In plain English
The transformer architecture has three distinct body plans — encoder-only, decoder-only, and encoder-decoder — and the choice of body plan determines what a model is good at. BERT is encoder-only; GPT, Claude, and Llama are decoder-only; T5 and BART are encoder-decoder. If you've ever wondered why you reach for a different model depending on whether you're classifying text, generating it, or translating it, this is the answer.
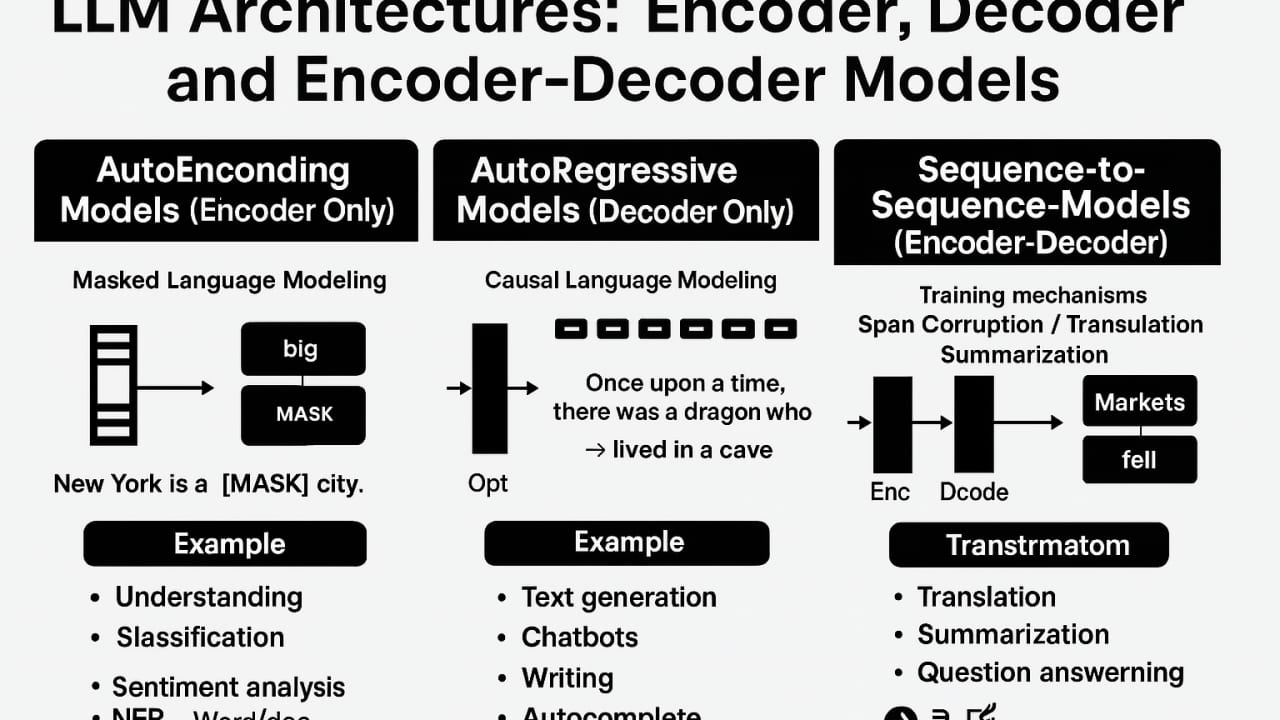
A helpful analogy: imagine reading a document in order to answer a question. An encoder reads the whole document at once — it can glance forward and backward freely, building a rich understanding of every word in context. A decoder reads the document and then continues writing — it sees only what came before and generates new words one at a time. An encoder-decoder does both: the encoder reads the source text deeply, then hands that understanding to a decoder that generates a new sequence from scratch.
Both halves are made of the same basic building block: stacked transformer blocks (attention + MLP). The difference is in one key detail — what the attention layer is allowed to see — and that single difference creates three completely different families of model, each dominant in its own niche.
Why it matters
Choosing the wrong architecture family for a task is one of the most common mistakes when selecting or fine-tuning a model. A decoder-only LLM prompted to produce a text embedding for semantic search will give mediocre results; an encoder-only model asked to generate a paragraph simply can't do it. Understanding the three families lets you pick the right tool and understand why vendors charge differently for different model types.
As a practical builder, this affects you in three concrete ways. First, embeddings and retrieval: vector databases, semantic search, and RAG pipelines almost always use encoder-based models because bidirectional context produces richer vector representations. Second, generation: every chat API you call — GPT, Claude, Gemini, Llama, Mistral — is a decoder-only model, and knowing that explains why they generate token by token and why long responses cost more. Third, structured transformation tasks (translation, summarization, code conversion): encoder-decoder models can outperform much larger decoder-only models on these tasks when fine-tuned, because the architecture naturally separates understanding the input from generating the output.
The trend in frontier AI has been strongly toward decoder-only models for almost everything, driven by the success of scaling and instruction tuning. But encoder-only and encoder-decoder models are far from dead — they dominate search infrastructure, multilingual NLP pipelines, and any setting where a small, fine-tuned model needs to beat a large prompted one on cost.
