In plain English
User feedback is any signal — deliberate or behavioral — that tells you whether an LLM response was helpful. The most visible form is the thumbs-up / thumbs-down pair you see in ChatGPT, Claude, and virtually every AI chat product built since 2023. But those buttons capture, at most, 1–3% of interactions: most people who are satisfied close the tab, and many people who are dissatisfied also just close the tab.
Think of a restaurant. The owner knows a dish is bad if a diner complains to the waiter — that's explicit feedback. But most unhappy diners stay silent and never return. The owner can also watch the room: untouched plates going back to the kitchen, guests spending twice as long chewing, orders for the same dish that keep getting sent back. Those are implicit signals, just as real as the complaint — often more honest, and collected at vastly larger scale.
In an LLM app, implicit signals are behavioral events you can log passively: did the user copy the response? Did they immediately rephrase the prompt (a retry)? Did they edit the generated text before using it? Did they abandon the session after one turn? Each of those events tells you something about quality without the user ever clicking a rating button.
Why it matters
LLMs are stochastic and evolve over time — a prompt that worked well last month may silently degrade after a model update, a context window change, or a retrieval tweak. Unlike deterministic software bugs that throw stack traces, quality regressions in LLM apps are invisible to conventional monitoring. A response can be HTTP 200, well-formed JSON, and completely wrong. User feedback is the primary signal that something slipped — before you see it in churn or support tickets.
- Evals need ground truth. The most valuable eval datasets are built from real production traces that users flagged as bad. A thumbs-down on a specific response is a labeled example you didn't have to write by hand.
- Prompt tuning without feedback is guesswork. If you can't measure whether your latest system-prompt tweak made things better or worse for users, you're flying blind. Feedback closes that loop.
- Model routing and A/B testing depend on it. Deciding which model variant to serve to which request requires a quality signal. Feedback — especially aggregated implicit signals — is how you measure winner vs. loser.
- Fine-tuning requires preference pairs. Techniques like DPO (Direct Preference Optimization) need chosen/rejected response pairs. Explicit user ratings give you exactly that structure — a thumbs-up response is your chosen, a thumbs-down your rejected.
- It detects drift before metrics do. Aggregate implicit-signal ratios (copy rate, retry rate) often move before CSAT or user retention metrics, giving you an earlier warning of model or prompt drift.
How it works
A production feedback pipeline has three moving parts: collection (capturing the signal at the right moment), attachment (linking the signal to the specific LLM trace that generated the response), and routing (getting the signal into wherever you run evals or review annotations). Each step has pitfalls.
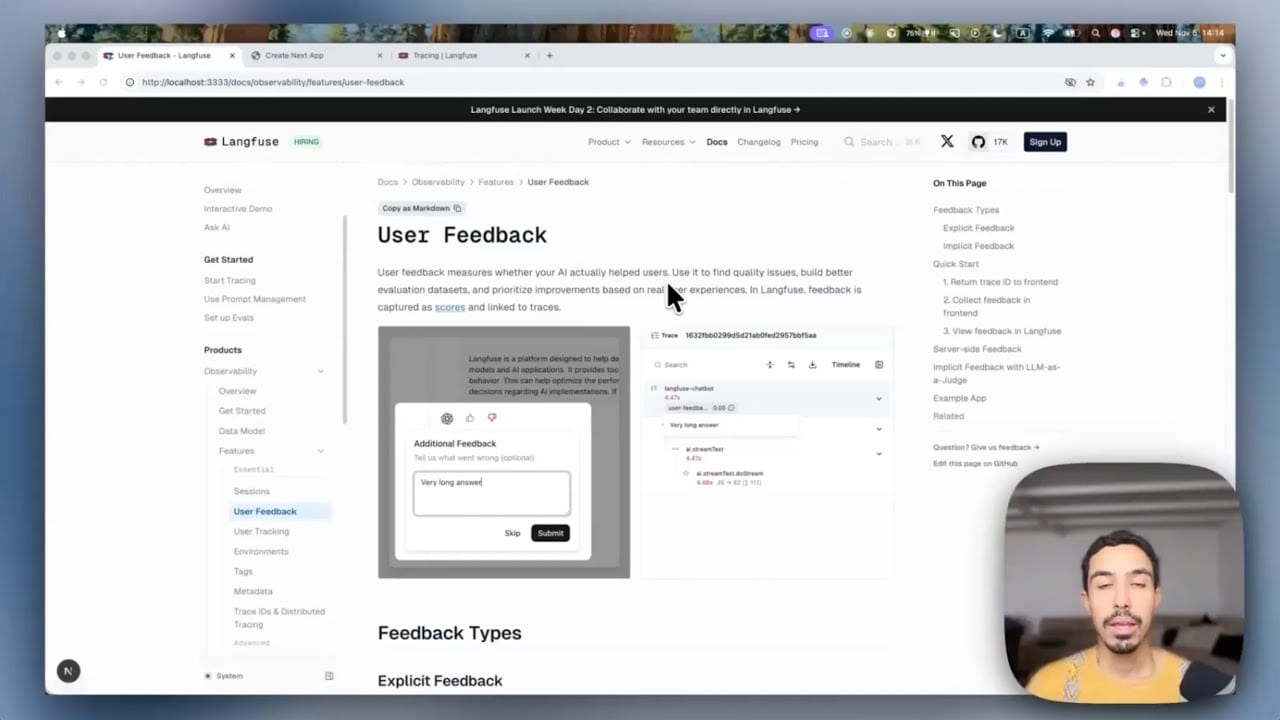
Step 1 — Attach a trace ID to every response
