In plain English
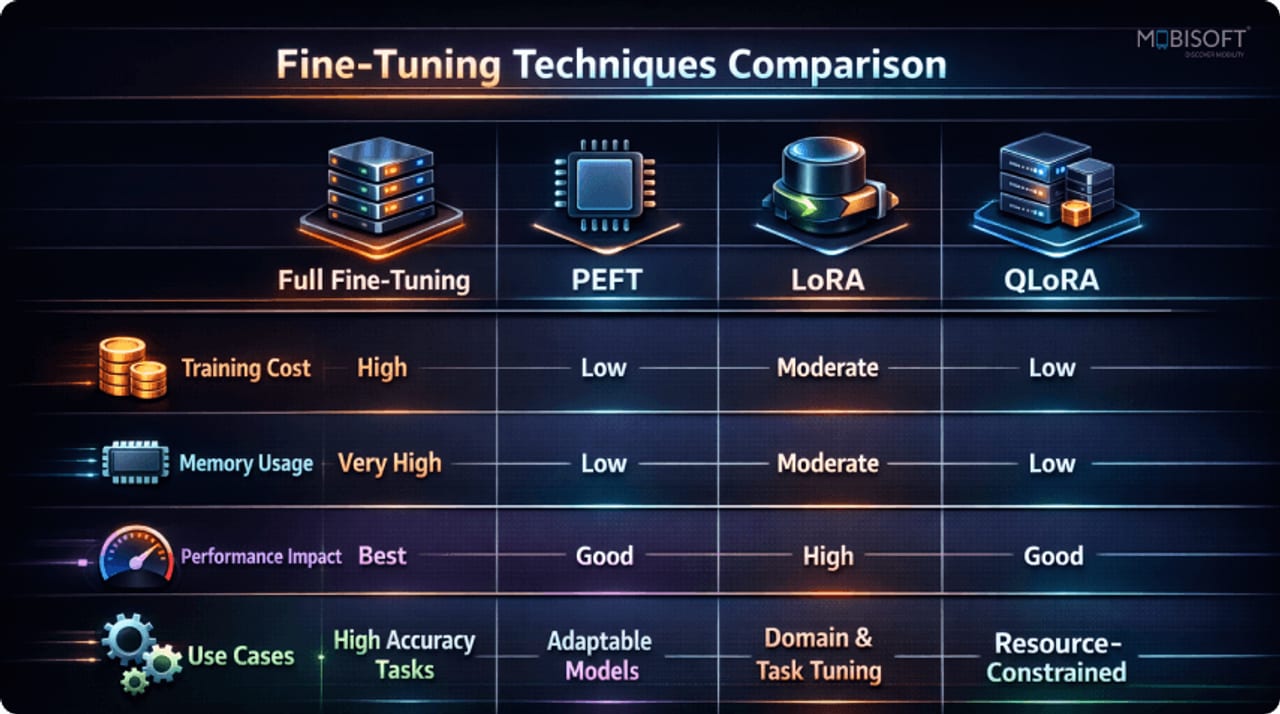
When you fine-tune a model, you have a fundamental choice: update every number in the model, or update just a tiny slice of new numbers while leaving the original model frozen. The first option is full fine-tuning; the second family of approaches is called parameter-efficient fine-tuning (PEFT).
Imagine you hired a multilingual translator who already speaks 20 languages. Full fine-tuning is like sending that person back to school for a year to absorb an entirely new specialty — they come back transformed, but it cost you a lot of time and money, and you have to house a whole new person if you want multiple specialties. PEFT is more like handing that same translator a pocket reference card for your niche legal vocabulary. They clip it to their belt, glance at it when needed, and become your legal specialist almost immediately — and if you also need a medical specialist, you just print a different card. The translator's core training is never touched.
The "pocket reference card" in the PEFT analogy is called an adapter — a small set of extra weights trained on top of a frozen base model. The most widely used method for building these adapters is LoRA (Low-Rank Adaptation). Other PEFT methods include prefix tuning, prompt tuning, and adapter layers, but LoRA has become the practical default for large language models.