How it works
The key mechanism to understand is the attention mask — a matrix that tells each token which other tokens it is allowed to attend to. Change the mask, and you change the family.
Encoder-only: full visibility, no generation
In an encoder-only model, the attention mask is fully open: every token can attend to every other token in both directions. When processing the word bank in "the bank by the river," the model simultaneously sees both the (to its left) and river (to its right). This bidirectional view produces the richest possible contextual representation of each token. The model is pre-trained using masked language modeling (MLM) — randomly hiding about 15% of tokens and training the model to fill them in — which forces it to learn language from context in every direction.
BERT (Google, 2018) is the canonical encoder-only model. You plug a [CLS] token at the start of the input, run the forward pass, and take the final vector at that [CLS] position as a summary of the whole input — ideal for classification. For embeddings, sentence-transformers (SBERT) adapts BERT with a siamese network approach that produces dense vectors optimized for cosine similarity comparisons. The tradeoff is that bidirectional models cannot generate new text — there is no mechanism for producing the next token, because the mask sees the future.
Decoder-only: causal masking enables generation
A decoder-only model applies a causal mask (also called an auto-regressive mask): position i can only attend to positions 0 through i. No peeking at future tokens. At each step, the model sees everything to the left of the current position and predicts what comes next. The model is pre-trained using next-token prediction: given every prefix in the training corpus, predict the next token. This training objective scales beautifully — the same forward pass generates a training signal at every position in the sequence.
GPT-2 (OpenAI, 2019) demonstrated that this architecture scales surprisingly well. The GPT, Claude, Llama, Gemini, Mistral, Qwen, and DeepSeek families — every major generative model you interact with today is a decoder-only transformer, sometimes with modifications like grouped-query attention, SwiGLU activations, or rotary positional embeddings (RoPE), but the causal-masked architecture is unchanged. The decoder-only design won the scaling race because next-token prediction is the single most data-efficient, hardware-friendly training objective ever found.
- Token A sees: A, B, C, D
- Token B sees: A, B, C, D
- Token C sees: A, B, C, D
- Full context at every position
- Cannot produce a next token
- Token A sees: A
- Token B sees: A, B
- Token C sees: A, B, C
- Left-context only at each step
- Naturally generates token by token
Encoder-decoder: the original seq2seq design
The original 2017 transformer paper ("Attention Is All You Need") described an encoder-decoder model designed for machine translation. The encoder processes the full source sequence with bidirectional attention, producing a rich contextual representation of the input. The decoder then generates the output sequence auto-regressively — one token at a time, causally masked for its own past — but with an additional cross-attention layer at each decoder block that lets it attend directly to the encoder's output.
Cross-attention is how the decoder stays grounded in the source: at each generation step, it asks "which parts of the input are most relevant to what I'm writing right now?" and weights them accordingly. T5 (Google, 2020) applied this design to everything by framing every NLP task as text-to-text. BART (Meta, 2019) used a denoising pre-training objective on top of the same architecture and set records on abstractive summarization benchmarks.
Model families compared
| Architecture | Attention type | Pre-training task | Strengths | Well-known models |
|---|---|---|---|---|
| Encoder-only | Bidirectional | Masked language modeling | Classification, embeddings, NLU | BERT, RoBERTa, DeBERTa |
| Decoder-only | Causal (left-to-right) | Next-token prediction | Text generation, reasoning, chat | GPT, Claude, Llama, Mistral, Gemini |
| Encoder-decoder | Bidirectional (enc) + causal + cross (dec) | Seq2seq denoising / text-to-text | Translation, summarization, structured output | T5, BART, mT5 |
A few nuances worth knowing. First, decoder-only models can do classification too — you fine-tune them with a classification head or prompt them. They just tend to need more parameters to match an encoder-only model's accuracy on pure classification tasks. Second, encoder-only models are smaller and faster at inference for tasks they're suited to: a BERT-base classifier with 110M parameters often beats a 7B decoder-only model at a fraction of the cost for a binary text classification job. Third, encoder-decoder models are data-efficient: a moderately-sized T5 fine-tuned on a summarization dataset often beats a much larger prompted LLM, because the architecture can specialize the encoder and decoder independently.
Why decoder-only models dominate frontier AI
Given that encoder-decoder models seem more principled — a separate encoder for understanding, a separate decoder for generating — why did the entire frontier converge on decoder-only? Three reasons stand out.
- Training efficiency. A decoder-only model on a sequence of length N produces N training signals in one forward pass — every prefix predicts the next token. An encoder-only model produces signals only at the masked positions (~15% of tokens per pass). The decoder's training objective extracts more signal per compute dollar.
- Simplicity scales better. Encoder-decoder models have two sets of weights to balance and a cross-attention mechanism to tune. Decoder-only models have one homogeneous stack. When you're spending billions of dollars on compute, you want fewer engineering surfaces to break.