Nothing works without this step. When the LLM generates a response, your observability layer (Langfuse, LangSmith, Datadog LLM Obs, etc.) creates a trace with a unique trace_id. That ID must travel to the frontend so that when the user clicks thumbs-down two minutes later, you know which generation they're rating.
In practice you embed the trace_id in the API response payload. On the frontend, the feedback button's click handler reads it and sends it back with the rating. Without the ID you have orphaned feedback with no way to look up the prompt, the context, or the model version.
Step 2 — Attach the score from the client
Langfuse, for example, exposes a browser-safe SDK (langfuse-js) so the frontend can POST a score directly without proxying through your backend:
import Langfuse from 'langfuse';
const langfuse = new Langfuse({
publicKey: process.env.NEXT_PUBLIC_LANGFUSE_PUBLIC_KEY,
});
// Called when user clicks thumbs-up (value=1) or thumbs-down (value=0)
async function submitFeedback(traceId: string, thumbs: 'up' | 'down') {
await langfuse.score({
traceId,
name: 'user-feedback',
value: thumbs === 'up' ? 1 : 0,
dataType: 'BOOLEAN',
});
}Step 3 — Capture implicit signals as custom events
Implicit signals require a small amount of instrumentation. You add event listeners on the frontend and fire analytic events when specific behaviors happen. PostHog, Mixpanel, or your own data pipeline can receive these; alternatively, send them through the same observability backend you're using for traces:
// When user copies response text
copyButton.addEventListener('click', () => {
analytics.track('llm_response_copied', { traceId, responseLength });
});
// When user edits AI-generated draft before submitting
textArea.addEventListener('input', () => {
if (!hasEdited) {
hasEdited = true;
analytics.track('llm_response_edited', { traceId });
}
});
// When user clicks Regenerate
regenerateButton.addEventListener('click', () => {
analytics.track('llm_response_regenerated', { traceId, attemptNumber });
});Signal taxonomy: explicit vs. implicit
Not all signals carry equal weight. Here is a practical taxonomy, ordered roughly from strongest to weakest quality signal:
| Signal | Type | Direction | Reliability | Coverage |
|---|---|---|---|---|
| Thumbs-down + comment | Explicit | Negative | Very high — user stated intent | Very low (<1%) |
| Thumbs-down (no comment) | Explicit | Negative | High | Low (1–3%) |
| Thumbs-up | Explicit | Positive | Medium — selection bias | Very low (<1%) |
| User edits response | Implicit | Negative (partial) | High — they found it wrong or incomplete | Low–medium (1–5%) |
| Regenerate / retry same prompt | Implicit | Negative | High | Low–medium (2–8%) |
| Immediate rephrasing of prompt | Implicit | Negative | Medium–high | Medium |
| Response copied to clipboard | Implicit | Positive | Medium | Medium–high |
| Session abandoned after turn 1 | Implicit | Negative | Medium (could be task done) | High |
| Long dwell time before next action | Implicit | Mixed (confusion or reading) | Low alone | High |
A single signal in isolation is noisy. A user who copies a response and then immediately regenerates it is sending conflicting messages. The power comes from aggregating across thousands of sessions: a sudden spike in the retry rate for a specific prompt template, or a drop in copy-rate for a specific output type, is a reliable quality regression signal even if no individual trace is conclusive.
