In plain English
When you run a vector search, you ask the index for the k nearest items to a query — say the 10 closest embeddings. There are two different questions you can ask about the results. Recall asks: of the items that truly belong in the top 10, how many did the index actually return? Precision asks: of the 10 items the index returned, how many are actually relevant to what the user wanted? They sound similar but they measure opposite kinds of mistakes.
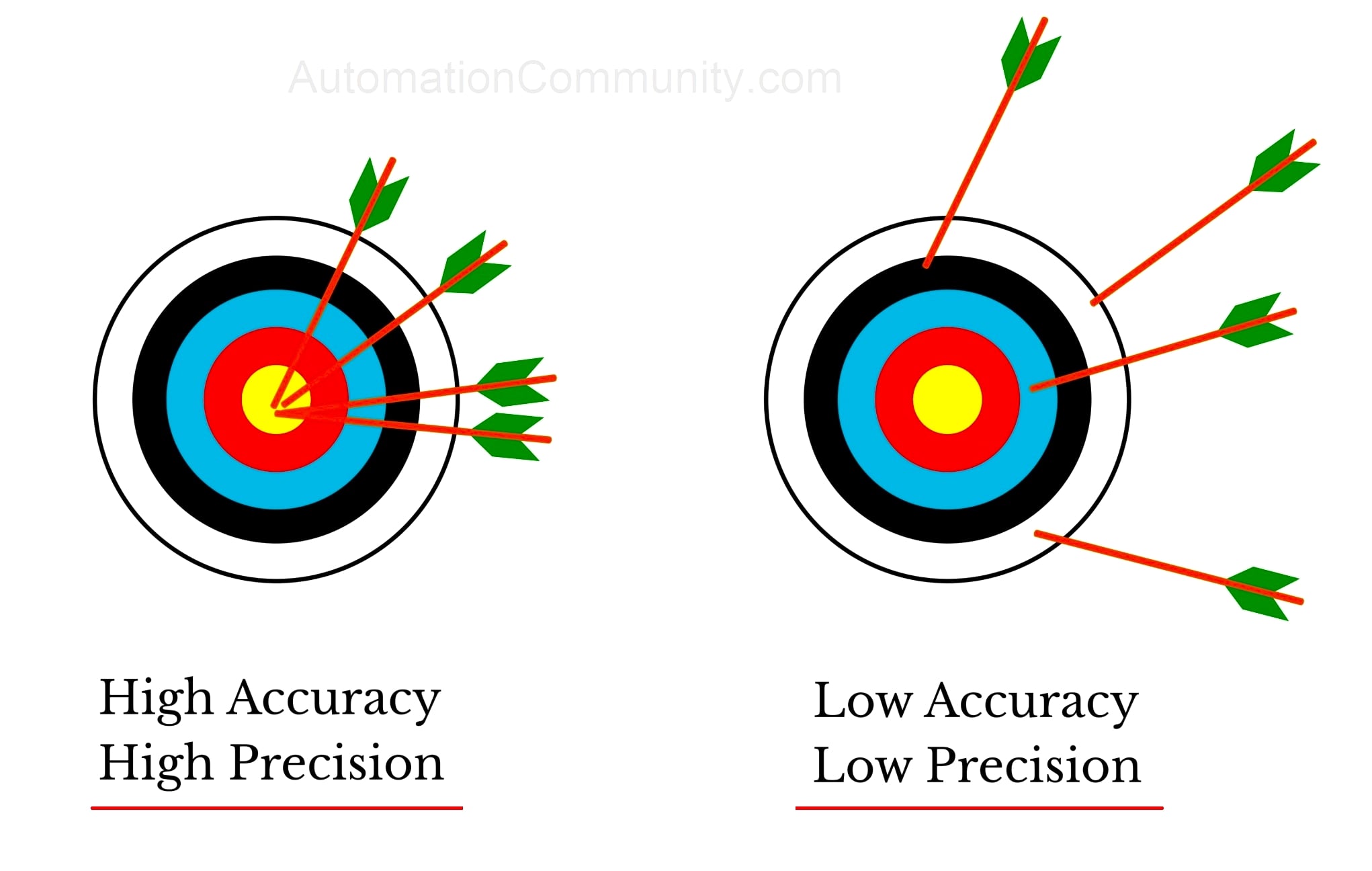
Here is the everyday analogy. Imagine a librarian fetching books for you. Recall is whether they found all the books that match your request — miss two and recall drops, no matter how good the ones they brought are. Precision is whether the books they handed you are actually about your topic — bring ten books but three are off-topic and precision drops, even if every relevant book made it onto the cart. A perfect librarian scores high on both, but in the real world you usually trade one against the other.