Why it matters
The choice between full fine-tuning and PEFT is not primarily an accuracy question — it is a resource question. For most tasks, PEFT methods match or come close to full fine-tuning quality. But their memory and cost profiles are completely different, and for most teams that difference decides what is even possible.
Consider a 7-billion-parameter model. Full fine-tuning in FP16 precision requires roughly 70 GB of GPU VRAM once you account for the model weights, gradients, and optimizer states. That means multiple high-end data-center GPUs — thousands of dollars of cloud compute for a single fine-tuning run. With QLoRA (the most memory-efficient PEFT variant), the same 7B model fits in 12 GB of VRAM — a single consumer RTX 4090. The math changes the entire economics of who can fine-tune what.
Beyond memory, the PEFT approach changes how you manage model versions. Full fine-tuning produces a new full-size copy of the model for every task — a 7B model at FP16 is around 14 GB on disk, so ten task-specific variants cost 140 GB of storage. A LoRA adapter typically weighs a few hundred megabytes or less, so you keep one shared base model and swap adapters, the same way you swap a lens on a camera.
How each approach works
In full fine-tuning, every weight in the model is marked as trainable. On each training step, gradients flow back through all layers and every number is updated. The model that emerges is a completely independent copy — no relationship to the base model at inference time, no adapter to attach. It is the most direct method and imposes no constraints on which parts of the model can change.
LoRA takes a different path. The core insight is that the update needed to specialize a model tends to be low-rank — it can be represented as the product of two much smaller matrices rather than a full-sized one. Formally, for a weight matrix W of dimension d x k, LoRA replaces the update delta-W with the product of two small matrices A (d x r) and B (r x k), where the rank r is a small number like 8 or 16. Instead of updating d x k parameters, you only update r x (d + k) — often less than 1% of the original count. The base weights stay frozen; only A and B are trained.
- All weights updated
- Gradients through entire model
- Optimizer states for every param
- Produces a new full model copy
- 70 GB+ VRAM for a 7B model
- Highest possible quality ceiling
- Base weights frozen
- Only adapter matrices trained
- Optimizer states for ~1% of params
- Produces a small adapter file
- 12 GB VRAM for a 7B model (QLoRA)
- 90-95% of full fine-tuning quality
At inference time, the LoRA adapter weights can be merged back into the base model — mathematically equivalent to just adding delta-W to W. After merging, there is zero additional latency; it runs exactly like a regular model. Alternatively you can keep the adapter separate and hot-swap it, which is useful when you run many task-specific variants on one shared base.
Other PEFT methods
LoRA is not the only approach. The Hugging Face peft library ships several techniques with different tradeoff profiles.
| Method | What it trains | Best for |
|---|---|---|
| LoRA | Low-rank matrices injected into attention/MLP layers | General-purpose — the standard default for LLMs |
| QLoRA | Same as LoRA but the base model is stored in 4-bit | Maximum memory savings on consumer GPUs |
| DoRA | Decomposes weights into magnitude + direction; applies LoRA to direction | Slightly higher quality than LoRA on many tasks |
| AdaLoRA | Like LoRA but rank is allocated dynamically based on importance | When you want to use a fixed parameter budget most efficiently |
| IA3 | Scales activations via learned vectors — very few parameters | Extreme efficiency; fewer parameters than LoRA |
| Prefix Tuning | Prepends trainable tokens to keys and values in every layer | Natural language tasks; works without touching architecture |
Memory and cost at a glance
Numbers tell the story more clearly than words. The table below uses widely cited estimates for fine-tuning a 7B-parameter model in typical conditions. Exact figures vary by model architecture, batch size, and sequence length, but the order-of-magnitude differences are stable across configurations.
