
Overview
DeepSeek-V3.2 is the flagship model of DeepSeek's V3 line, released December 1, 2025. It is a Mixture-of-Experts model with 685B total parameters and roughly 37B active per token, published openly under the MIT license alongside an API-only high-compute sibling, DeepSeek-V3.2-Speciale. DeepSeek positions V3.2 as a 'daily driver at GPT-5-level performance' while keeping inference cheap.
The headline technical change is DeepSeek Sparse Attention (DSA), the sparse-attention mechanism first trialled in V3.2-Exp and now productized: it sharply reduces the compute of long-context inference without measurably hurting quality. V3.2 is also DeepSeek's first model to integrate thinking directly into tool-use, and it supports tool calls in both thinking and non-thinking modes — trained with an agentic data-synthesis pipeline spanning 1,800+ environments and 85k+ complex instructions.
V3.2 ships on the DeepSeek app, web chat, and API, and its weights and technical report are public. It is the successor to DeepSeek-V3.2-Exp and the current top of the V3 series, sitting just below the later DeepSeek-V4 line.
| Released | 2025-12-01 |
|---|---|
| License | MIT |
| Weights | Open weights |
| Parameters | 685B total / 37B active (MoE) |
| Context | 128K |
| Max output | 64K |
| Architecture | Mixture-of-Experts transformer with DeepSeek Sparse Attention (DSA), a fine-grained sparse attention mechanism that cuts the cost of long-context inference while preserving quality. Ships a single hybrid checkpoint that runs in both thinking and non-thinking modes. |
| Knowledge cutoff | Not disclosed |
| Modalities | Text |
| Status | Available |
Benchmarks
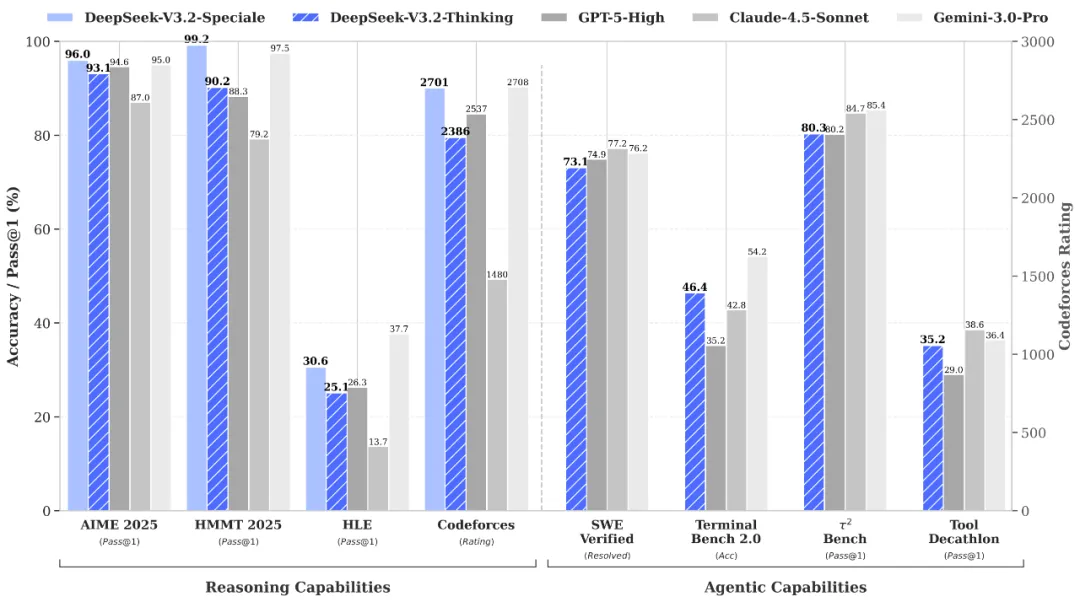
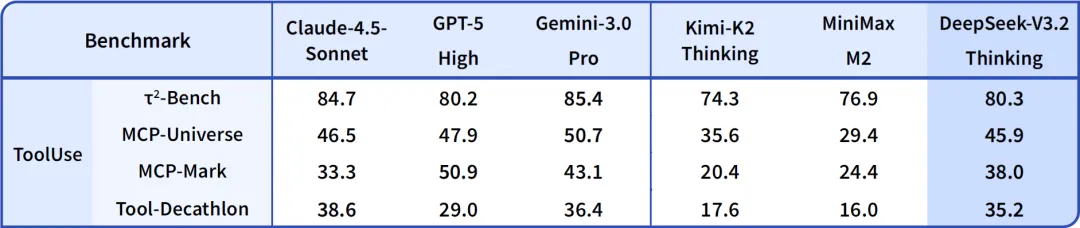
DeepSeek-V3.2 (Thinking and Speciale) benchmark comparison vs GPT-5 High, Gemini-3.0 Pro, and Kimi-K2 Thinking, as published by DeepSeek (numbers in the source are accompanied by per-task thinking-token budgets, e.g. 13k; only the score is given here).
