
Overview
DeepSeek-Math-V2 is a specialized mathematical-reasoning model from DeepSeek, released on 27 November 2025 as the current flagship of the DeepSeek Math line. It is a 685-billion-parameter Mixture-of-Experts model built on the DeepSeek-V3.2-Exp-Base checkpoint, and it is published as open weights on Hugging Face under the Apache 2.0 license. Unlike a general chat model, DeepSeek-Math-V2 is tuned for writing rigorous natural-language proofs rather than just producing a final numeric answer.
The model's defining idea is self-verification. DeepSeek trains an LLM-based verifier with reinforcement learning (GRPO) that scores a candidate proof on rigor and completeness, plus a meta-verifier that checks the verifier's own critiques so it does not hallucinate flaws. The proof generator is then rewarded for producing solutions whose self-assessed quality matches the verifier's judgment, and it iteratively repairs its own proofs within a 128K-token context before finalizing an answer. This 'verify-first' pipeline is what lets DeepSeek-Math-V2 catch and fix its own mistakes the way a human mathematician re-checks a proof.
With scaled test-time compute and large verification budgets, DeepSeek-Math-V2 reaches gold-medal-level performance on IMO 2025 and CMO 2024 and scores 118 of 120 on Putnam 2024 — above the best human score that year. On the IMO-ProofBench evaluation it outperforms Google DeepMind's DeepThink IMO Gold on the Basic subset and stays competitive on the Advanced subset, making it one of the strongest openly released math-reasoning models to date. Because it is open-weight, researchers can download and run it via the DeepSeek-V3.2-Exp inference stack.
| Released | 2025-11-27 |
|---|---|
| License | Apache-2.0 |
| Weights | Open weights |
| Parameters | 685B total (MoE) |
| Context | 128K |
| Architecture | Mixture-of-Experts (verifier-generator self-verification) |
| Modalities | Text |
| Status | Research preview |
Benchmarks
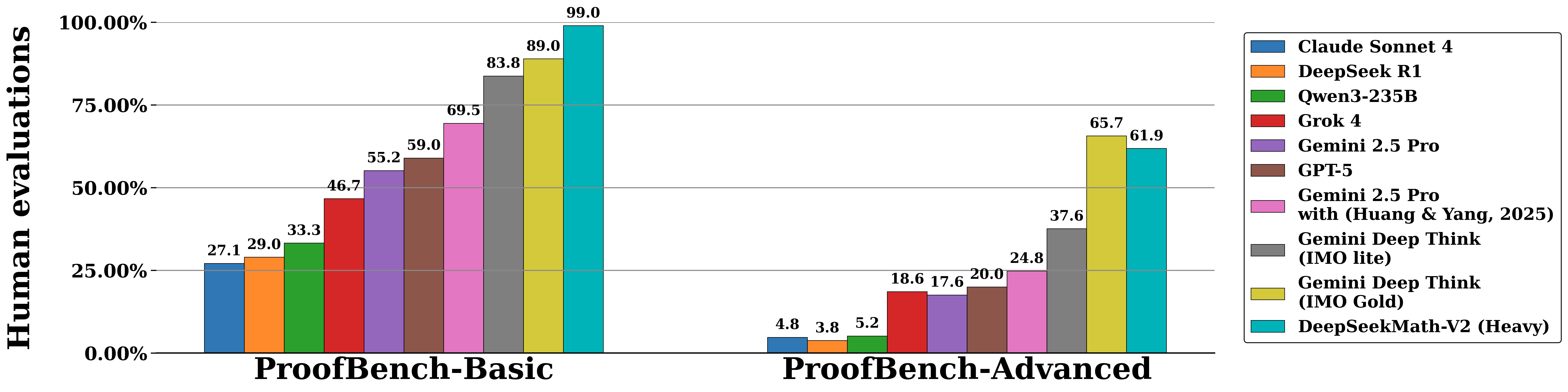
IMO-ProofBench human-evaluation scores (%): DeepSeekMath-V2 (Heavy) vs. other named models, on ProofBench-Basic and ProofBench-Advanced. Transcribed from the IMO-ProofBench.png chart on the DeepSeek-Math-V2 model card.