The coverage gap
Explicit feedback from thumbs captures at most 1–3% of interactions in most production apps — and that's with well-placed, low-friction UI. Implicit signals can cover 20–60% of interactions depending on the app type (coding assistants have high copy rates; conversational apps have high retry rates). Using both layers closes most of the coverage gap and gives you a far richer picture of quality than either method alone.
UI design that actually gets feedback
The biggest lever on explicit feedback rate is friction. The ChatGPT thumbs placement — inline with each assistant message, always visible, one click to rate — is deliberate UX. Each design choice you make here meaningfully shifts how much data you collect.
- Inline beats modal. A feedback form that opens a modal or new page kills response rate. Thumbs or star icons inline with the response, visible without scrolling, have substantially higher engagement.
- Ask why on thumbs-down only. Prompting for a reason on thumbs-down (a small dropdown with 4–6 options like "Wrong information," "Too long," "Didn't follow instructions," "Offensive") yields categorized data without overwhelming satisfied users with surveys.
- Delay, don't block. Show the rating widget 2–3 seconds after the response streams in, not before. Users can't rate something they're still reading.
- Conversational follow-up for high-friction apps. In a chat interface, after a thumbs-down the LLM can ask: "What could I have done better?" This keeps users in context and lowers the barrier to a longer explanation compared to an external form.
- Copy-and-done apps need implicit signals most. In a writing assistant or code generator where the happy path is just copying the output, almost nobody will rate anything explicitly. Instrument copy, accept, and insert-at-cursor events and treat copy as your positive signal.
Going deeper
Closing the loop: feedback to evals
Collecting feedback signals is only half the job. The other half is turning them into a feedback loop that actually improves the model or the prompt. The standard pipeline looks like this: thumbs-down traces flow into an annotation queue, where a human reviewer (or an LLM judge) examines the full trace — the system prompt, the user message, the response — and adds a structured label. Those labeled traces become eval examples that you run against new prompt or model candidates before deploying them.
Observability platforms like Langfuse and LangSmith have annotation queues built in. You set a filter — for example, all traces with a user-feedback score of 0 in the last 7 days — and the platform surfaces them for review. The annotation step upgrades a binary thumbs-down ("something was wrong") into a structured label ("wrong factual claim about X", "missed the tone requirement", "hallucinated a URL") that is actionable for prompt engineering.
Reward models and online learning
At scale, a team can train a lightweight user-signal reward model on aggregated binary feedback (thumbs-up = 1, thumbs-down = 0, or emoji reactions like the Love reaction used in some enterprise deployments). The reward model learns to predict the probability that a response will receive a positive signal from user behavior. This model can then score responses at inference time — enabling automatic quality filtering or routing — without requiring a human or an expensive frontier model judge on every call.