Why it matters
Every article about approximate nearest neighbor search tells you there is a recall-versus-speed tradeoff. Almost none of them tell you how to measure it. So teams ship an index with default settings, the search feels "mostly fine," and nobody notices that 1 in 5 correct results is silently missing. The whole point of these metrics is to turn that vague feeling into a number you can tune against.
Why a builder should care, concretely:
- You can't tune what you can't measure. Index parameters like HNSW's
efor IVF'snprobedirectly trade recall for latency. Without a recall number you are guessing — turn a knob, hope search feels better, ship it. - "Approximate" means it skips things on purpose. An ANN index is fast because it doesn't check every vector. That speed is paid for in missed neighbors. Recall@k tells you exactly how much you're missing.
- Bad retrieval poisons everything downstream. If you feed search results into a RAG pipeline or a recommender, a missing-but-correct chunk can never be reasoned about. The model isn't wrong — the retriever never gave it the right document.
- Recall and precision fail differently. Low recall is usually an index problem (tune the index). Low precision is usually an embedding or data problem (better model, better chunking, reranking). Measuring both tells you which lever to pull.
How it works
To measure recall you need a ground truth: the correct answer you compare your index against. For an ANN index the ground truth is wonderfully concrete — it's whatever exact (brute-force) search returns. Exact search compares the query to every vector and keeps the true top-k. It's slow, but for evaluation you only run it once on a sample, so slowness is fine.
Step 1 — build a ground-truth set
Take a representative sample of queries (a few hundred to a few thousand real or realistic queries). For each one, run exact nearest-neighbor search over your full dataset to get the true top-k neighbors. Save those. This is your answer key. You compute it once and reuse it every time you re-tune the index.
Step 2 — run the same queries through your real index
Now run the identical queries through your fast ANN index. For each query you get the index's top-k. Recall@k for one query is simply: of the k true neighbors, how many appear in the index's k results? Average that fraction across all queries and you have your index's recall@k — usually reported as a number like 0.95, meaning the index recovers 95% of the true neighbors on average.
Notice what recall@k here does not measure: whether the neighbors are good. If your embeddings are weak, exact search returns mediocre neighbors and a recall@k of 1.0 just means your index faithfully reproduced those mediocre results. Recall@k against exact search measures index fidelity — agreement with brute force — not real-world relevance.
Step 3 — measure precision the way users feel it
Precision needs a human judgment of relevance, not just agreement with brute force. You take the results actually shown to a user and label which ones are genuinely relevant. Precision@k = relevant results ÷ k. If 7 of the top 10 are on-target, precision@10 is 0.7. This is the metric your users actually experience, and it depends mostly on your embedding model and data quality, not your index parameters.
- Found all the true neighbors?
- Ground truth = exact search
- Measures the INDEX
- Fix with ef / nprobe / index choice
- Cheap to compute automatically
- Are the returned items relevant?
