In plain English
When you run an LLM application in production, you usually log everything: the user's prompt, the model's response, the tokens, the latency, the tool calls. That trace is gold for debugging — until you remember what is inside those prompts. People paste their email, their phone number, a credit card, a medical detail, a customer's home address. The moment you log the raw text, a copy of that personal data lands in your observability platform, your log files, and probably a third-party vendor's database.
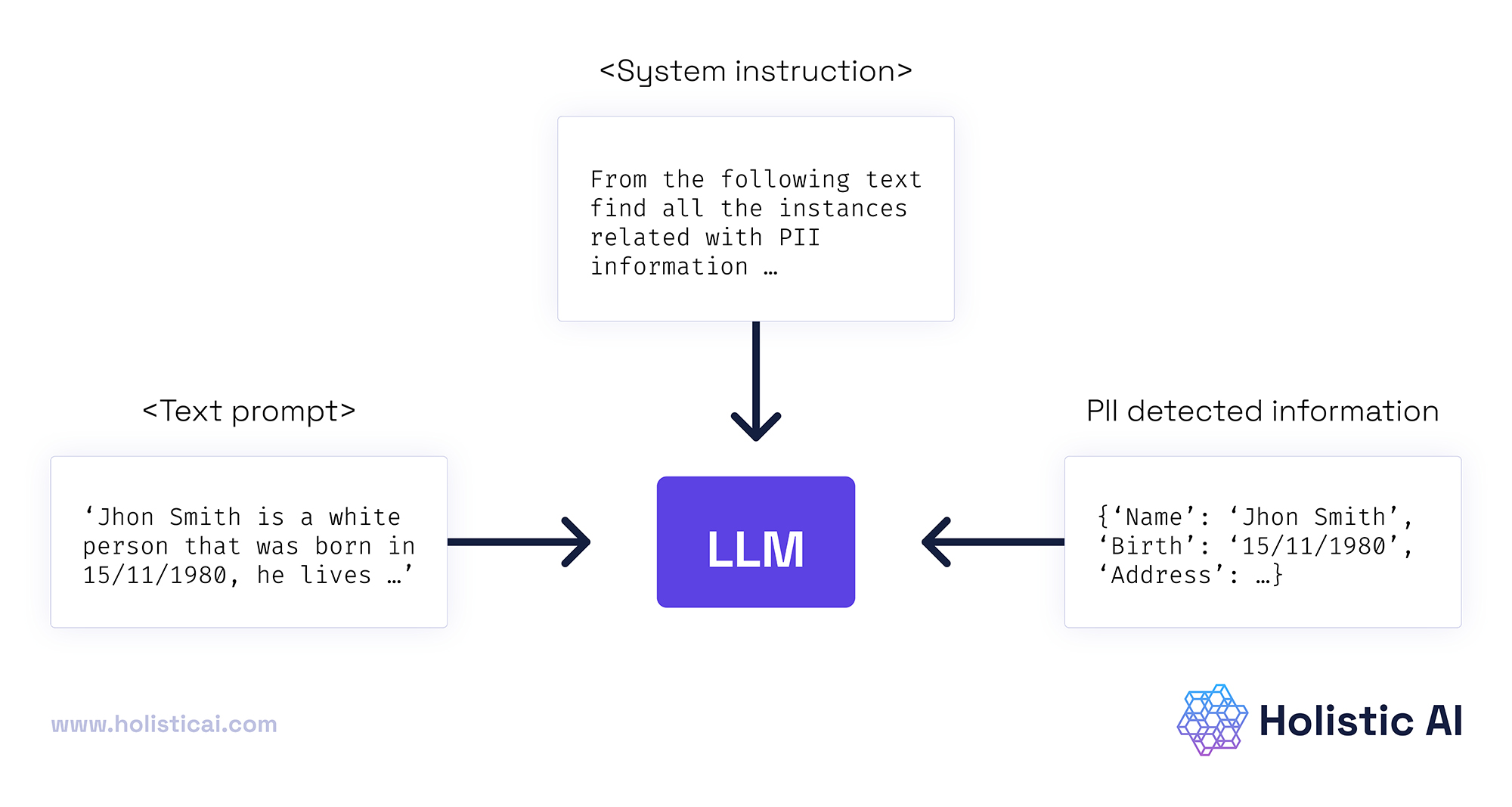
PII redaction is the step that strips personal data out of that text before it gets written anywhere durable. PII stands for personally identifiable information — anything that can point back to a real person. Redaction finds those spans and replaces them with a placeholder, so the log keeps its shape ("a question containing an email") without keeping the secret (jane@acme.com).
Think of it like a mailroom that opens every envelope, runs a black marker over the sensitive lines, and only then files the letter. The filing cabinet still tells you a letter arrived, who roughly it was about, and what it asked — but the name, the account number, and the diagnosis are blacked out. Anyone who later opens that drawer (an engineer, an auditor, an attacker who breached your logging vendor) sees the redacted copy, never the original.