| Benchmark | Claude Sonnet 4 | DeepSeek R1 | Qwen3-235B | Grok 4 | Gemini 2.5 Pro | GPT-5 | Gemini 2.5 Pro with (Huang & Yang, 2025) | Gemini Deep Think (IMO lite) | Gemini Deep Think (IMO Gold) | DeepSeekMath-V2 (Heavy) |
|---|---|---|---|---|---|---|---|---|---|---|
| IMO-ProofBench (ProofBench-Basic) | 27.1% | 29% | 33.3% | 46.7% | 55.2% | 59% | 69.5% | 83.8% | 89% | 99% |
| IMO-ProofBench (ProofBench-Advanced) | 4.8% | 3.8% | 5.2% | 18.6% | 17.6% | 20% | 24.8% | 37.6% | 65.7% | 61.9% |
This model's scores
Scores on a 0–100 scale (25-point gridlines); higher is better. Each benchmark links to its published source.
Strengths
- Open Apache-2.0 weights at frontier scale (685B MoE), free for research and commercial use and fully self-hostable
- Self-verifying proof pipeline: a GRPO-trained verifier plus meta-verifier let the model critique and repair its own proofs before answering
- Gold-medal-level results on elite math olympiads (IMO 2025, CMO 2024) and a near-perfect 118/120 on Putnam 2024
- Writes rigorous natural-language proofs, not just final answers — built for theorem-proving rather than arithmetic
- Beats DeepMind's DeepThink IMO Gold on the IMO-ProofBench Basic subset among compared systems
Best for
- Automated theorem proving and verification of multi-step mathematical proofs
- Research on self-verification, verifier-reward training, and test-time-compute scaling for reasoning
- Generating and grading olympiad-style and competition math solutions
- Self-hosted math-reasoning deployments where open Apache-2.0 weights are required
- Building proof-checking or math-tutoring tools on top of an open-weight reasoning model
How to access
| Provider | Model ID |
|---|---|
| Hugging Face (open weights) ↗ | deepseek-ai/DeepSeek-Math-V2 |
DeepSeek Math — every version
The full lineage of the DeepSeek Math line, newest first. Every version has its own page — click any to compare specs, benchmarks and pricing.
| Version | Released | Context | License |
|---|---|---|---|
| DeepSeek-Math-V2current | 2025-11-27 | — | Apache-2.0 |
| DeepSeekMath | 2024-04 | — | Open weights |
FAQ
Is DeepSeek-Math-V2 open source?
The weights are published openly on Hugging Face under the Apache 2.0 license, so you can download, run, fine-tune, and use DeepSeek-Math-V2 for research and commercial purposes, including self-hosted deployment. It is run with the DeepSeek-V3.2-Exp inference stack rather than a hosted DeepSeek API endpoint.
How big is DeepSeek-Math-V2?
It is a 685-billion-parameter Mixture-of-Experts model built on the DeepSeek-V3.2-Exp-Base checkpoint, and it works within a 128K-token context. It is text-only and specialized for mathematical proof writing rather than general chat.
What makes DeepSeek-Math-V2 different from other reasoning models?
It is trained to self-verify. DeepSeek trains an LLM verifier (with GRPO) and a meta-verifier that score proofs on rigor and completeness, and the proof generator is rewarded for producing solutions that hold up to that verification — iteratively repairing its own proofs before finalizing an answer.
How well does DeepSeek-Math-V2 perform on math competitions?
With scaled test-time compute it reaches gold-medal-level performance on IMO 2025 and CMO 2024 and scores 118 of 120 on Putnam 2024, above the top human score that year. On IMO-ProofBench it outperforms DeepMind's DeepThink IMO Gold on the Basic subset and stays competitive on the Advanced subset.