In plain English
When you train a LoRA adapter, two numbers dominate everything else on the config sheet: rank (r) and alpha (lora_alpha). Most tutorials tell you to set r=16, alpha=32 and move on. That works — until it doesn't. Understanding what those numbers actually do lets you fix a failing run instead of guessing.
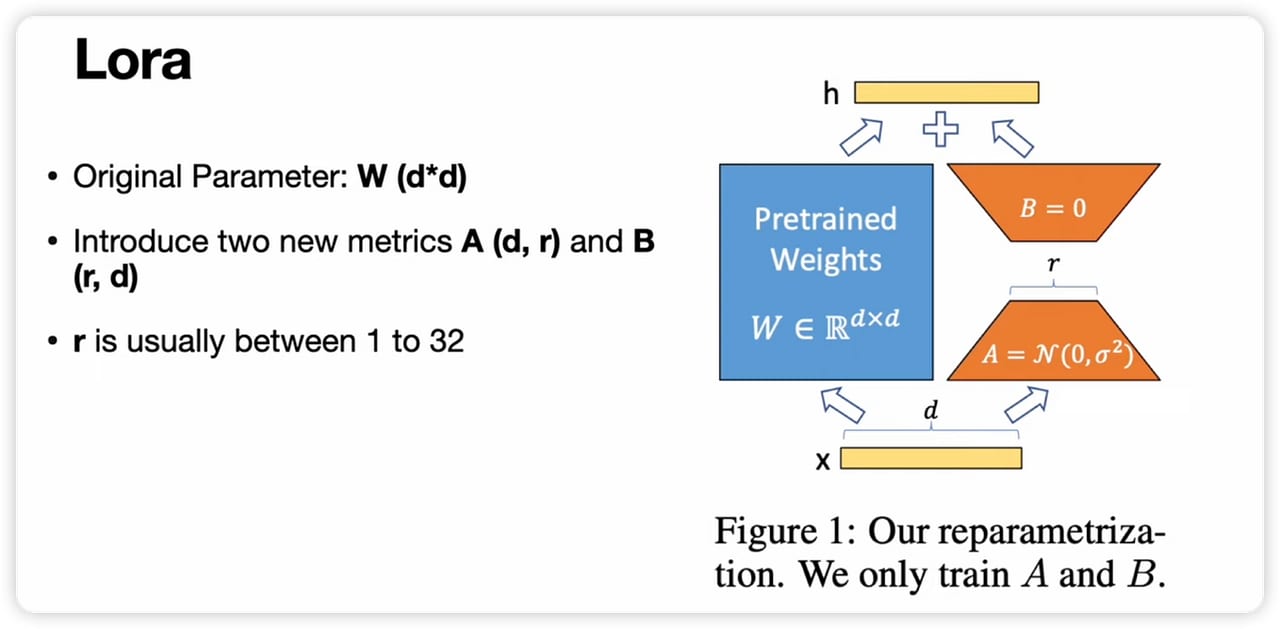
Rank is the width of the bottleneck LoRA inserts into each weight matrix. Recall how LoRA works: instead of updating a full d_in × d_out weight matrix directly, it trains two thin matrices — one d_in × r and one r × d_out — and adds their product to the frozen original. The number r is that inner dimension. A rank of 8 means each adapter pair contains (d_in + d_out) × 8 trainable numbers. A rank of 64 contains eight times as many. More rank means more capacity to represent change, but also more parameters and more VRAM.
Alpha is a scaling constant. Every time LoRA applies its adapter, it multiplies the output by alpha / r before adding it to the frozen layer's result. That ratio is the effective strength of the adapter. Think of rank as the size of the adapter and alpha as the volume knob on top.
The two controls are related but independent. Rank sets the parameter budget; alpha scales how loudly that budget speaks into the forward pass. Most confusion around these hyperparameters comes from treating them as one thing when they are really two levers with different jobs.
Why it matters
Cargo-culting r=16, alpha=32 will get you a functional adapter most of the time. But there are two classes of problems you cannot solve without knowing what rank and alpha actually do.
The underfitting problem
If your adapter trains correctly but the model still fails at your task — it can't follow the output format, it reverts to generic responses, it misses domain vocabulary — rank is usually the culprit. The adapter simply doesn't have enough capacity to represent the change you're asking for. Bumping rank from 8 to 32 or 64 often closes the gap without any other change.
The overfitting and instability problem
Conversely, if training loss drops rapidly but evaluation quality collapses, or the model loses general abilities it had before fine-tuning, rank may be too high relative to your dataset size, or alpha is too large. An oversized adapter can memorize training examples instead of generalizing, or it can overwrite base-model behavior that you actually wanted to keep.
Memory is linear in rank
Every doubling of rank roughly doubles the trainable parameters and adds proportional GPU memory. For a 7B-parameter model, r=8 produces about 4.2 million trainable LoRA parameters and uses roughly 14.2 GB of VRAM during training. Jumping to r=256 raises trainable parameters to about 20 million — only a 5x increase — but adds around 2.4 GB of VRAM on top. The memory cost of rank is real but surprisingly modest compared to the base model footprint; it rarely drives GPU OOM on its own. The bigger practical cost of high rank is overfitting on small datasets.
