In Plain English
Imagine hiring a new employee and handing them a binder of 200 laminated checklists — one for every conceivable task. They spend more time leafing through checklists than doing work, and if their exact situation isn't covered, they're stuck. Now imagine instead handing them a laptop and saying: 'Here are five APIs you can call. Write a short script whenever you need to get something done.' The second employee ships faster, handles novel situations, and doesn't need a new checklist every time requirements change.
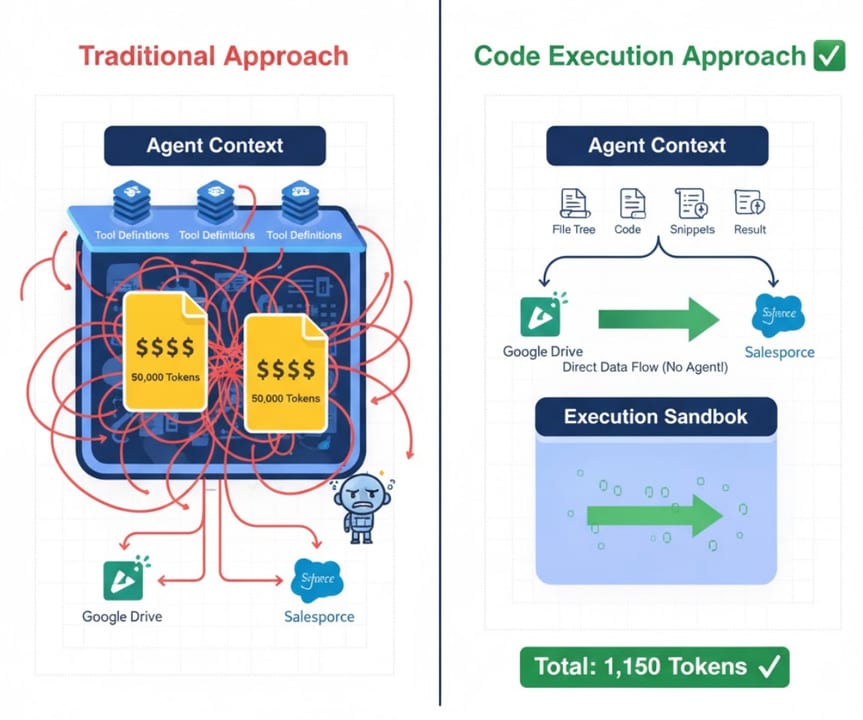
That is exactly the tradeoff at the heart of code execution vs. more tools in AI agents. A dedicated tool is a pre-wrapped function the model can call by name — search_web, send_email, query_database. Each tool must be described in the model's context window so the model knows it exists. A code-execution approach instead gives the agent a sandboxed interpreter and exposes raw APIs or SDKs. The agent writes a few lines of Python or JavaScript, runs them, and reads back the result.
The analogy holds well: dedicated tools are like laminated checklists — fast and reliable for known tasks, but they consume menu space and break down when the catalog grows past what the model can reliably navigate. Code execution is like teaching the employee to program — a higher upfront investment, but the agent can compose arbitrary logic from a small set of primitives.
Why It Matters
The impulse to add tools is natural: every new integration gets wrapped into a tool, the catalog grows, and sooner or later you have fifty or a hundred tools fighting for space in the context window. At that scale the math turns brutal.
Tool count vs. accuracy
Empirical studies on tool-augmented LLMs show a clear cliff. With roughly 50 tools, most frontier models maintain 84-95% task accuracy. Push to 200 tools and accuracy falls to 41-83%. At 740+ tools, accuracy collapses to near zero for most models. The reason is partly attention: every tool description consumes tokens, and the model must implicitly 'scan' all of them to select the right one. Research has also documented a position bias — tools buried in the middle of a long list are systematically under-selected compared to tools at the start or end.
Beyond selection failure, a large catalog bloats the prompt. If each tool schema averages 300 tokens and you have 100 tools, that is 30,000 tokens of definitions before the agent has seen a single word of the actual task.
The token cost of passing data through the model
With classic tool calling, every intermediate result travels back through the model context. Fetch a 5 MB CSV from an API, and the model 'sees' a chunk of that CSV before passing a filtered version on to the next tool. Anthropic's engineering team documented a workflow that consumed around 150,000 tokens when data was passed through the model at each step. After rewriting it with code execution — keeping intermediate data in the execution environment and only surfacing the final result — the same workflow used roughly 2,000 tokens: a 98.7% reduction in token usage, with corresponding cuts to latency and cost.