- Ground truth = human labels
- Measures EMBEDDINGS + data
- Fix with better model / reranking
- Needs relevance judgments
A worked example
Concrete numbers make this click. You're searching a catalog and you want the top 5 neighbors (k=5) for a query. Exact brute-force search gives you the answer key — the true top 5 by cosine similarity. Your fast HNSW index returns its own top 5. Compare them:
| Rank | Exact (truth) | ANN index | Hit? |
|---|---|---|---|
| 1 | doc_A | doc_A | yes |
| 2 | doc_B | doc_C | yes (B/C swapped) |
| 3 | doc_C | doc_B | yes |
| 4 | doc_D | doc_D | yes |
| 5 | doc_E | doc_Z | no — E missing |
The index returned 4 of the 5 true neighbors (A, B, C, D); it missed E and substituted an outsider, Z. So recall@5 = 4/5 = 0.80 for this query. Note that the B/C reordering does not hurt recall — recall@k counts membership in the top-k as a set, not the exact order. Average this 0.80 across all your sample queries to get the index's overall recall@5.
Now suppose a human looks at the index's 5 results and judges that doc_A, doc_C, doc_B, and doc_D are genuinely relevant but doc_Z is off-topic. That's 4 relevant out of 5 shown, so precision@5 = 0.80 too — but for a completely different reason. Recall dropped because the index skipped a true neighbor; precision dropped because one returned item wasn't relevant. Same score, different disease.
import numpy as np
def recall_at_k(truth_ids, ann_ids, k):
"""Average recall@k over many queries.
truth_ids[i] = exact top-k neighbor IDs for query i.
ann_ids[i] = ANN index's top-k IDs for query i."""
scores = []
for truth, ann in zip(truth_ids, ann_ids):
true_set = set(truth[:k])
got = len(true_set & set(ann[:k]))
scores.append(got / k) # set overlap, order ignored
return float(np.mean(scores))
# Ground truth comes from exact (brute-force) search, computed once:
# sims = corpus @ query # cosine if vectors are normalized
# truth = np.argsort(sims)[::-1][:k]
print(recall_at_k(truth_ids, ann_ids, k=10)) # e.g. 0.96Reading the recall-vs-latency curve
The reason recall matters at all is that you can buy it with time. ANN indexes expose a knob that controls how hard they search: in HNSW it's ef (or efSearch) — how many candidates to explore; in IVF-style indexes it's nprobe — how many partitions to scan. Turn the knob up and the index inspects more vectors: recall climbs toward 1.0, but each query gets slower. Turn it down and queries fly, but recall sags.
The right way to tune is to sweep the knob across several values and plot recall@k on one axis against query latency (or queries-per-second) on the other. You get a curve. The shape is the whole story: at first recall rises steeply for a tiny latency cost (cheap wins), then it flattens into diminishing returns where you're paying a lot of milliseconds for the last fraction of a percent.
| ef (HNSW) | Recall@10 | p95 latency | Read this as |
|---|---|---|---|
| 32 | 0.86 | 1.2 ms | fast but lossy |
| 64 | 0.94 | 1.9 ms | cheap win — recall jumps |
| 128 | 0.98 | 3.4 ms | good sweet spot for many apps |
| 256 | 0.99 | 6.1 ms | diminishing returns begin |
| 512 | 0.995 | 11.0 ms | paying a lot for +0.5% |
The numbers above are illustrative — your curve depends on your data, dimensions, and hardware, which is exactly why you must measure your own. But the shape is universal: find the elbow where the curve bends flat, and pick the lowest knob value that clears your recall target. In this example, if you need recall ≥ 0.95 at the lowest latency, ef=128 is the answer; going to 512 nearly triples latency to recover half a percent almost nobody will notice.
Common pitfalls
- Confusing index recall with relevance. Recall@k against exact search only proves your index matches brute force. If brute force returns junk (weak embeddings), high recall just faithfully reproduces junk. Validate relevance separately with precision and human labels.
- A stale or wrong ground truth. Your exact-search answer key must use the same dataset, the same distance metric, and the same embeddings as the live index. Re-embed your corpus or switch from cosine to dot-product and the old answer key is invalid — recompute it.
- Too few or unrepresentative queries. Twenty hand-picked queries don't reflect real traffic. Use a few hundred to a few thousand realistic queries so the average recall is stable and not dominated by a handful of easy ones.
- Measuring recall at the wrong k. Recall@10 and recall@100 can look very different. Measure at the k you actually serve. If your app shows 5 results, recall@5 is the number that matters, not recall@100.