- Emergent capabilities with scale. Empirically, decoder-only models exhibit in-context learning, chain-of-thought reasoning, and instruction-following capabilities that emerge as scale increases — abilities that weren't anticipated and haven't been as clearly reproduced in encoder-decoder scaling. The scaling laws discovered by Kaplan et al. were formulated on decoder-only models, and the whole RLHF + instruction-tuning pipeline that created ChatGPT was developed against decoder-only architectures.
There is ongoing research into whether bidirectional encoders could compete if scaled similarly. A 2025 paper (NV-Embed, from NVIDIA) showed that a decoder-only LLM with bidirectional attention enabled at embedding time can achieve state-of-the-art retrieval performance — blurring the traditional boundary. But for now, the ecosystem's tooling, hardware optimization (especially KV-cache for inference), and accumulated training recipes all assume decoder-only. A model that defies that assumption faces enormous switching costs.
Going deeper
Bidirectional fine-tuning of decoder models. The hard separation between encoder and decoder is softening. Research like NV-Embed demonstrates that if you remove the causal mask at inference time (so the decoder attends to all positions bidirectionally), the same decoder-only model becomes a better embedding model than BERT for retrieval tasks. This is used in production embedding endpoints at several labs. The key insight is that the causal mask is a training choice, not an architectural constraint — the actual attention mechanism is identical in all three families.
Prefix LM — the middle path. There is a fourth, less common variant: the prefix language model. It uses bidirectional attention over the input (the "prefix") and causal attention over the generated output. This is used in models like PaLM and some T5 variants. It offers encoder-like understanding of the prompt combined with decoder-like generation, at the cost of slightly more complicated training.
The KV cache and decoder-only inference. One concrete consequence of the causal mask is that decoder-only inference benefits enormously from the KV cache — storing the key and value tensors computed for previous tokens so they don't have to be recomputed for each new token. This is why a long prompt reduces generation speed: the cache grows proportionally. Encoder-only models don't have this "generate incrementally" problem and typically run a single forward pass with no cache.
Mixture-of-Experts (MoE) on decoder-only. The decoder-only architecture has proven particularly amenable to the MoE extension — replacing each dense MLP layer with multiple "expert" sub-networks and a learned router that activates only a few per token. Llama 4 (2025) moved to MoE, following Mixtral and earlier models. MoE grows the total parameter count (and thus model capacity) while keeping per-token compute roughly constant. This is possible precisely because the decoder-only stack is a clean, uniform chain of blocks — easy to make each block conditional.
When to fine-tune an encoder-decoder instead of prompting a decoder-only LLM. On constrained sequence-to-sequence tasks (e.g., converting structured JSON to a summary sentence, translating between two narrow domains, generating SQL from natural language), a fine-tuned T5-base (250M parameters) often beats frontier-LLM prompting at one-twentieth the inference cost and with better consistency. The architectural fit — encoder absorbs the full input, decoder generates exactly what you specify — produces a tighter inductive bias than prompting a general-purpose model.
FAQ
What is the difference between BERT and GPT architecturally?
BERT is encoder-only: it uses bidirectional attention and can see every token in the input at once, which makes it excellent at understanding and classifying text. GPT is decoder-only: it uses a causal mask so each token only attends to previous tokens, which makes it excellent at generating text. Neither architecture is objectively better — they're optimized for different tasks.
Why are most LLMs decoder-only?
Decoder-only models produce a training signal at every token position in one forward pass (next-token prediction), making them extremely data- and compute-efficient to train at scale. They also benefit from a simpler, more uniform architecture that scales cleanly and pairs well with the KV cache at inference time. Empirically, capabilities like instruction-following and chain-of-thought reasoning emerged most clearly from scaled decoder-only models.
Can a decoder-only model produce text embeddings?
Yes, but it takes a trick. Standard causal-masked generation produces poor embeddings because each token's representation only sees left-side context. Production embedding APIs (like OpenAI's text-embedding-3 or NVIDIA's NV-Embed) either use special pooling strategies or temporarily disable the causal mask so the model attends bidirectionally — effectively running the decoder as an encoder for the embedding pass.
What does 'seq2seq' mean and how does it relate to encoder-decoder models?
Seq2seq (sequence-to-sequence) describes any task where the model takes one sequence as input and produces a different sequence as output — translation, summarization, and question answering are classic examples. Encoder-decoder (also called seq2seq) transformer models are purpose-built for this: the encoder reads the full input bidirectionally, and the decoder generates the output auto-regressively with cross-attention back to the encoder.
Is T5 better than GPT for summarization?
At similar model sizes, a fine-tuned T5 often outperforms a prompted GPT-class model on structured summarization benchmarks. BART achieved a 6 ROUGE point improvement on abstractive summarization using its seq2seq denoising objective. That said, very large decoder-only models with instruction tuning (the GPT and Claude families) can produce higher-quality summaries in zero-shot settings — the tradeoff is cost and latency versus fine-tuning effort.
What is cross-attention in an encoder-decoder model?
Cross-attention is an extra attention layer inside each decoder block. Instead of attending only to the decoder's own past tokens, it attends to the encoder's output representations. At each generation step, the decoder uses cross-attention to ask: which parts of the encoded input are most relevant to what I'm writing right now? This is how translation models stay faithful to the source sentence as they generate the target.