..."Two details are doing real work here. max_tokens must be large enough to hold the reasoning, not just the number — if you cap it too low, the model runs out of room mid-rationale and the JSON never closes. And temperature=0 makes grading as deterministic as the model allows, so the same answer gets the same grade twice. The reasoning is logged alongside the score, so when someone disputes a grade weeks later, you can read exactly what the judge thought.
When it helps — and when it doesn't
Reasoning-before-scoring is a strong default, but it isn't free and it isn't magic. The payoff is biggest when the judgment is genuinely hard; it shrinks to nothing when the judgment is trivial.
| Situation | Reason-then-score? | Why |
|---|---|---|
| Nuanced quality (helpfulness, faithfulness, tone) | Yes | The analysis is exactly where the accuracy gain lives. |
| Multi-criterion rubric | Yes | A per-criterion checklist stops the judge skipping items. |
| You need to debug or trust grades | Yes | The rationale makes every score auditable. |
| Exact-match / regex-checkable correctness | No | Use a code-graded check — it's free, instant, and exact. |
| Hard latency or cost budget | Maybe | Reasoning adds output tokens; measure if the accuracy is worth it. |
| Simple binary with an obvious answer | Often no | If a one-token verdict is already reliable, reasoning adds cost for little gain. |
The honest tradeoff is cost and latency. Reasoning is extra output tokens, and output tokens are the slow, expensive ones. A judge that writes a paragraph before each score costs several times more than one that emits a bare number, and it's slower. For a nightly eval run over a few hundred examples that's nothing; for grading live traffic in the request path it can matter. The rule of thumb: spend the reasoning where a wrong grade is costly or where you'll need to audit it, and skip it where a cheap exact check already does the job.
Going deeper
Once the basic rationale-then-score pattern is in place, a few refinements separate a decent judge from a dependable one.
Reasoning curbs bias, but doesn't erase it. Judges have well-known tendencies — preferring longer answers, favoring the first option shown, rating their own model's outputs higher. Forcing per-criterion reasoning helps because the judge has to point to evidence rather than react to surface features, but it's not a cure. You still need the defenses in LLM judge biases and the broader traps in LLM judge pitfalls.
The rationale is a feature, so test it. Spot-check that the reasoning actually matches the score. A common failure mode is a judge that writes a glowing rationale and then gives a 2, or trashes an answer and gives it a 5 — the reasoning and the number have come apart. When that happens, the judge isn't really reasoning toward the score; tighten the prompt so the score must follow from the analysis, and consider asking it to state which criteria passed and failed explicitly before totalling.
Pairwise judging benefits too. Chain-of-thought isn't only for rubric scoring. When you ask a judge to pick the better of two answers — see pairwise vs rubric judging — making it compare the two on each criterion before declaring a winner produces steadier, less position-biased verdicts than "just tell me A or B."
Validate the judge against humans. Reasoning makes a judge more trustworthy, but "more trustworthy" isn't "correct." The only way to know your judge is good is to grade a labelled sample by hand and check how often the judge agrees with you. Build that habit early — see what are LLM evals and how to build an eval suite. A chain-of-thought judge that agrees with careful humans 90% of the time is a tool you can lean on; one you never checked is just a confident guess wearing a rationale.
FAQ
Why ask an LLM judge to reason before scoring instead of just giving a number?
Because a model generates text left to right, a score emitted first has no analysis behind it and any reasoning after it is just a justification for a number already chosen. Putting the reasoning first lets the analysis actually shape the score, which makes grades more accurate and more consistent run to run.
Does the order of fields in the JSON output matter?
Yes, a lot. The model fills fields in the order you list them, so if score comes before reasoning it writes the score first and the reasoning becomes a post-hoc excuse. Always put reasoning before score in the output schema so the model thinks before it commits.
Does chain-of-thought judging cost more?
Yes. The reasoning is extra output tokens, which are the slow, expensive ones, so a reasoning judge can cost several times more than a bare-number judge and run slower. For offline eval runs that's negligible; for grading live traffic in the request path, measure whether the accuracy gain is worth the latency.
Does making the judge reason fix bias?
It helps but doesn't fix it. Forcing per-criterion reasoning makes the judge point to evidence instead of reacting to surface features like answer length or option order, which reduces some biases. But judges can still favor longer answers or their own model's outputs, so you still need dedicated bias defenses and human validation.
When should I NOT use a chain-of-thought judge?
When the check is exactly verifiable in code — exact match, regex, a number in a range — use a code-graded check instead; it's free, instant, and exact. Reasoning judges are for nuanced, multi-criterion quality judgments where there's no simple right answer to test against.
How do I keep the reasoning for debugging without it cluttering my metrics?
Have the judge return structured output (JSON) with separate reasoning and score fields. Your metrics code reads only the score field, while you log the full reasoning alongside it. When a grade is later disputed, you can read exactly why the judge scored as it did.