- Reporting only the average. A mean recall of 0.95 can hide a tail of queries at 0.5. Look at the distribution — the worst 5% of queries are often where users feel the pain.
- Forgetting precision entirely. Teams obsess over index recall and never ask whether results are relevant. A perfectly tuned index over bad embeddings still disappoints users.
Going deeper
Once the basics click, a few refinements separate a toy benchmark from a trustworthy one.
Rank-aware metrics. Recall@k ignores order; sometimes order is the product. nDCG (normalized discounted cumulative gain) rewards putting relevant items near the top and discounts ones lower down. MRR (mean reciprocal rank) focuses on where the first relevant result lands — ideal when users mostly want one good answer. Use recall@k to gate the index, then nDCG or MRR to judge the ranking your users see.
Two ground truths, two layers. It's worth holding the distinction firmly: index quality is recall against exact search and is fixed by tuning the index; retrieval quality is precision/nDCG against human relevance labels and is fixed by better embeddings, better chunking, or a reranking step. Diagnose which layer is failing before you spend effort — tuning ef won't help a relevance problem, and a fancier model won't help an index that's silently dropping neighbors.
The build-time vs search-time tradeoff. ef/nprobe are search-time knobs you can change live. But index construction parameters (HNSW's M and efConstruction, IVF's number of partitions) also cap how high recall can climb. If your recall-latency curve plateaus below your target no matter how high you push ef, the ceiling is baked into how the index was built — rebuild with stronger construction settings.
Automate it as a regression test. Save your ground-truth set and run recall@k in CI. Then any change — a new embedding model, an index upgrade, a re-chunking — gets a before/after recall number instead of a vibe. This is how you avoid the classic silent regression where retrieval quietly degrades over months and nobody notices until users complain.
Where to go next. Understand the index you're measuring — approximate nearest neighbor search and HNSW explain why recall is less than 1.0 in the first place, and semantic search covers the relevance side that precision measures. The durable lesson: an ANN benchmark without a measured recall number is just a hope, and a recall number without a relevance check is only half the picture.
FAQ
What is recall@k in vector search?
Recall@k measures how many of the true top-k nearest neighbors your fast (approximate) index actually returned, compared to a slow exact brute-force search that you treat as the correct answer. A recall@10 of 0.95 means the index recovered 95% of the true top-10 neighbors on average. It's computed as a set overlap, so result order doesn't affect it.
What is the difference between recall and precision in vector search?
Recall asks whether the index found all the items it should have (measured against exact search — an index property). Precision asks whether the items it did return are genuinely relevant (measured against human judgment — an embeddings-and-data property). Low recall is usually fixed by tuning the index; low precision is usually fixed by better embeddings, chunking, or reranking.
How do I benchmark the recall of an ANN index?
Take a representative sample of a few hundred to a few thousand queries. For each, run exact brute-force search to get the true top-k — this is your answer key. Then run the same queries through your real ANN index, and for each query compute how many of the true top-k it returned, divided by k. Average across all queries to get recall@k.
What is a good recall value for vector search?
It depends on the product, but recall@k of 0.95 or higher is excellent for most production retrieval, and 0.98–0.99 is reserved for accuracy-critical applications. Don't chase 1.0 — the whole point of an approximate index is to avoid paying for exact search, so pick the lowest index setting that clears your target.
Does higher recall mean slower search?
Usually yes. ANN indexes expose a knob — HNSW's ef or IVF's nprobe — that controls how many candidates are explored. Raising it inspects more vectors, so recall climbs but each query gets slower. The standard practice is to sweep the knob and plot recall against latency, then pick the value at the curve's elbow that meets your recall target at the lowest cost.
Why is my recall@k high but search results still feel bad?
Because recall@k against exact search only proves your index matches brute force — it says nothing about relevance. If your embeddings are weak, exact search itself returns mediocre neighbors, and a perfect recall just faithfully reproduces them. Measure precision with human relevance labels to catch this; the fix is usually a better embedding model, better chunking, or a reranking step.