In plain English
When you read that a model has 7 billion parameters or 405 billion parameters, the parameters are simply the numbers the model learned during training. Each one is a single value — a weight — that the model adjusts, over and over, until it gets good at predicting text. A modern large language model is, underneath all the polish, just an enormous list of these numbers and the arithmetic that combines them.
Picture a giant mixing board in a recording studio, but with billions of tiny knobs instead of a few dozen. Each knob is a parameter. On its own, one knob means almost nothing. But turn all of them to exactly the right settings and the board can reproduce music, speech, code — any pattern it was tuned for. Training is the slow process of finding those settings; the finished model is the board with every knob frozen in place.
So "7B" is shorthand for "this model has roughly 7 billion of those knobs." The B means billion. A 70B model has about ten times as many knobs as a 7B one. None of these numbers are typed in by a human — they emerge automatically from feeding the model huge amounts of text and nudging every knob a hair at a time toward better predictions.
Why it matters
If you build with AI, the parameter count is one of the first numbers you'll see on every model card — and it quietly decides three very practical things.
- How much memory and hardware you need. Every parameter is a number that has to be loaded into memory to run the model. More parameters means more memory, which usually means bigger or more GPUs. A 7B model can run on a single consumer GPU; a 405B model needs a cluster of expensive datacenter cards.
- How much it costs and how fast it answers. Bigger models do more arithmetic per word they produce, so they are slower and cost more per request. When a provider charges more for its "large" model than its "small" one, parameter count is a big part of why.
- Roughly how capable it can be. All else equal, more parameters give a model more room to store patterns and nuance. That's why frontier models are huge. But — and this is the part everyone gets wrong — all else is almost never equal, so the count alone tells you surprisingly little about real-world quality.
That last point is the reason this article exists. Parameter count is the headline number marketing loves, and beginners often treat it like horsepower: bigger must be better. In reality a well-trained 8B model can beat a sloppily-trained 70B model on the tasks you care about. Knowing what the number does — and doesn't — measure keeps you from overpaying for size you don't need, or dismissing a small model that would do the job.
How it works
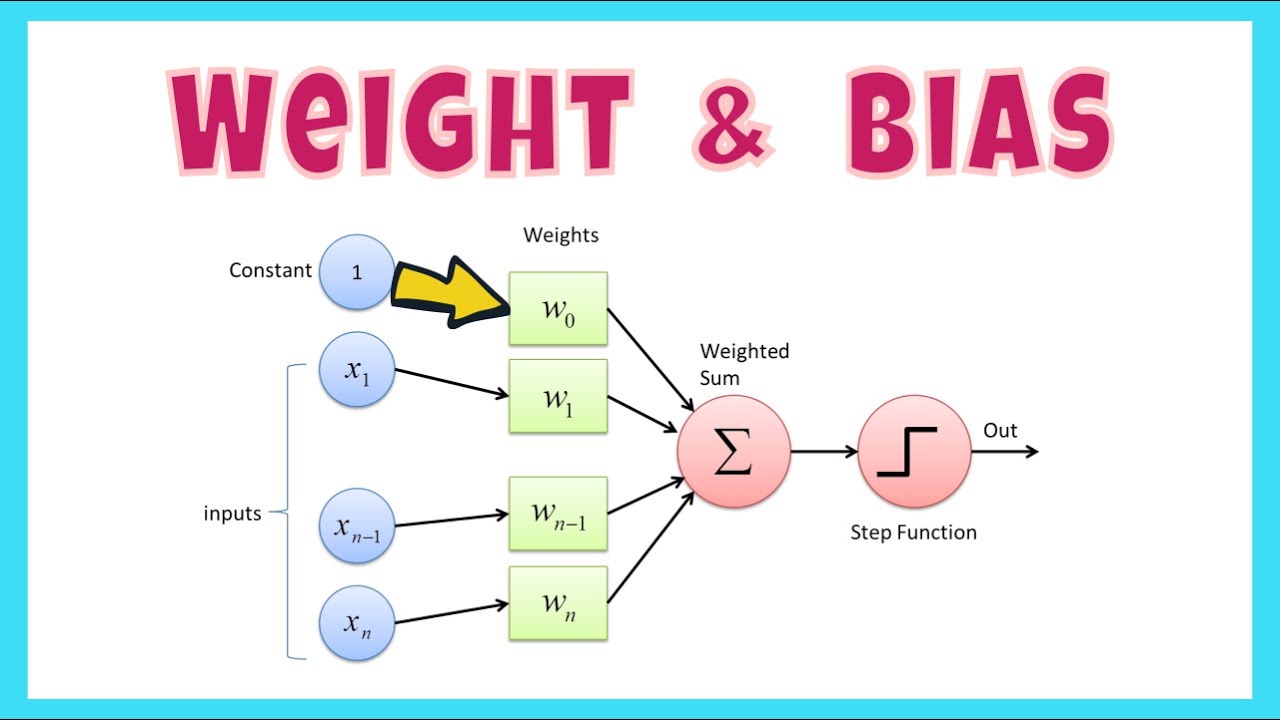
To see where the billions come from, you only need the rough shape of how a model computes. A neural network is built from layers of artificial neurons. Each neuron takes in numbers, multiplies each input by one of its weights, adds them up, and passes the result on. The weights are the parameters. Stack enough layers with enough neurons and the count explodes into the billions. (For the bigger picture of this prediction loop, see how LLMs work.)