How It Works
The code-execution pattern flips the data flow. Instead of the model calling one tool, waiting for a result, calling another tool, and so on, the model writes a complete program, the runtime executes it, and only the final output (plus any explicit logs) comes back to the model.
- Model receives 50+ tool schemas in context
- Model selects tool, emits JSON call
- Result flows back into model context
- Model selects next tool, repeats
- All intermediate data visible to model
- Each round-trip costs tokens + latency
- Model receives a small SDK or 2-3 meta-tools
- Model writes Python/JS that composes APIs
- Code runs in a sandbox outside the model
- Only the final result returns to the model
- Intermediate data stays in the runtime
- One round-trip regardless of steps inside
What the agent actually writes
In practice the agent is given a sandbox (a Python interpreter, a Deno/Node runtime, or a V8 isolate) and either a lightweight SDK or a handful of import-able modules that wrap your services. The model is proficient at writing code from its training data — far more so than at correctly selecting from a long list of JSON-schema tool definitions it has never seen before. A simple code-execution action might look like this:
# Agent-generated code running in a sandbox
from my_sdk import calendar, email
events = calendar.list_today() # fetch without returning to model
busiest_slot = max(events, key=lambda e: e.duration)
email.send(
to="team@example.com",
subject="Longest meeting today",
body=f"{busiest_slot.title} runs {busiest_slot.duration} minutes."
)
print("Done") # only this returns to the modelIn the classic tool-calling approach, this would require three separate round-trips — list_calendar_events, find_max_duration, send_email — with the full event list flowing through the model context between each step. In code-execution mode it is a single round-trip, and events never enters the model's context window at all.
Progressive tool discovery
Code execution also enables a pattern called progressive discovery: the agent starts with only a small manifest of available modules, then reads the specific module docs it needs at runtime — similar to how a developer runs help(module) in a REPL. This means the full API surface never has to live in context at once. Anthropic's code-execution-with-MCP write-up describes this as shifting the tool catalog from the model context into the execution environment, spending tokens only on the interfaces the current task actually requires.
Code Mode: The MCP Pattern in Practice
The Model Context Protocol (MCP) was designed to standardize tool exposure, but MCP servers themselves can balloon. A single Cloudflare MCP server covering the full Cloudflare API exposes over 2,500 endpoints. Loading all of those as traditional tool schemas would require more than 1.17 million tokens — more than most context windows can hold.
Cloudflare addressed this by shipping Code Mode for their MCP server. Instead of enumerating 2,500 tools, Code Mode exposes exactly two meta-tools: search() to find relevant API methods by description, and execute() to run agent-generated JavaScript in a secure V8 isolate. The model writes code against a typed TypeScript SDK and only reads back what it explicitly logs. Cloudflare reports this shrinks the token footprint of working with that API from 1.17 million tokens to roughly 1,000 — a ~99.9% reduction.
Framework support
Hugging Face's smolagents library built its primary abstraction, CodeAgent, around this idea. Instead of the JSON-tool-call loop used by frameworks like LangChain, CodeAgent has the model emit Python. Benchmarks from the smolagents team report that code agents complete tasks in ~30% fewer steps and LLM calls than equivalent JSON tool-calling agents, with a roughly 23% higher success rate on complex benchmarks. The CodeAct paper (published at ICML 2024) provided the research foundation: across 17 LLMs on the API-Bank benchmark, code-action agents outperformed JSON-action agents by up to 20% in success rate while requiring up to 30% fewer actions.
from smolagents import CodeAgent, HfApiModel, DuckDuckGoSearchTool
# The agent writes Python; tools become importable callables
agent = CodeAgent(
tools=[DuckDuckGoSearchTool()],
model=HfApiModel("meta-llama/Meta-Llama-3.1-70B-Instruct"),
)
# Agent generates and runs Python code internally
agent.run("Find the top 3 AI releases from the past week and summarize them.")When a Dedicated Tool Still Wins
Code execution is not a universal answer. There are situations where a well-designed dedicated tool is the better choice, and understanding the boundary prevents over-engineering.
