In plain English
Every time you send a prompt to a language model, the model has to read that prompt before it writes a single word of the answer. Reading isn't free: the model runs every token of your prompt through dozens of layers of math to build an internal representation it can reason over. For a short question that's quick. For a 4,000-token system prompt stuffed with instructions and examples, it's a real chunk of work — and the model redoes it from scratch on the next request, even if that next request starts with the exact same 4,000 tokens.
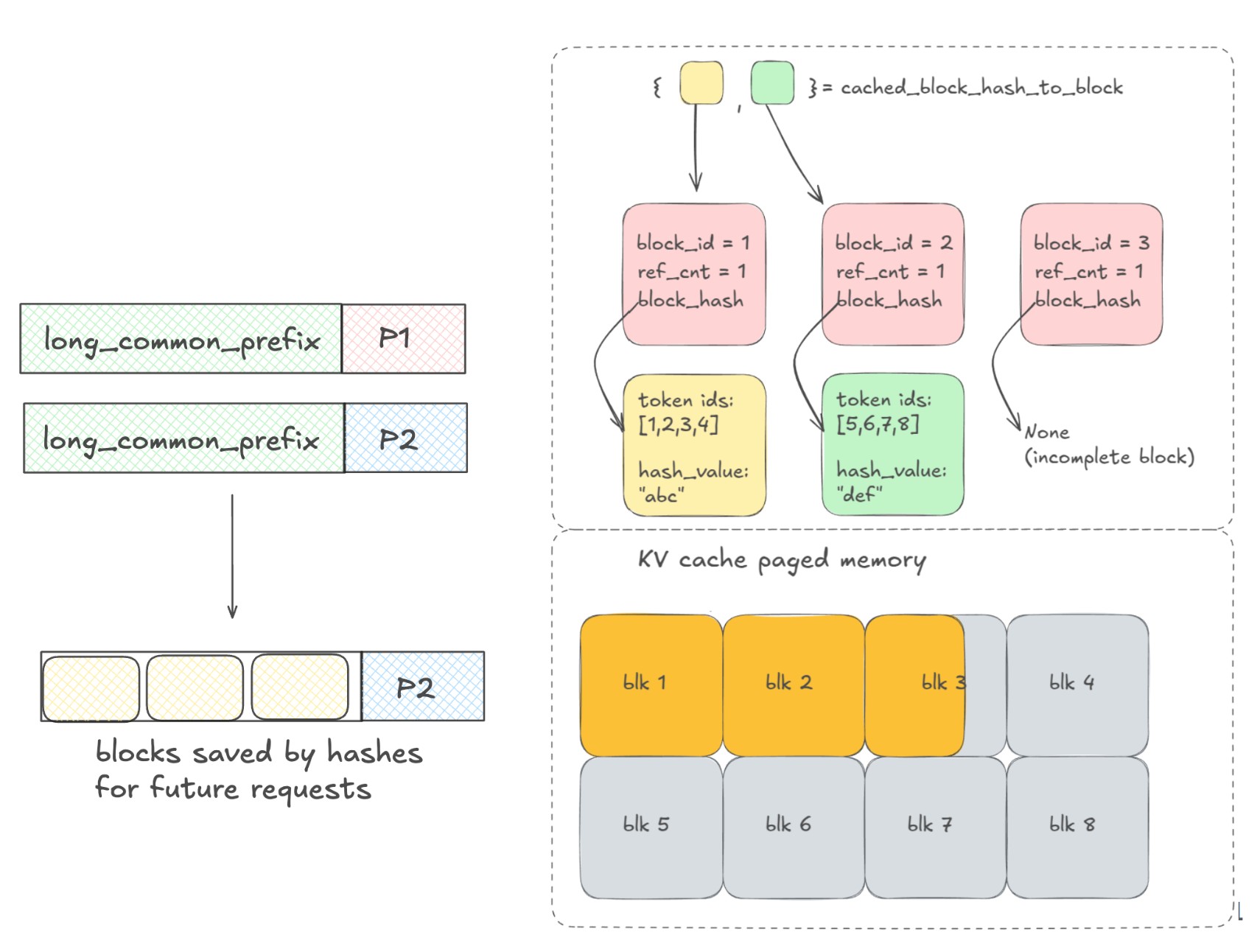
Prefix caching is the trick of not redoing that work. The serving engine remembers the math it already computed for a shared beginning of the prompt — the prefix — and reuses it for any later request that starts the same way. Only the new, different part of the prompt has to be processed fresh.
Picture a barista who memorizes the regulars. The first person orders "oat-milk latte, extra shot, no foam" and the barista carefully sets up the machine for it. When the next ten customers all want the same base — "oat-milk latte, extra shot" — and only differ on the last word ("…with caramel", "…with vanilla"), the barista doesn't tear down and rebuild the whole setup each time. The shared base is already prepared; only the final tweak changes. Prefix caching does this for prompts: the shared opening is prepared once, the varying tail is all that's new.