A 2025 paper on Reinforcement Learning from User Feedback (RLUF) showed that policy optimization using a reward model trained on implicit user reactions (specifically binary love-reaction signals from a production chat product) produced a 28% increase in positive-reaction rates in live A/B tests compared to the baseline model. That's a concrete, measurable outcome from implicit feedback that required no extra user effort to collect.
Sampling strategies for annotation queues
Routing all thumbs-down traces to annotation is fine at low volume, but at scale you need sampling strategies to keep annotation costs manageable without losing coverage of rare failure modes:
- Stratified sampling by feature area. If your app has multiple prompt templates (search, summarize, draft), sample a fixed number from each per week so no area becomes invisible.
- Cluster before you sample. Embed traces with a cheap model and cluster them. Sample from each cluster, not uniformly from the raw list — this prevents your annotation set from being dominated by 80% of traces that all exhibit the same common failure.
- Prioritize novel failures. Use cosine similarity against your existing eval set to surface traces that are least similar to anything you've already labeled. These are the highest-value examples for expanding coverage.
- Keep a random baseline. A small random sample (5–10% of the annotation budget) of all traces — not just flagged ones — guards against survivorship bias and helps you discover silent failures that users didn't bother to flag.
Privacy and consent considerations
Implicit behavioral telemetry is governed by the same privacy rules as any analytics event — GDPR in the EU, CCPA in California. At minimum: disclose the collection in your privacy policy, do not log the content of the user's clipboard (only the event that a copy occurred), and apply the same data-retention limits to feedback and trace data as you do to other personal data. Many observability platforms support PII masking and region-specific data residency — enable those features before you go to production.
FAQ
How many users actually click the thumbs-up or thumbs-down button?
In most production LLM apps, explicit feedback rates are below 3% of interactions. Some well-designed apps with very active users reach 5–10%. Because happy users have no reason to click anything, thumbs-up counts are heavily biased toward engaged power users. Plan your eval strategy around the assumption that explicit feedback will be sparse — implicit signals are how you cover the other 97%.
What is the minimum feedback instrumentation I need to ship?
At a minimum: (1) log every LLM generation with a unique trace_id and expose it in the API response; (2) add a thumbs-down button inline with each response that POSTs the trace_id and a 0 score to your observability backend; (3) track the regenerate/retry event. With just those three things you can build a basic annotation queue and start collecting labeled eval examples.
Should I track implicit signals like copy events even if I have explicit thumbs?
Yes, especially if your app is a writing assistant or code generator where the happy path is just copying output. Explicit feedback from this user segment is near-zero — satisfied users copy and leave. A high copy-rate on a response type is your primary positive quality signal. Track both; use implicit signals to fill the 97%+ gap that explicit feedback doesn't cover.
What's the difference between a score and a trace in Langfuse?
A trace is the full record of a single request: the prompt, the response, latency, token counts, and any intermediate steps (tool calls, retrieval). A score is a separate object you attach to a trace after the fact — a name (like user-feedback), a numeric or boolean value, and an optional comment. Scores are how feedback from the user, an LLM judge, or an annotation queue all land in the same place for comparison.
Can I use user feedback to fine-tune my model?
Yes, but it requires structuring the feedback as preference pairs: a chosen response (thumbs-up) paired with a rejected response (thumbs-down) for the same or similar prompt. This is the input format for DPO (Direct Preference Optimization) fine-tuning. The challenge is that thumbs-up and thumbs-down rates are low enough that accumulating sufficient pairs takes significant traffic — most teams fine-tune on curated annotation data and use production feedback to identify which examples to curate.
How do I handle adversarial or manipulated feedback?
Users can game explicit ratings — either brigading thumbs-down on valid responses or clicking thumbs-up without reading. Defenses include: rate-limiting feedback submissions per user per session, requiring authentication before accepting feedback, and treating obvious outliers (a user who rates every single response identically) as noise. Implicit signals are harder to manipulate at scale because they require actual behavioral patterns.