How it works
Concretely, LoRA replaces a weight update ΔW with the product of two matrices: ΔW = B × A, where A has shape r × d_in and B has shape d_out × r. During the forward pass, the full computation is:
output = W_frozen(x) + (alpha / r) * B(A(x))W_frozen never receives a gradient — it is frozen throughout training. Only A and B are updated. The term (alpha / r) is applied as a constant multiplier every forward pass. At inference time this scaling is typically folded directly into B (or A) so there is zero runtime overhead.
What rank actually controls
Mathematically, the product B × A can represent at most r independent directions of change in the weight space — that is the definition of rank. If the adaptation your task needs can be captured in 4 directions, r=4 is plenty and anything higher wastes parameters. If the task is complex — a large domain shift, multi-task behavior, or teaching a new code dialect — you need more directions, so higher rank. This is why the original LoRA paper showed that for most language tasks, ranks as low as 4 or 8 already capture most of the adaptation signal.
What alpha actually controls
Alpha behaves mathematically like a learning rate multiplier for the adapter. The LoRA paper itself notes that tuning alpha is roughly equivalent to tuning the learning rate when the initialization is fixed. In practice: if alpha / r = 1, the adapter contributes at "natural" scale. If alpha / r = 2, the update is applied twice as strongly. If alpha / r = 0.5, it is applied at half strength. The ratio — not the absolute value of alpha — is what matters.
Parameter count formula
For a single linear layer of shape d_in × d_out, the LoRA adapter adds exactly (d_in + d_out) × r trainable parameters. For a 768-dimensional attention layer, that is (768 + 768) × r = 1536r parameters per targeted matrix. A typical transformer has many such matrices, so the total LoRA parameter count scales as (sum of targeted layer dimensions) × r. This is why applying LoRA to all linear layers (attention projections plus MLP blocks) produces notably better results than attention-only targeting — more matrices, more coverage.
Choosing rank and alpha in practice
There is no single right answer, but there are well-tested starting points and a clear escalation ladder.
| Task type | Recommended rank | Alpha (ratio) | Notes |
|---|---|---|---|
| Style / tone / format only | 4–8 | alpha = r (ratio 1) | Smallest footprint; rarely overfits |
| Standard NLP fine-tune (chat, classification, summarization) | 16–32 | alpha = r or 2r | Safe default for most projects |
| Complex domain shift, new code dialect | 64–128 | alpha = r | Higher capacity; watch for overfitting |
| Near-full-fine-tuning parity on large dataset | 128–256 | alpha = r or r/2 | Diminishing returns past 256; consider rsLoRA |
The starting-point recipe
- Start at r=16, alpha=16 (ratio 1). This is a neutral baseline: enough capacity for most tasks, ratio 1 keeps the adapter at natural strength.
- If the model underfits (training loss stalls high, outputs are still too generic): double the rank. Try r=32, then r=64.
- If the model overfits (training loss drops fast, eval degrades): decrease rank, or lower alpha — try alpha = r/2 to reduce the adapter's influence.
- If you change your learning rate significantly, revisit alpha. They interact: a higher LR with a high alpha/r ratio can destabilize training.
rsLoRA: a better scaling law
Standard LoRA scales the update by alpha / r. A 2024 paper introduced rsLoRA (rank-stabilized LoRA), which scales by alpha / sqrt(r) instead. The argument is that as rank grows, the standard scaling causes the effective update strength to shrink too fast, starving higher-rank adapters of gradient signal. With rsLoRA, higher ranks converge faster and can outperform the same rank under standard scaling. Most modern fine-tuning frameworks (Unsloth, PEFT, Axolotl) support rsLoRA via a single flag (use_rslora=True).
Common pitfalls and misconceptions
Pitfall 1: Treating alpha as just another rank
Alpha is not a second rank. It does not change the number of trainable parameters or the structural capacity of the adapter. Doubling alpha while keeping rank fixed produces the same gradient flow through A and B — it only scales the contribution of the result to the forward pass. Beginners sometimes try to compensate for low rank by cranking alpha; that just makes the small adapter louder, not smarter.
Pitfall 2: Ignoring which layers are targeted
Rank and alpha only matter for the layers you actually attach LoRA to. Research (including the QLoRA paper) has consistently shown that applying LoRA to all linear layers — attention projections (q_proj, k_proj, v_proj, o_proj) plus MLP layers (gate_proj, up_proj, down_proj) — is necessary to approach full fine-tuning performance. A rank of 64 on only the query and value projections will underperform a rank of 16 applied everywhere.
Pitfall 3: Not adjusting learning rate when changing rank
Because alpha / r acts like a learning rate multiplier, changing rank while keeping the same learning rate shifts the effective optimization dynamics. Recent research suggests the optimal LoRA learning rate scales roughly with r^-0.84 — meaning if you double the rank, you should reduce the learning rate slightly (not by half, but noticeably). In practice, re-running a quick LR sweep when you significantly change rank saves you from a confusing result where higher rank performed worse.