| Scenario | Better fit | Reason |
|---|---|---|
| Single, well-defined atomic action (e.g., send a Slack message) | Dedicated tool | Schema validation, retries, and error messages are cleaner than parsing code output |
| Composing multiple API calls with intermediate data | Code execution | Keeps intermediate data out of context, fewer round-trips |
| Untrusted or unknown user input driving the action | Dedicated tool | Sandboxing code from user input is harder; tool schemas constrain the action space |
| Large API surface (100+ endpoints) | Code execution | Tool catalog context cost becomes prohibitive; typed SDK is more compact |
| Simple trigger-action flows (if X then Y) | Dedicated tool | Workflow is known, no composition needed, JSON call is predictable and auditable |
| Real-time streaming data processing | Code execution | Agent can write a loop; a single tool call cannot express ongoing computation |
| Strict compliance / audit trail required | Dedicated tool | Each call is a structured log entry; code output is harder to audit at the step level |
A practical rule of thumb: keep dedicated tools for the primitives (auth, send-message, write-file) and let code handle composition. An agent that has five well-designed primitive tools plus a code interpreter effectively has access to exponentially more actions than an agent with fifty individual tools — without the selection confusion.
Going Deeper
Once you accept code execution as a first-class action, several advanced patterns become available.
Self-debugging loops
Because code execution returns stdout, stderr, and a return value, the agent can inspect its own errors and retry with a corrected program — all without a human in the loop. This is the basis of multi-turn code agents: the model writes code, the sandbox runs it, the traceback comes back if it fails, and the model patches the code. CodeAct demonstrated this explicitly: agents could autonomously self-debug by re-emitting revised code on failure.
Mixing code execution with selective tools
The two patterns are not mutually exclusive. A mature architecture often exposes a small number of high-value, validated tools for operations that need strict schemas (payment processing, access-controlled writes) and a code-execution channel for everything else. The agent decides which path to take based on the task. In MCP terms, this means a few traditional MCP tools alongside a code_execute tool backed by a sandboxed runtime.
Structured outputs from code
One practical concern with code execution is that the output is free-form text. The Hugging Face team addressed this by combining CodeAgent with structured outputs: the generated code is constrained to produce a valid JSON blob matching a Pydantic schema. This gives the composability of code with the predictability of structured tool responses — the best of both approaches.
Token budget management at scale
For production systems with dozens of MCP servers, the progressive-discovery pattern can be implemented as a two-stage context: a manifest stage where the agent reads a compact index of available modules (a few hundred tokens), followed by an action stage where it imports only the modules it identified. This is analogous to how human developers use IDE autocomplete and hover-docs rather than memorizing entire API references. The result is that context usage stays roughly constant regardless of how many backend services are available — a key scalability property as agentic systems grow.
FAQ
Does code execution mean the agent can do anything on my server?
Only if you let it. Code execution requires a sandbox — a Python subprocess with restricted imports, a Deno process with explicit permissions, or a V8 isolate. The agent writes code that runs inside that container. What it can access is determined by what you mount or expose in the sandbox, not by what the model generates.
Why do code agents outperform JSON tool-calling agents on complex tasks?
LLMs have seen millions of lines of real-world code during training but only contrived tool-call JSON examples. Code is also a more expressive language for composition: loops, conditionals, variable reuse, and error handling are all natural. JSON tool schemas can only express one flat call at a time, forcing multi-step work into many round-trips.
What is Code Mode in the context of MCP?
Code Mode is a pattern (popularized by Cloudflare) where an MCP server exposes a typed SDK and two meta-tools — search() and execute() — instead of hundreds of individual tool schemas. The agent writes JavaScript or TypeScript against the SDK and runs it in a secure sandbox. Cloudflare reports this reduces the token footprint of a 2,500-endpoint API from over 1 million tokens to roughly 1,000.
How many tools is 'too many' for a traditional tool-calling agent?
Research suggests performance degrades noticeably past 20 tools and collapses at 100+. With ~50 tools, frontier models maintain 84-95% accuracy; with ~200, accuracy falls to 41-83%; at 740+, near-zero accuracy has been documented for most models. The exact threshold depends on model size and the similarity of tool descriptions.
Can I use code execution with any LLM provider?
Yes, though the implementation varies. OpenAI's Agents SDK includes a CodeInterpreterTool backed by a sandboxed Python environment. Anthropic's engineering documentation describes a code-execution-with-MCP pattern. Hugging Face's smolagents library supports any model via its API. The key requirement is a model that generates reliable, runnable code — modern frontier models all qualify.
What about auditability? How do I know what the agent actually did?
Code execution produces a plain-text program as the agent's action, which is fully auditable before or after the fact. You can log every generated program to a store and replay it. For operations that need structured audit trails at the individual-call level (regulated finance, healthcare), dedicated tools with schema-validated inputs may still be preferable, or you can enforce structured logging inside the sandbox.