Why it matters
Full-prompt logging feels harmless in development and becomes a serious liability in production. Three forces collide.
- Compliance. Regulations like GDPR, HIPAA, and CCPA treat personal data as something you must minimise, justify, and be able to delete. A trace store full of raw prompts means every user's right-to-be-forgotten request now has to reach into your observability stack too — and an auditor will ask where that data flows.
- Blast radius. Logs are copied widely: to your tracing vendor, to dashboards, to data warehouses, into alerts that get emailed to on-call engineers. Each copy is a new place a breach can leak from. Redacting at the source shrinks how far the sensitive data can travel from one trace into dozens of systems.
- Third parties. The instant you send a raw prompt to a hosted observability or analytics tool, that personal data has left your trust boundary. Your data-processing agreement now has to cover it, and you have inherited their breach risk.
Who should care? Anyone shipping an LLM feature that touches real users — support bots, health or finance assistants, internal tools that handle employee data, anything where a prompt can contain a name, an ID, or a free-text complaint. If your product talks to humans, assume PII is already flowing through your prompts, because users will paste it whether you ask them to or not.
How it works
Redaction is a small transform with one critical property: it must run before the data reaches anything you don't fully control. That "anything" usually means your trace exporter — the component that ships spans off to an observability backend. If you redact after the exporter has already sent the span, you have lost. So the redaction step sits inline, between your application producing the text and the exporter shipping it.
Inside the Detect step you are answering one question: which characters in this string are personal data? There are two broad families of detectors, and serious systems combine them.
Rule-based detection (regex)
Some PII has a fixed shape. Emails, phone numbers, credit-card numbers, IP addresses, and many national ID formats can be matched with regular expressions or checksums (a credit card passes the Luhn check, for example). This is fast, cheap, deterministic, and runs locally with zero extra API calls. The weakness: it only catches what you wrote a pattern for, and it misses anything free-form.
Model-based detection (NER and LLMs)
Names, addresses, employers, and medical conditions have no fixed shape — "Maria from the Lisbon office" is PII but matches no regex. For these you need NER (named-entity recognition): a model trained to tag spans like PERSON, LOCATION, or ORG. A small local NER model is the common choice; using a full LLM as the detector is more flexible but adds cost and latency to every request. Model detectors catch the messy cases regex can't, at the price of being slower and occasionally wrong.
Once you know where the PII is, the Redact step decides what to put in its place. There are two strategies with very different properties.
Irreversible masking replaces the span with a generic label like [EMAIL] or a row of asterisks. The original is simply destroyed in the logged copy — the safest option, and you can never recover it. Reversible tokenization replaces the span with a unique placeholder token and stores the real value in a separate, tightly-guarded vault keyed by that token. Your logs stay clean, but an authorised process can swap the token back to the real value when it genuinely needs to — useful when the same redacted email must stay consistent across a whole trace so you can still follow a single user's session.
A worked example in code
Here is the whole idea as a tiny redactor that runs before anything is logged. It mixes a couple of regex rules with a placeholder for a NER pass, then masks each span. The point is the shape: detect, replace, and only then hand the clean text to your logger or trace span.
import re
# 1) Fast, deterministic rules for fixed-shape PII.
PATTERNS = {
"EMAIL": re.compile(r"[\w.+-]+@[\w-]+\.[\w.-]+"),
"PHONE": re.compile(r"\+?\d[\d\s().-]{7,}\d"),
"CARD": re.compile(r"\b(?:\d[ -]?){13,16}\b"),
}
def detect_ner(text):
# Stand-in for a NER model that returns (start, end, label)
# spans for free-form PII like names and addresses.
return run_ner_model(text) # -> list[(int, int, str)]
def redact(text):
spans = []
for label, pat in PATTERNS.items():
for m in pat.finditer(text):
spans.append((m.start(), m.end(), label))
spans += detect_ner(text)
# Replace right-to-left so earlier offsets stay valid.
for start, end, label in sorted(spans, reverse=True):
text = text[:start] + f"[{label}]" + text[end:]
return text
def log_interaction(prompt, response):
# CRITICAL: redact BEFORE the value leaves this function.
tracer.log({
"prompt": redact(prompt),
"response": redact(response),
"tokens": count_tokens(prompt, response),
})Given the prompt My email is jane@acme.com and my card is 4111 1111 1111 1111, the logged span becomes My email is [EMAIL] and my card is [CARD]. The trace still shows that a user asked about their card and email — enough to debug the flow — while the actual values never touch the logging backend.
Masking vs tokenization: which to choose
The reversible-vs-irreversible decision is the one teams agonise over, because it trades safety against usefulness. This table lays out the tradeoff.
| Property | Irreversible masking | Reversible tokenization |
|---|---|---|
| Stored output | [EMAIL] / **** | <EMAIL_7f3a> + vault entry |
| Can recover original? | Never | Yes, via the vault |
| Breach of logs alone | No PII exposed | No PII exposed (vault is separate) |
| Extra system to secure | None | A vault — now a new high-value target |
| Keeps same value consistent | No (all emails look alike) | Yes (same input → same token) |
| Best for | Most debugging traces | Flows that must re-link or re-process later |
A useful default: mask irreversibly unless you have a concrete reason to recover the value. Every reversible vault is a new place that does hold the real PII, which partly defeats the purpose. Reach for tokenization only when you genuinely need consistency across a trace (so the same redacted user is recognisable) or a downstream job must later operate on the real value — and then guard that vault harder than the system it serves.