Pitfall 4: The QLoRA rank finding
The QLoRA paper famously found "very little statistical difference between ranks of 8 and 256" on the tasks they tested. This is often quoted as proof that rank doesn't matter — but it specifically means that once you hit some minimum threshold, further increases don't help for that task on that dataset. For narrower domain tasks with more complex output formats, rank absolutely matters. Do not take this finding as blanket permission to stay at r=8.
Going deeper
DoRA and dynamic rank
DoRA (Weight-Decomposed Low-Rank Adaptation, 2024) decomposes each weight matrix into its magnitude and direction components, applying LoRA only to the directional part. This consistently outperforms standard LoRA at the same rank on several benchmarks and is available in Unsloth and recent PEFT builds. It costs slightly more memory than vanilla LoRA but less than increasing rank by 2x.
Rank search without full sweeps
Full hyperparameter sweeps over rank are expensive. A practical shortcut: train one run at high rank (e.g., r=128) and then analyze the singular values of the trained B × A matrices. If most of the information is concentrated in the top few singular values and the rest are near zero, your task only needed low effective rank — future runs at r=8 or r=16 will likely match quality while saving memory. This post-hoc rank analysis is supported in some research toolkits and is the approach behind adaptive-rank methods like AdaLoRA.
AdaLoRA: letting the model pick its own rank
AdaLoRA starts with a high rank budget and continuously prunes singular values during training, allocating more rank to the layers that need it and less to the layers that don't. The result is a non-uniform rank assignment that often beats a fixed rank of equivalent average size. If you have the framework support, AdaLoRA is worth experimenting with on tasks where you genuinely do not know how to distribute rank across layers.
The alpha scaling trick for post-training adjustment
One underused property of alpha: because it is a constant multiplier, you can effectively re-tune the adapter's strength after training by loading the weights and changing the alpha value in the config. If your fine-tuned model sounds too "loud" (over-adapted, loses general ability), halving alpha — a config-file change, no retraining — can recover a more balanced behavior. Unsloth documents this explicitly: if training loss dropped below 0.2 and the model seems over-trained, multiply alpha by 0.5 at inference time as a first diagnostic step.
When rank stops mattering: LoRA vs full fine-tuning
At very high ranks (approaching the hidden dimension), LoRA and full fine-tuning converge in both quality and memory cost. A 2024 paper ("LoRA vs Full Fine-Tuning: An Illusion of Equivalence") showed that even at high rank, LoRA and full fine-tuning learn different representations — LoRA keeps the original weight structure more intact, which means better regularization on small datasets but potentially a ceiling on how much the model can shift for very large domain changes. If you have a large high-quality dataset and need maximum quality, full fine-tuning is still the ceiling; LoRA at any rank is a practical approximation to it.
FAQ
What happens if I set alpha higher than rank?
The alpha / r ratio exceeds 1, so the adapter's contribution is amplified beyond "natural" scale. This is not inherently wrong — r=8, alpha=16 (ratio 2) is a common and effective setting. But very high ratios (e.g., r=8, alpha=128) risk making the adapter dominate the base model and destabilizing training. Keep the ratio between 0.5 and 2 unless you have a specific reason to go outside that range.
Should I always set alpha = 2 * rank?
It is a reasonable default, but not a law. The original LoRA paper used alpha = 2r, and many practitioners find that alpha = r (ratio 1) is equally stable and easier to reason about. The QLoRA paper even used alpha = r / 2 successfully. What matters is the ratio, and the right ratio depends on your task and learning rate. Start with ratio 1 or 2, then adjust based on observed training dynamics.
Does increasing rank always improve quality?
Not past a certain point. Research consistently shows diminishing returns — and often quality degradation — when rank grows beyond what the task needs. The QLoRA paper found negligible difference between rank 8 and rank 256 for instruction-following. The risk of overfitting grows with rank on small datasets. Start small and increase only when you have evidence of underfitting.
What is rsLoRA and do I need it?
rsLoRA (rank-stabilized LoRA) scales the adapter output by alpha / sqrt(r) instead of alpha / r. This prevents the effective update from shrinking too fast at high ranks, giving higher-rank adapters more usable gradient signal. It is most relevant when you are using rank above 64. Enable it with use_rslora=True in PEFT or Unsloth — it costs nothing and often improves convergence at high rank.
How many trainable parameters does a rank-16 LoRA adapter add?
It depends on which layers you target and the model's hidden dimension. For a 7B model with hidden dim 4096, a single attention projection (q_proj) adds (4096 + 4096) × 16 = 131,072 parameters. A typical full-model LoRA targeting all linear layers at r=16 adds on the order of 10 to 40 million trainable parameters out of 7 billion total — roughly 0.1% to 0.5%.
Can I change alpha after training without retraining?
Yes. Alpha is a config-time scalar that multiplies the adapter output; the trained matrices A and B are unchanged. You can load the trained adapter and set a different lora_alpha in the config to adjust how strongly it influences the base model. This is a free diagnostic step: if the adapter feels too dominant (model lost general abilities), halve alpha at inference and see if quality improves before deciding whether to retrain.