In plain English
Every AI builder eventually hits this fork: "My model doesn't know our stuff — should I feed it our documents at runtime, or should I retrain it on that data?" The first path is RAG (retrieval-augmented generation). The second is fine-tuning. They sound interchangeable, but they do genuinely different things.
Here is the one-sentence rule you can carry forever: RAG changes what the model knows. Fine-tuning changes how the model behaves. Everything else flows from that.
Imagine you hire a brilliant new employee. RAG is handing them a reference binder every morning — "here are today's documents; answer from these." Fine-tuning is sending them to a six-month training programme that reshapes how they think, speak, and format their reports. The binder swap takes a minute; the training programme takes real time and money. Both have their place.
Why it matters
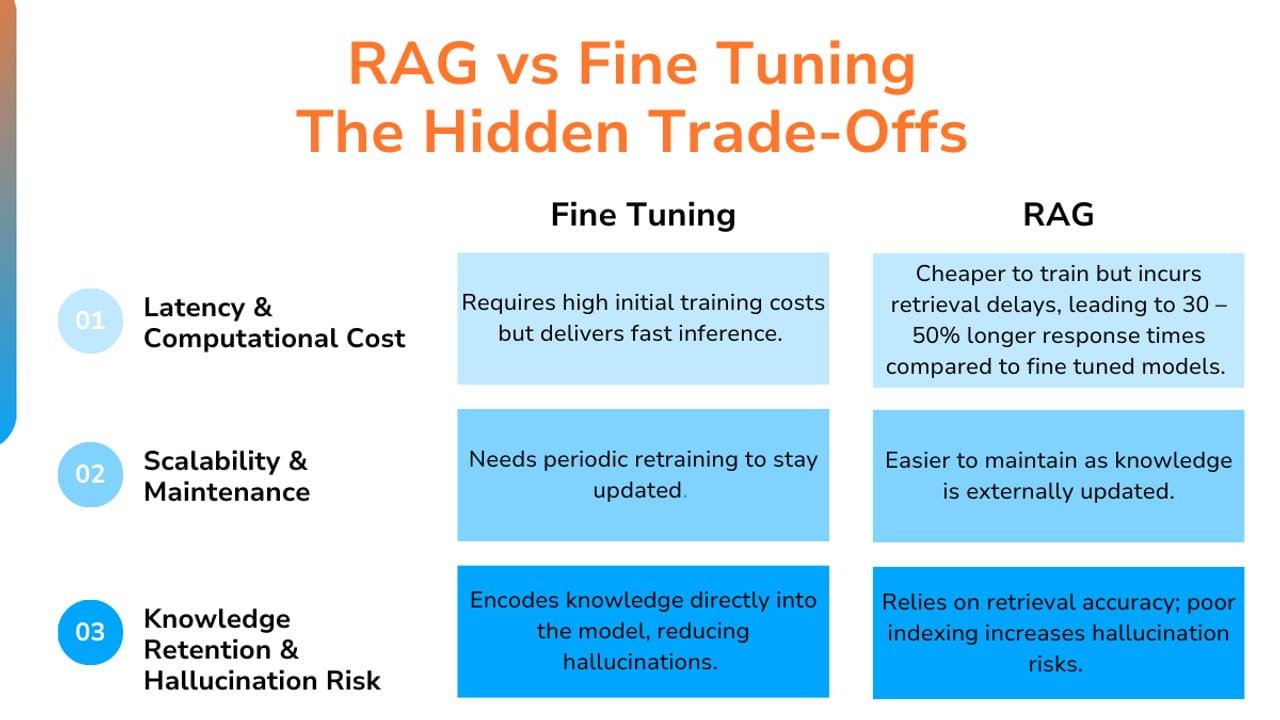
Picking the wrong approach is expensive in every sense. Fine-tuning on constantly-changing data means you're re-running training runs every week just to stay current. Using RAG for a task that really needs a learned output style means every answer sounds wrong even when the facts are right. The mismatch wastes time, money, and user trust.
The stakes are real in production. According to the Menlo Ventures 2024 State of Generative AI in the Enterprise report, 51% of enterprise AI deployments use RAG in production, while only 9% rely primarily on fine-tuning. That gap exists because RAG is the faster, cheaper, lower-risk starting point for most knowledge problems — and knowledge problems are the most common problems builders face.
But that doesn't mean fine-tuning is obsolete. Teams that need a model to always write in a strict JSON schema, follow a specialized clinical tone, or respond with a proprietary decision protocol find that no amount of prompting and retrieval quite gets them there. Fine-tuning bakes the pattern into the weights so the model never drifts from it.