The debugging tradeoff and false negatives
Redaction is not free — it costs you observability. The whole reason you log prompts is to reproduce bugs, and a heavily redacted trace can hide the exact input that broke. Two honest tensions are worth naming.
Less to debug with
If the bug is in how your app handles a specific email format, and you redacted the email, the trace no longer shows you what went wrong. The common compromise is to log metadata only for sensitive flows: keep token counts, latency, which model was called, the redaction labels ("a prompt with 1 EMAIL and 1 PERSON"), and structural facts — but not the raw text. You can still spot patterns and reproduce most issues from a sanitised input, and reserve full capture for a tiny, access-controlled debug path with consent.
False negatives are the real danger
A detector has two ways to be wrong. A false positive redacts something harmless — annoying, but safe. A false negative misses real PII and lets it through to the logs — that is the failure that actually hurts you. Regex misses anything unusual; NER misses names it wasn't trained on, typos, and PII in other languages. Because a single miss writes real personal data to durable storage, you should bias the system toward over-redaction and treat the recall of your detector as a security metric, not a nice-to-have.
Going deeper
The detect-mask-log loop above is the foundation. Production systems layer on a few more concerns once the basics are in place.
Latency budget. A redaction step runs on every request, in the hot path, before you can ship a trace. Regex is microseconds; a NER model is milliseconds; an LLM-based detector can add hundreds of milliseconds and a per-call cost. The usual design is a cheap regex pass for the obvious formats plus a small local NER model, reserving an LLM detector for offline re-scanning of stored traces rather than the live path.
Redaction as a guardrail, not a silo. PII redaction is one member of a broader family of LLM guardrails that sit on the input and output edges of your system — alongside output validation, content moderation, and failure handling. A common architecture centralises all of these in an LLM gateway, so redaction happens in one place every request flows through, instead of being re-implemented per service.
Consistency and re-identification. Even fully masked logs can leak identity by accident: if a trace keeps a rare ZIP code, an unusual job title, and a birth date, those three together can re-identify a person even with the name removed. Mature redaction thinks about quasi-identifiers, not just obvious fields, and sometimes generalises ("a city in Portugal") rather than passing values through.
Evaluation. You cannot trust a redactor you haven't measured. Build a labelled test set of prompts with known PII spans and track recall (what fraction of real PII you catch) over time, especially after you change models or add a language. Treat a drop in recall the way you'd treat a security regression.
The durable lesson: redaction is a data-minimisation discipline, not a one-off feature. Decide what you truly need to log, redact everything else before it leaves your process, bias toward over-redaction because a single false negative is the costly one, and keep your detector honest with real evaluation. Done well, you keep almost all of your debugging power and almost none of the liability.
FAQ
Where in the pipeline should I redact PII for LLM logs?
Redact inline, after your app produces the prompt and response but before the trace exporter or logger ships the data anywhere durable. If redaction runs after the exporter has already sent the span, the raw PII has already left your trust boundary. Put the redact step directly in front of whatever writes to your observability backend.
What is the difference between masking and tokenization for PII?
Masking replaces the detected value with a generic label like [EMAIL] and destroys the original in the stored copy — irreversible and safest. Tokenization replaces it with a unique placeholder and keeps the real value in a separate vault, so it can be recovered later. Use masking by default; use tokenization only when you need to recover or re-link the value.
Will redacting prompts make it harder to debug my LLM app?
Yes, somewhat — you lose the exact input text. The standard compromise is to log metadata only for sensitive flows (token counts, latency, model, redaction labels) and reserve full capture for a small, access-controlled, consented debug path. You keep most of your reproducibility without keeping the raw PII.
Is regex enough to detect PII, or do I need a model?
Regex alone is not enough. It catches fixed-shape PII like emails, phone numbers, and card numbers cheaply, but misses free-form data like names, addresses, and employers. Combine regex with a NER (named-entity recognition) model, and bias toward over-redaction because a missed span (a false negative) writes real PII to your logs.
Do I need to redact the model's response too, or just the prompt?
Both. Models frequently repeat a user's email, name, or account number back in their answer, so logging the response verbatim re-introduces the PII you removed from the prompt. Redact the prompt, the response, tool-call arguments, and any retrieved context that feeds the model.
Isn't encrypting my logs enough instead of redacting?
No. Encryption protects data in transit and at rest, but the plaintext still exists and can be decrypted, and it does nothing for data-minimisation obligations. Redaction removes the sensitive span from the stored copy entirely, so even a full leak of your logs (or your logging vendor's) never exposes it.