In plain English
Read the words "dog bites man" and then "man bites dog." Same three words, very different news story. The meaning lives almost entirely in the order. So here is a surprising fact about the transformer, the architecture behind every modern large language model: the core machinery that mixes words together — self-attention — is completely blind to order. On its own, it treats your sentence as an unordered bag of tokens. Shuffle the words and, mathematically, it would compute the same thing.
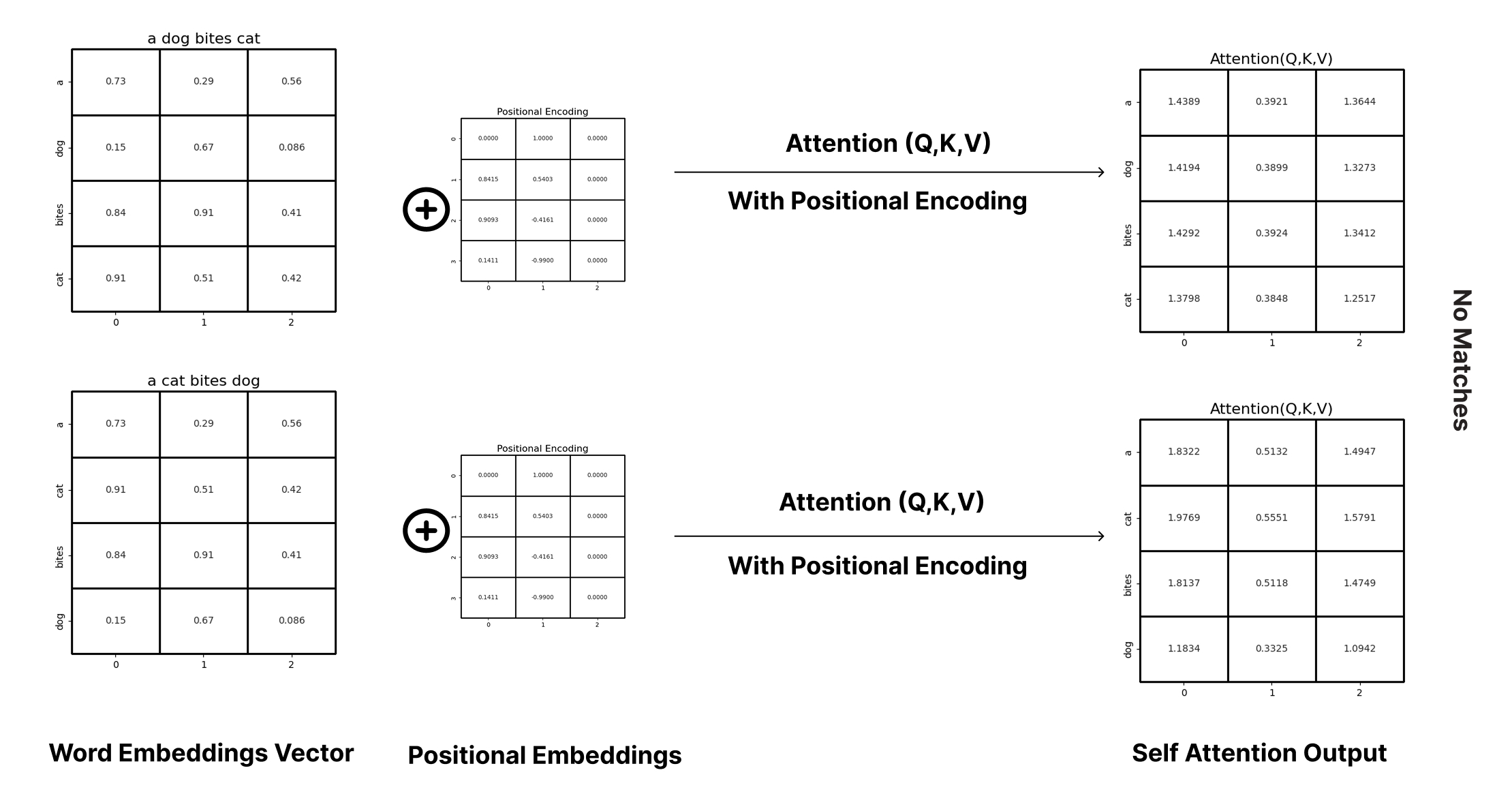
That can't be right for language, obviously. The fix is positional encoding: a small, deliberate signal added to each token that whispers where it sits — first, second, seventeenth. The model still does all its reasoning through attention, but now every token carries a tag that says "I am at position 5," so the network can finally tell "dog bites man" from "man bites dog."
Think of a deck of index cards, one word per card. Self-attention is a brilliant reader who studies the content of every card and notices how they relate — but the reader is handed the cards in a shuffled pile and was never told the original sequence. Positional encoding is like stamping a page number on each card before you hand them over. The words are unchanged; the reader simply now knows the running order.
Why it matters
If you've ever wondered how a transformer actually knows word order, this is the entire answer — and it's not optional plumbing. Remove positional encoding and a language model collapses into something that can't tell a question from its reverse. But the reason a builder should care goes well beyond "it makes order work."