Why it matters
Most real LLM applications send the same long opening on almost every request. A chatbot repeats a fixed system prompt thousands of times a day. A few-shot classifier prepends the same five worked examples before each new input. A "chat with this document" feature pastes the whole document in front of every follow-up question. In all three cases, a big slab of identical tokens sits at the front of the prompt and only a short tail at the end actually changes.
Without prefix caching, the engine pays the full cost of reading that slab on every single call. That cost shows up in two places a builder cares about:
- Time to first token (TTFT). Before the model can emit word one, it must process the entire prompt — the prefill stage. A long prefix makes the user wait. Reusing the cached prefix means prefill skips most of the work, so the first token arrives much sooner. (See time to first token for why this metric drives perceived speed.)
- GPU compute and throughput. Prefill is compute-heavy. Skipping it for a shared prefix frees the GPU to serve more requests at once, which lowers cost per request even when the sticker price per token doesn't change.
- Consistency under load. When many users hit the same system prompt, a server-wide prefix cache lets them all share one computed copy, so latency stays stable instead of spiking as traffic grows.
The payoff scales with the shape of your prompt. A long shared prefix plus a short varying suffix is the ideal case — most of the prompt is reusable. A prompt that changes near the start (say, the user's question comes before the document) gets almost no benefit, because the cache can only reuse tokens up to the first point of difference.
How it works
To understand prefix caching you need one fact about how transformers read text: attention is causal. Each token can only attend to tokens before it, never after. That means the model's internal representation of token 50 depends only on tokens 1–50 — it is completely unaffected by whatever comes at token 51 onward. So if two prompts share the first 50 tokens, the computed key/value tensors for those 50 tokens are identical, regardless of how the prompts differ afterward. That identity is exactly what makes the cache reusable.
The matching rule: a shared prefix, up to the first difference
The engine hashes the prompt token-by-token (usually in fixed-size blocks) and looks for the longest run of leading tokens it has already seen and cached. Everything up to the first divergent token can be reused; everything from that point on must be computed fresh. This is why the shared part must be a true prefix — at the very start of the prompt. A shared chunk buried in the middle does not qualify, because the tokens before it would have to match first.
Where it lives: the serving engine
Prefix caching is implemented down in the inference engine — the layer that actually runs the model on the GPU — not in your application code. In open-source serving stacks like vLLM, it is called automatic prefix caching (APC): "automatic" because you don't mark which prefix to cache; the engine detects shared prefixes across requests on its own and reuses whatever KV blocks it can. vLLM does this with a technique called PagedAttention that stores the KV cache in fixed-size blocks (like memory pages), so identical blocks can be shared between requests instead of copied.
Because the cache lives in finite GPU memory, it's a cache in the full sense: entries are evicted when space runs low, typically least-recently-used first. A prefix that hasn't been hit in a while can be dropped, and the next request that needs it pays full price again. Keeping hot prefixes resident is part of tuning a serving stack.
Prefix caching vs prompt caching vs semantic caching
These three names get mixed up constantly because they all "cache" something to make LLM calls faster or cheaper. They operate at completely different layers, though, and reuse completely different things.
| Prefix caching (engine) | Prompt caching (provider feature) | Semantic caching | |
|---|---|---|---|
| What's reused | KV tensors for shared prefix tokens | KV tensors for a marked prompt section | The whole final answer text |
| Match condition | Exact identical leading tokens | Exact match on the cached span | Similar meaning of the new query |
| Who controls it | The serving engine, automatically | You, via API cache markers | Your app's cache layer |
| Main win | Lower TTFT, more throughput | Lower TTFT and discounted input tokens | Skips the model call entirely |
| Skips the model? | No — still generates | No — still generates | Yes — returns a stored answer |
The key distinction: *prefix caching and provider prompt caching both reuse the model's computation* (the KV cache) but still run generation.** They make the same answer arrive faster. Semantic caching is different in kind — it stores and returns a previously generated answer when a new question means roughly the same thing, skipping the model call altogether. For the deeper provider-feature comparison, see prompt caching vs semantic caching.
A worked example: structuring the prompt for cache hits
Whether prefix caching fires often comes down to prompt order. The rule to internalize: put everything stable at the front, everything that varies at the back. Below, the second version is identical from the start across every request, so the engine can reuse the long prefix; the first version changes near the top and defeats the cache.
User question: How do I reset my password?
[2,000-token system prompt + policy document follows here...][2,000-token system prompt + policy document — identical every call]
User question: How do I reset my password?In the cache-hostile layout, the question is the first thing in the prompt, so the very first tokens differ on every request and nothing downstream can be reused. In the cache-friendly layout, the first 2,000 tokens are byte-for-byte identical across all users, so the engine reuses that entire prefix and only processes the short question at the end.