| Benchmark | GPT-5 High | Gemini-3.0 Pro | Kimi-K2 Thinking | DeepSeek-V3.2 Thinking | DeepSeek-V3.2 Speciale |
|---|---|---|---|---|---|
| AIME 2025 | 94.6 Acc (%) | 95 Acc (%) | 94.5 Acc (%) | 93.1 Acc (%) | 96 Acc (%) |
| HMMT Feb 2025 | 88.3 Acc (%) | 97.5 Acc (%) | 89.4 Acc (%) | 92.5 Acc (%) | 99.2 Acc (%) |
| HMMT Nov 2025 | 89.2 Acc (%) | 93.3 Acc (%) | 89.2 Acc (%) | 90.2 Acc (%) | 94.4 Acc (%) |
| IMOAnswerBench | 76 Acc (%) | 83.3 Acc (%) | 78.6 Acc (%) | 78.3 Acc (%) | 84.5 Acc (%) |
| LiveCodeBench | 84.5 Acc (%) | 90.7 Acc (%) | 82.6 Acc (%) | 83.3 Acc (%) | 88.7 Acc (%) |
| CodeForces | 2537 Rating | 2708 Rating | — | 2386 Rating | 2701 Rating |
| GPQA Diamond | 85.7 Acc (%) | 91.9 Acc (%) | 84.5 Acc (%) | 82.4 Acc (%) | 85.7 Acc (%) |
| HLE | 26.3 Acc (%) | 37.7 Acc (%) | 23.9 Acc (%) | 25.1 Acc (%) | 30.6 Acc (%) |
This model's scores
Scores on a 0–100 scale (25-point gridlines); higher is better. Each benchmark links to its published source.
Pricing
| Input | $0.30 per 1M tokens |
|---|---|
| Cached input | $0.135 per 1M tokens |
| Output | $0.45 per 1M tokens |
Reasoning (deepseek-reasoner) tier; cache-hit input is discounted ~55%. The non-thinking deepseek-chat tier is cheaper still. Prices reflect the Dec 2025 release.
Strengths
- Open weights under the permissive MIT license — fully self-hostable
- DeepSeek Sparse Attention makes long-context inference markedly cheaper than dense attention
- First DeepSeek model to fold reasoning directly into tool-use, in both thinking and non-thinking modes
- GPT-5-level general performance at a fraction of frontier-model API pricing
- Strong math, coding, and agentic results from training across 1,800+ environments
Best for
- Cost-sensitive agentic workflows that need tool-calling plus reasoning
- Long-document and large-codebase tasks where sparse attention lowers cost
- Self-hosted deployments that require open weights and a permissive license
- Math and competitive-programming problem solving
- General assistant and coding workloads at GPT-5-class quality
How to access
| Provider | Model ID |
|---|---|
| DeepSeek ↗ | deepseek-chat / deepseek-reasoner (DeepSeek-V3.2) |
| OpenRouter ↗ | deepseek/deepseek-v3.2 |
DeepSeek V3 — every version
The full lineage of the DeepSeek V3 line, newest first. Every version has its own page — click any to compare specs, benchmarks and pricing.
| Version | Released | Context | License |
|---|---|---|---|
| DeepSeek-V3.2current | 2025-12-01 | — | Open weights |
| DeepSeek-V3.2-Speciale | 2025-12-01 | — | Open weights |
| DeepSeek-V3.2-Exp | 2025-09-29 | — | Open weights |
| DeepSeek-V3.1-Terminus | 2025-09-22 | — | Open weights |
| DeepSeek-V3.1 | 2025-08-21 | — | Open weights |
| DeepSeek-V3-0324 | 2025-03-24 | — | Open weights |
| DeepSeek-V3 | 2024-12-26 | — | Open weights |
| DeepSeek-V2.5 | 2024-09-05 | — | Open weights |
| DeepSeek-V2 | 2024-05 | — | Open weights |
FAQ
Is DeepSeek-V3.2 open source?
The weights are released openly under the MIT license, so you can download, run, and fine-tune the model yourself. DeepSeek also published a technical report describing the architecture and training.
What is DeepSeek Sparse Attention (DSA)?
DSA is the fine-grained sparse-attention mechanism at the core of V3.2. It substantially reduces the compute needed for long-context inference while preserving model quality, which is what lets V3.2 run long contexts cheaply compared with dense-attention models.
How does V3.2 differ from V3.2-Speciale?
V3.2 is the balanced 'daily driver' positioned at GPT-5-level performance and available on the app, web, and API. V3.2-Speciale is a high-compute, API-only variant that maxes out reasoning (gold-medal-level results on the 2025 IMO and IOI) but uses far more tokens.
Does V3.2 support tool use and reasoning together?
Yes. V3.2 is DeepSeek's first model to integrate thinking directly into tool-use, and it supports tool calls in both thinking and non-thinking modes. It was trained with an agentic data pipeline covering 1,800+ environments and 85k+ complex instructions.