- It's the reason attention can be parallel. Older models (RNNs) read words one at a time, so order came for free from the reading sequence — but that made them slow and impossible to parallelize. Transformers process all tokens at once, which is why they train fast on GPUs. Positional encoding is the price of that speed: since the model no longer reads left-to-right, you must hand it position separately.
- It quietly governs long context. How a model encodes position decides how gracefully it handles inputs longer than it ever saw in training. A 200k-token context window working well — or falling apart — often comes down to which positional scheme the model uses and how it was stretched.
- It explains a whole class of model behaviors. Why some models repeat themselves, lose track of early instructions, or degrade past a certain length frequently traces back to position handling, not the attention math itself.
So even though you rarely touch positional encoding directly when using an API, it shapes the limits you do feel: maximum context length, how well a model recalls something from page one when you're on page fifty, and whether a long document confuses it. Understanding it turns several mysterious model quirks into predictable consequences of one design choice.
How it works
Start with why attention is order-blind. Self-attention turns each token into three vectors — a query, a key, and a value — and decides how much token A should attend to token B purely from their query and key. Crucially, that calculation is a sum over all tokens, and a sum doesn't care about order: rearranging the terms gives the same total. So with nothing added, position 1 and position 50 are interchangeable. The model literally has no variable that means "first" versus "fiftieth."
Positional encoding injects that missing variable. The classic recipe from the original 2017 transformer paper is sinusoidal encoding: for each position you compute a fixed pattern of sine and cosine waves at many different frequencies, producing one vector per position. You then add that vector to the token's word embedding before attention runs. Now "dog at position 1" and "dog at position 3" enter attention as slightly different vectors — the meaning plus a position fingerprint.
Why sine waves, of all things?
It looks arbitrary, but the choice is clever. Each position gets a unique blend of fast and slow waves — like a binary odometer where some digits flip every step and others flip rarely. Two benefits fall out. First, every position has a distinct fingerprint. Second, the relative distance between two positions shows up as a consistent, learnable shift in those waves, so the model can pick up patterns like "the token three back" without memorizing every absolute slot. And because the pattern is a fixed formula, the model can produce an encoding for position 5,000 even if it only trained on sequences of length 512 — at least in principle.
Absolute vs. relative position
Sinusoidal and learned embeddings are absolute: they tag each token with its slot number from the start. But for language, what usually matters is relative position — "how far is this word from that one," not "this word is the 41st." That insight pushed the field toward methods that bake relative distance directly into attention. The most important of these today is RoPE.
RoPE: rotating the vectors
RoPE (Rotary Position Embedding) is the scheme used in most current open models. Instead of adding a position vector, it rotates each token's query and key vectors by an angle proportional to its position — a little rotation for position 1, a bigger one for position 50. The elegant payoff: when attention compares a query at position i with a key at position j, the rotations partially cancel and what remains depends on the difference i − j. In other words, RoPE makes attention naturally sensitive to relative distance, which is exactly what language wants, while still encoding absolute position under the hood.
- Fixed sine/cosine formula
- Absolute position, added to embedding
- No parameters to learn
- Extends to unseen lengths in theory
- A trainable vector per position
- Absolute position, added to embedding
- Often used in BERT-style models
- Hard limit at the trained max length
- Rotates query/key vectors
- Encodes relative distance i − j
- Standard in most modern LLMs
- Stretchable to longer context
A tiny worked example
The whole idea is just "add a position vector to each word vector before attention." Here it is in a few lines of Python with the classic sinusoidal formula — toy-sized, but it's exactly what the real thing does.
import numpy as np
def positional_encoding(seq_len, dim):
pe = np.zeros((seq_len, dim))
pos = np.arange(seq_len)[:, None] # position index 0,1,2,...
i = np.arange(0, dim, 2) # even dimension indices
freq = 1.0 / (10000 ** (i / dim)) # many wavelengths
pe[:, 0::2] = np.sin(pos * freq) # even dims -> sine
pe[:, 1::2] = np.cos(pos * freq) # odd dims -> cosine
return pe # shape (seq_len, dim)
# token embeddings come from the model; here, random stand-ins
word_emb = np.random.randn(4, 8) # 4 tokens, dim 8
pos_emb = positional_encoding(4, 8)
# THE KEY LINE: position is simply ADDED in, before attention
model_input = word_emb + pos_emb
print(pos_emb[0]) # position 0: a fixed fingerprint
print(pos_emb[1]) # position 1: a DIFFERENT fixed fingerprintTwo takeaways from those last two prints. Position 0 and position 1 produce genuinely different vectors — that difference is what lets attention tell them apart. And the values come from a formula, not training, so you can ask for position 9,999 and still get a valid vector. RoPE swaps that word_emb + pos_emb line for a rotation applied inside attention, but the spirit is identical: make each token's representation depend on where it sits.
Common misunderstandings
Positional encoding is small but subtle, and a few wrong mental models trip people up.
- "The model reads left to right, so it knows order." It doesn't read sequentially at all — every token is processed in parallel. Order exists only because positional encoding put it there. Take it away and direction vanishes.