How a number becomes a learned weight
Every weight starts as a small random value — the model knows nothing. Training then repeats a simple loop millions of times: show the model some text, let it predict the next token, measure how wrong it was, and nudge every weight a tiny step in the direction that would have made the prediction less wrong. Do this across trillions of words and the once-random knobs settle into settings that encode grammar, facts, and reasoning patterns.
Crucially, once training finishes the weights are frozen. When you chat with a model, none of its parameters change — it is just running the same fixed arithmetic on your input. That's why a base model can't "remember" your last conversation in its weights: learning new facts that way would require another training run. (Techniques like fine-tuning do change a model's weights, but that's a separate, deliberate process.)
Why the count reaches billions
The numbers feel absurd until you see the multiplication. A single layer that maps 4,096 inputs to 4,096 outputs already needs 4,096 × 4,096 ≈ 17 million weights — just for one layer. A large model stacks dozens of such layers, plus the big tables that turn tokens into vectors. Multiply it out and you land in the billions or hundreds of billions. The shorthand just rounds that total: a model with 6.7 billion weights is marketed as 7B.
Decoding 7B, 70B, and 405B
Model names are littered with parameter shorthand. Here's how to read it and what each tier roughly means for you in practice. (Hardware figures are rough rules of thumb, not guarantees — exact memory depends on the number format the weights are stored in.)
| Shorthand | Parameters | Rough tier | Typical home |
|---|---|---|---|
| 1B–3B | 1–3 billion | Tiny / on-device | Phone, laptop, browser |
| 7B–8B | ~7–8 billion | Small, very usable | One consumer GPU |
| 70B | ~70 billion | Strong open model | Multiple GPUs / a server |
| 405B+ | 405 billion and up | Frontier scale | A GPU cluster |
A rough memory rule helps make this concrete. If each parameter is stored as a 16-bit number (2 bytes), a 7B model needs about 7B × 2 = 14 GB of memory just to hold its weights, before any conversation. A 70B model needs roughly 140 GB. This is exactly why bigger models demand more or larger GPUs — and why quantization, which stores each weight in fewer bits, is so popular: it shrinks that memory bill at a small cost to quality.
Why bigger isn't always better
If parameters were the whole story, you'd just pick the biggest model and be done. But two models with the same count can differ wildly in quality, and a smaller model often beats a larger one. Several factors matter at least as much as raw size.
- Training data quality and quantity. A model is shaped by what it reads. Train on more, cleaner, better-curated text and a smaller model can outperform a bigger one trained on noisy data. Modern small models are strong largely because they were trained on far more, better-filtered tokens than older large ones.