How each approach works
How RAG works
RAG keeps the base model completely frozen. At query time, it retrieves the most relevant passages from an external document store (a vector database full of your content), appends them to the prompt, and asks the model to answer from that context. Update a document in the store and the next answer automatically reflects it — no retraining needed.
How fine-tuning works
Fine-tuning continues the training process on your curated dataset, adjusting the model's weights so a new pattern is baked in. The model no longer needs to see examples of that pattern at inference time — it just behaves that way. Training runs can take minutes (for a small LoRA adapter on an open model) or days and thousands of dollars (for a full fine-tune of a large proprietary model).
The key structural difference
RAG separates knowledge from reasoning — the model is fixed, the documents are swappable. Fine-tuning fuses them — the knowledge or behavior is embedded in the weights and cannot be easily removed or updated without another training run. That is not a flaw of fine-tuning; it is its feature when the pattern is stable. It is a serious liability when the data changes.
When to use each one
The question that redirects most decisions is: Is this a knowledge problem or a behavior problem? Knowledge problems — the model doesn't know your current data — almost always call for RAG. Behavior problems — the model doesn't consistently produce the right format, tone, or decision logic — are where fine-tuning earns its cost.
| Situation | Reach for |
|---|---|
| Knowledge base changes frequently (daily/weekly) | RAG |
| You need source citations or auditability | RAG |
| Data is private and can't be included in training | RAG |
| You're starting out and want speed | RAG |
| Output format must be exact and never drifts | Fine-tuning |
| Specific tone or brand voice must be consistent | Fine-tuning |
| Domain vocabulary confuses the base model | Fine-tuning |
| You have stable, high-quality labeled examples | Fine-tuning |
| You need both current facts and consistent style | Both (hybrid) |
A concrete illustration: a customer-support bot for a software product needs to answer questions about features, pricing, and known issues — all of which change with every release. RAG is the right call: point it at the latest docs and it stays accurate automatically. Contrast that with a medical coding assistant that must always output structured ICD-10 codes in a specific schema and never output free prose. That output pattern is stable and lives entirely in format, not in facts — fine-tuning is the right call, and a RAG layer on top can supply the current clinical guidelines.
Cost and maintenance reality
Cost is one of the biggest decision factors in practice, and it breaks down very differently for the two approaches.
RAG costs
RAG's upfront cost is low. You need an embedding model (OpenAI's text-embedding-3-small costs roughly $0.02 per million tokens) and a vector database (Pinecone, Qdrant, Chroma, pgvector, or FAISS). A basic RAG system can be operational for under $10,000 including engineering time. The ongoing cost is retrieval plus standard LLM inference — slightly higher latency per query than a plain prompt because of the retrieval step, but embedding is cheap. Maintenance is simple: add or remove documents, no retraining needed.
Fine-tuning costs
Fine-tuning front-loads the cost. Hosted fine-tuning on a frontier API (the GPT, Claude, or Gemini families) is billed per million training tokens, with smaller tiers costing a fraction of the flagship rate — check the current provider price list, since rates move often. Full fine-tuning a large proprietary model can run from $5,000 to over $50,000 depending on dataset size and provider. Inference on a fine-tuned model is then faster than RAG (no retrieval step) and pricing is predictable, which favors high-volume repetitive tasks. But every meaningful update to your domain knowledge requires a new training run — more compute, more data prep, more QA cycles.
For open-source models (Llama, Mistral, Qwen), the training cost drops dramatically if you have your own GPU cluster or use a cloud fine-tuning service like Modal or Lambda. LoRA (low-rank adaptation) and QLoRA techniques reduce the compute needed by an order of magnitude by only updating a small set of adapter weights instead of the full model. These make fine-tuning practical for teams that previously couldn't afford it.
- Low upfront setup cost
- Embedding: ~$0.02/M tokens
- Ongoing: retrieval + standard inference
- Update: edit a document
- Scales with query volume
- High upfront training cost
- Hosted fine-tune: billed per training token
- Ongoing: faster inference, fixed cost/query
- Update: new training run
- Saves money at very high volume
The hybrid approach: using both
The most mature AI systems in production use RAG and fine-tuning together, because they solve different problems and compose cleanly. The pattern is: fine-tune for behavior, deploy with RAG for knowledge.
A real example: a financial analysis assistant might be fine-tuned on thousands of analyst reports so it reliably outputs structured summaries in the house style with the right field names and confidence notation. Then, at query time, RAG injects the current SEC filing or earnings transcript it should actually analyze. The fine-tuned model handles how to structure the output; RAG handles what data to analyze. Neither could do the other's job.