- "Position is a separate input channel." No — for the classic scheme it's literally added into the same vector as meaning. One vector carries both "what this word is" and "where it is," and attention untangles them.
- "A bigger context window just means more memory." Length limits are partly a positional problem. The model has to represent positions it may never have trained on, and pushing past that range is where extension tricks (and failures) live.
- "RoPE replaced position entirely with relative distance." RoPE still encodes absolute position by rotating each token by its own angle — it's just built so that the comparison inside attention ends up depending on the relative gap. Absolute and relative aren't opposites here.
Position and long context
This is where positional encoding stops being trivia and starts driving real product limits. A model trained on, say, 4,000-token sequences has only ever seen positions 0 to 3,999. Ask it about position 8,000 and you're in territory it never practiced. How a model copes here is largely a story about its position scheme.
| Challenge | What goes wrong | Common mitigation |
|---|---|---|
| Lengths beyond training | Unseen positions confuse the model | Position interpolation: squeeze new positions into the trained range |
| Recall across long context | Facts in the middle get "lost" | Better position schemes + targeted long-context training |
| Extending a released model | Hard absolute limits can't stretch | RoPE scaling (e.g. frequency adjustment) to reach longer windows |
RoPE is popular partly because it stretches. Researchers found you can adjust its rotation frequencies — informally, "slow the rotations down" — to map a longer sequence into the range the model already understands, often with only a little extra fine-tuning. That trick is a big reason context windows jumped from a few thousand tokens to hundreds of thousands. Learned absolute embeddings, by contrast, have a hard wall: there's simply no learned vector for position 5,001 if you only trained up to 5,000.
The practical lesson: when a model's context window grows, it's rarely just "more RAM." Someone re-engineered how position is represented and stretched, then retrained or fine-tuned so the model stays coherent that far out. Positional encoding is the lever they're pulling.
Going deeper
Once the basics click, a few threads are worth following — both for intuition and for reading modern model papers without getting lost.
The relative-position family. Beyond RoPE there are other relative schemes. ALiBi skips position vectors entirely and instead adds a small, distance-based penalty straight into the attention scores: the farther apart two tokens are, the more their connection is discounted. It's simple and extrapolates to longer lengths surprisingly well. T5-style relative bias learns a bias term per relative distance bucket. The common thread across all of them: encode how far apart tokens are rather than which absolute slot they occupy, because that's what generalizes.
Position interpolation and extension. When you want a released model to handle longer inputs than it trained on, you can interpolate positions — compressing a long sequence so its positions fall inside the trained range — usually paired with a short fine-tune. With RoPE this often takes the form of scaling its frequencies. These tricks are how a community fine-tune turns a 4k-context base model into a 32k or 128k one without retraining from scratch.
The "lost in the middle" effect. Even with a working long-context scheme, models tend to recall information at the start and end of a long prompt better than the middle. Part of this is positional: the model has seen far fewer training examples with critical content at very deep positions. It's a reminder that a long context window is not a guarantee of even attention across it — where you place key instructions still matters.
Where to go next. Positional encoding sits inside the attention mechanism, so that's the natural companion read — attention covers how tokens match, while this covers how they're ordered. From there, the broader transformer architecture shows where position fits in the full stack, and encoder vs. decoder models shows how different model families use it. The durable takeaway: attention gives a transformer its power, but positional encoding is the small, almost-invisible signal that makes that power apply to language instead of an unordered bag of words.
FAQ
Why do transformers need positional encoding?
Because self-attention is order-blind: it computes a sum over all tokens, and a sum is unchanged if you shuffle the order. Without an extra signal, the model literally can't tell "dog bites man" from "man bites dog." Positional encoding adds a per-token "where am I" tag so attention can finally use word order.
What is the difference between positional encoding and positional embeddings?
They mean almost the same thing. "Positional encoding" is the general idea of injecting position; "positional embeddings" usually refers specifically to learned position vectors (trainable, like word embeddings) as opposed to the fixed sinusoidal formula. In casual use the terms are interchangeable.
What is RoPE positional encoding?
RoPE (Rotary Position Embedding) is the scheme in most modern LLMs. Instead of adding a position vector, it rotates each token's query and key vectors by an angle based on its position. The math works out so that attention between two tokens depends on their relative distance, which is what language cares about, and it stretches to longer contexts more gracefully than absolute embeddings.
How do sinusoidal positional encodings work?
For each position you compute a vector of sine and cosine values at many frequencies — like an odometer where some digits flip fast and others slow. Each position gets a unique fingerprint, and because it's a fixed formula (not learned), you can generate an encoding for any position, even ones longer than the training data. That vector is added to the word embedding before attention.
Does positional encoding affect context length?
Yes, heavily. How a model encodes position decides how well it handles inputs longer than it trained on. Schemes like RoPE can be "scaled" to reach much longer windows, while learned absolute embeddings hit a hard wall. Many long-context behaviors — and failures — trace back to the positional scheme.
Is positional encoding added to or multiplied with the embedding?
For the classic sinusoidal and learned-embedding methods, the position vector is added to the word embedding before attention. RoPE is different: it rotates the query and key vectors inside the attention step rather than adding anything to the input embedding.