- The training recipe. Architecture choices, how long training ran, and post-training steps like instruction tuning all change the result. An instruction-tuned model feels dramatically more helpful than a raw base model of identical size.
- Mixture-of-Experts (MoE). Many big models only activate a fraction of their parameters per token. A model can advertise a huge total count but run with the speed and cost of a much smaller one, because most experts sit idle on any given word.
- The task. For summarizing emails or simple classification, a 7B model may be indistinguishable from a 70B one — while costing a fraction. Size pays off most on hard reasoning, niche knowledge, and long, complex instructions.
There is a real, well-studied relationship between size, data, compute, and capability — that's the subject of scaling laws. But scaling laws describe a trend across carefully-matched training runs, not a promise that any random 70B model beats any random 7B one. For your decision, the honest rule is: pick by measured performance on your task, not by the headline count.
- More parameters = smarter
- Pick the biggest model
- Count is the quality score
- Small models are toys
- Data + recipe matter as much
- Pick the smallest model that passes your tests
- Count predicts memory and cost more than quality
- Small models win on many real tasks
Going deeper
Once the basics click, a few finer points round out the picture and explain numbers you'll bump into on model cards and in papers.
Total vs active parameters. With Mixture-of-Experts models the gap matters. A model might list, say, 100B total parameters but only use a much smaller slice per token. "Total" tells you the memory footprint; "active" tells you the speed and cost per word. When you compare MoE and dense models, compare the active count for a fair read on compute.
Precision and quantization. The same set of weights can be stored at different numeric precisions — 32-bit, 16-bit, 8-bit, even 4-bit. Lower precision means each parameter takes fewer bytes, so the model loads in less memory and runs faster, usually with only a small quality loss. This is why you'll see the same model offered in several sizes-on-disk: the parameter count is identical, but the bytes-per-parameter differ.
Parameters are not knowledge you can edit. It's tempting to imagine a fact lives in one specific weight you could change. In reality knowledge is smeared across millions of parameters in ways no one can cleanly point to. That's why you can't just "open the file and fix a wrong fact," and why approaches like retrieval (giving the model documents at question time) exist instead of surgery on individual weights.
Closed models often don't publish the number. Many leading commercial models never disclose their parameter count at all. That's a useful reminder that the figure is an input to a model's quality, not the quality itself — providers compete on benchmarks and real output, and you should too. To go further, see how ChatGPT works for the full pipeline these parameters drive, or why LLMs need GPUs for the hardware side of holding billions of numbers in memory.
FAQ
What does 7B parameters mean?
It means the model has about 7 billion learned numbers (the "B" is for billion). Each parameter, or weight, is a value the model tuned during training to get better at predicting text. A 7B model is on the small-but-very-usable end and can typically run on a single consumer GPU.
What is the difference between a parameter and a weight?
They're used almost interchangeably. Strictly, weights are the multiplier values inside the network and biases are small offsets added alongside them; "parameters" is the umbrella term for both. When someone says a model has 7B parameters, they mean the total count of all weights and biases.
Do more parameters always mean a better AI model?
No. More parameters give a model more capacity, but training data quality, the training recipe, instruction tuning, and the task all matter at least as much. A well-trained smaller model often beats a poorly-trained larger one, so you should judge by measured performance on your task rather than by the headline count.
How much memory does a model need based on its parameters?
A rough rule is parameters × bytes-per-parameter. At 16-bit precision that's about 2 GB per billion parameters, so a 7B model needs roughly 14 GB just to load its weights. Quantizing to 8-bit roughly halves that. It's an underestimate because running the model also needs extra working memory.
Why don't companies always reveal a model's parameter count?
Many commercial providers treat the figure as proprietary and compete on benchmark results and real output instead. It's a good reminder that parameter count is an input to quality, not quality itself — so you can't rank closed models by size, and shouldn't try.
Can I change a model's parameters to fix a wrong answer?
Not easily. Knowledge is spread across millions of parameters with no single weight you can point to, so you can't open the file and edit one fact. Instead, people use fine-tuning (a controlled retraining that adjusts many weights) or retrieval (feeding the model correct documents at question time).