An emerging variant is RAFT (retrieval-augmented fine-tuning), where the training data itself is constructed by pairing questions with retrieved context documents — teaching the model not just a behavior pattern, but how to reason over retrieved passages effectively. This closes the gap when a base model struggles to correctly use the context that RAG injects.
Going deeper
Once you've made the RAG-vs-fine-tuning call and built a working system, a few advanced considerations become relevant.
Evaluation drives the decision. The only reliable way to know whether your RAG system is good enough — or whether fine-tuning would actually help — is to measure it. For RAG, that means tracking retrieval recall (did the right document come back?) and answer faithfulness (did the model actually use it?). For fine-tuning, that means holding out a test set before training and measuring performance before you spend the money. Anecdotes from demo questions are not a substitute for systematic evaluation.
RAG failure modes. The top reason RAG deployments fail is poor data quality — the Gartner 2024 forecast projected that 80% of enterprise RAG implementations would fail by 2026, with bad source data as the primary cause. Garbage in, garbage out is not a RAG-specific problem, but RAG makes it painfully visible because the model will faithfully reproduce whatever is in the retrieved chunks, including outdated policies, contradictory content, and formatting noise. Clean your data before you debug your retrieval.
Fine-tuning alignment risk. When you fine-tune, you can accidentally over-fit the model to surface patterns in your training data that you didn't intend to teach — style artifacts, biases in your example responses, or narrow behavior that breaks on out-of-distribution inputs. A base model with a good prompt is often more robust to novel inputs than a fine-tuned one. This is why the canonical advice is to use fine-tuning only after you have high-quality, representative training data and a held-out test set to catch regressions.
The long-context caveat. As context windows keep growing (128K, 1M tokens and beyond), the "just paste everything in" approach becomes viable for a wider range of corpora. For a single 200-page handbook queried a handful of times a day, long context may simply be the right answer — no vector database, no training run, just a larger prompt. The tradeoff is cost: every token in a long context is billed on every request, so the math flips once query volume or corpus size gets large.
Agentic systems blur the line. In an agentic architecture, the model decides whether to retrieve and what to retrieve by calling a search tool. The base model's ability to correctly invoke and reason over tool results starts to matter as much as the retrieval system itself. A fine-tuned model that was trained on examples of good tool use can outperform a stronger base model that wasn't — so the RAG-vs-fine-tuning question can reappear at the tool-use layer even after you've settled it at the knowledge layer.
FAQ
When should I use RAG vs fine-tuning for custom data?
Start with RAG whenever your data changes over time or you need source citations. Use fine-tuning when you need a consistent output format, tone, or decision pattern that prompting alone cannot reliably produce. If your problem is "the model doesn't know our documents," RAG is almost always the right first move.
Can fine-tuning replace RAG by baking knowledge into the model?
No, and this is a common and expensive mistake. Fine-tuning is unreliable as a knowledge injection mechanism — the model can't easily cite, update, or contradict knowledge stored in its weights. The moment your data changes, you need another training run. Use RAG for facts that need to stay current.
How much does fine-tuning cost compared to RAG?
RAG has low upfront cost: an embedding model (around $0.02 per million tokens for OpenAI's smaller model) plus a vector database. Fine-tuning on a hosted frontier model is billed per million training tokens (check the current provider price list), and a full fine-tune can run from $5,000 to over $50,000 depending on dataset size. RAG is cheaper to start; fine-tuning can become cost-effective for very high-volume, repetitive tasks.
Is it possible to use both RAG and fine-tuning together?
Yes, and it is the pattern most mature production systems use. You fine-tune the model for behavior — output format, tone, domain vocabulary — and deploy it with RAG for knowledge retrieval at inference time. The two techniques compose cleanly because they operate at different stages: training versus query time.
Does RAG or fine-tuning work better for reducing hallucinations?
RAG is generally more effective at reducing factual hallucinations because it grounds the model in actual source text at query time. Fine-tuning can reduce hallucinations in style or format (the model stops inventing field names, for example), but it does not reliably prevent the model from generating plausible-sounding wrong facts when asked about things outside its training data.
What is RAFT and how does it relate to RAG vs fine-tuning?
RAFT (retrieval-augmented fine-tuning) is a hybrid technique where training examples are constructed by pairing questions with retrieved context documents, teaching the model how to reason over RAG-style context. It is used when a base model struggles to correctly use the passages that a RAG system retrieves, closing the gap between the two approaches.