A second example: a few-shot classifier. Keep the instructions and all five example pairs at the top, fixed and in a stable order, and append only the new item to classify. Every request then shares the long instruction-plus-examples prefix, and prefill collapses to just the final input.
When it helps, and when it doesn't
Prefix caching is close to free upside when your traffic has the right shape, and close to useless when it doesn't. Knowing which world you're in saves you from expecting a speedup that never comes.
- Long fixed system prompt
- Few-shot examples reused every call
- Same document, many follow-up questions
- Multi-turn chat (history is a growing prefix)
- Many users sharing one system prompt
- Every prompt is unique from token one
- Variable content placed before the stable part
- Very short prompts (prefill was cheap anyway)
- Hot prefix evicted before the next hit
- Generation is the bottleneck, not prefill
Two nuances worth flagging. First, multi-turn chat is a natural fit: each new turn appends to the conversation, so turn N's prompt is turn N-1's prompt plus a bit more — the whole prior conversation is a reusable prefix. Second, prefix caching only attacks the prefill side of latency. If your slowness comes from generating a long answer token by token (the decode side), caching the prefix won't help that part — see reduce LLM latency for the full latency picture.
Going deeper
Once the basics click, a few sharper edges are worth knowing — they explain surprising cache misses and the limits of the technique.
Block granularity and partial hits. Engines cache in fixed-size blocks (vLLM defaults to 16 tokens per block). The cache can only reuse whole blocks, so a prefix that matches for 30 tokens reuses one full block and recomputes the rest of the second block. This usually doesn't matter, but it means the effective shared prefix is rounded down to a block boundary.
Exact match, including invisible bytes. Reuse requires the leading tokens to be identical. A different whitespace character, a reordered JSON field, a changed model or sampling parameter that alters tokenization, or even a different system-prompt template version can silently break the match. "It looks the same" is not enough; it must tokenize the same.
Eviction and warm-up. Because the cache shares finite GPU memory with the live KV cache for in-flight requests, prefixes get evicted under pressure. After a deploy, a scale-up, or a quiet period, the cache is cold and the first requests for a prefix pay full prefill cost before it warms up. Latency graphs often show this as a spike right after a restart.
Correctness is preserved. A reasonable worry: does reusing cached state change the answer? It does not. Because of causal attention, the KV for a prefix token is mathematically independent of anything after it, so a reused prefix produces exactly the same numbers as recomputing it would. Prefix caching is a pure performance optimization, not an approximation — unlike semantic caching, which can return a near match.
Where to go next. To see what's actually being cached, read the KV cache. To weigh engine-level reuse against the billable provider feature and answer-level reuse, read prompt caching vs semantic caching. And for the broader cost picture these optimizations feed into, see cut LLM token costs and the wider production LLMOps category.
FAQ
What is prefix caching in LLMs?
Prefix caching is a serving-engine optimization that reuses the model's already-computed KV cache for a shared beginning (prefix) of a prompt. When a new request starts with the same tokens as a previous one, the engine skips re-processing that prefix and only computes the new, differing tail — making the first token arrive faster and freeing GPU compute.
What is the difference between prefix caching and prompt caching?
They are closely related: provider "prompt caching" is essentially prefix caching exposed as an API feature, where you mark the stable section and often get a token discount on cache hits. Engine-level prefix caching (like vLLM's automatic prefix caching) detects shared prefixes on its own and mainly buys you lower latency and higher throughput rather than a price discount. Both reuse the KV cache and still run generation.
Does prefix caching reduce the cost per token?
Not by itself, at the engine level — it reduces prefill compute and latency, which lets a server handle more requests and can lower your effective cost per request. Provider prompt-caching features are different: those often do discount the cached input tokens directly on a cache hit. So the cost win depends on whether you mean engine reuse or a billed provider feature.
What is automatic prefix caching in vLLM?
Automatic prefix caching (APC) is vLLM's built-in feature that detects identical prompt prefixes across requests and reuses their cached KV blocks automatically — you don't mark anything. It builds on PagedAttention, which stores the KV cache in fixed-size blocks so matching blocks can be shared between requests instead of recomputed.
Why does the shared content have to be at the start of the prompt?
Because transformer attention is causal: each token's representation depends only on the tokens before it. The cache can reuse leading tokens only up to the first point where two prompts differ. A shared chunk in the middle doesn't qualify, since the tokens before it would have to match first — so put stable content at the front and variable content at the end.
Can prefix caching change the model's output?
No. Because a prefix token's KV is mathematically independent of any tokens that come after it, reusing the cached prefix produces exactly the same numbers as recomputing it. It is a pure performance optimization, not an approximation — unlike semantic caching, which may return a near-match answer.