| Approach | Trainable params | VRAM (7B model) | Disk (per task) |
|---|---|---|---|
| Full fine-tuning (FP16) | ~7 billion (100%) | ~70 GB | ~14 GB |
| LoRA (r=16, FP16 base) | ~20–100 million (<1%) | ~28 GB | ~50–300 MB |
| QLoRA (4-bit base + LoRA) | ~20–100 million (<1%) | ~10–14 GB | ~50–300 MB |
The VRAM column is the most consequential number. A 70 GB requirement means you need multiple A100-class GPUs — typically a cloud instance costing $10–$30 per hour. A 12–14 GB requirement fits in a single RTX 4090 that costs around $1,500 to own or a few cents per hour to rent. For a 70B parameter model, the contrast is even starker: full fine-tuning can require over 1 TB of VRAM (eight or more A100 80 GB cards), while QLoRA brings that into a multi-GPU consumer setup.
A practical code snippet showing just how few parameters LoRA actually trains:
from transformers import AutoModelForCausalLM
from peft import LoraConfig, get_peft_model
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-3.1-8B")
lora_config = LoraConfig(
r=16, # rank — larger = more capacity, more memory
lora_alpha=32, # scaling factor; often set to 2*r
target_modules=["q_proj", "v_proj"], # which layers to attach adapters to
lora_dropout=0.05,
bias="none",
)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
# Output: trainable params: 6,815,744 || all params: 8,036,564,992
# trainable%: 0.08Less than 0.1% of parameters are trained — and you still get most of the quality gains you would from a full fine-tune.
Quality tradeoffs: when does PEFT fall short?
For many practical tasks, PEFT methods recover 90–95% of full fine-tuning quality at a fraction of the compute cost. For instruction-following, style transfer, output format locking, and narrow classification tasks, well-tuned LoRA is essentially indistinguishable from a full fine-tune in production.
But there are cases where full fine-tuning holds a meaningful edge. A 2024 paper titled LoRA vs Full Fine-tuning: An Illusion of Equivalence (arXiv:2410.21228) found that LoRA and full fine-tuning produce weight matrices with structurally different singular value decompositions — LoRA introduces high-rank "intruder dimensions" absent from full fine-tunes. This can matter for tasks that require deep reorganization of the model's internal representations, not just a surface-level behavioral shift.
In plain terms: PEFT is best at behavior adjustment; full fine-tuning is better at deep knowledge infusion. If you are teaching a model a new domain from scratch — say, a highly specialized medical coding system it has never encountered — full fine-tuning may generalize better. If you are teaching it to output in your JSON schema, adopt your brand voice, or follow your function-calling convention, LoRA is more than sufficient.
| Task type | Recommended approach | Reason |
|---|---|---|
| Style / tone / format | PEFT (LoRA) | Behavior adjustment; LoRA closes gap with full FT |
| Instruction following / chat fine-tune | PEFT (LoRA or QLoRA) | Well-tested default; reproducible results |
| Narrow classification or extraction | PEFT (LoRA) | High accuracy; massive efficiency win |
| New domain knowledge injection (large dataset) | Full fine-tuning | Deeper weight updates improve generalization |
| Multi-task fine-tuning (single merged model) | Full fine-tuning or merged LoRA | Avoids adapter switching overhead |
| Consumer GPU / low budget | QLoRA | Only viable option for large models |
Going deeper
Once you've chosen PEFT, the most important hyperparameter is rank (r). A higher rank gives the adapter more expressive capacity but uses more memory and risks overfitting. Typical starting values range from r=4 (very lightweight) to r=64 (close to full fine-tuning in expressiveness). For most instruction-following tasks, r=16 with lora_alpha=32 is a reliable starting point. AdaLoRA automates this by distributing rank budget dynamically across layers based on gradient importance, concentrating capacity where it matters most.
Target modules are the other key PEFT decision. LoRA can be applied to any linear layer in the transformer — attention projections (q_proj, k_proj, v_proj, o_proj), MLP layers (up_proj, gate_proj, down_proj), or all of the above. Attaching LoRA to all linear layers gives higher quality but increases adapter size and training cost. The q_proj + v_proj combination (from the original LoRA paper) is a well-tested minimal configuration.
DoRA (Weight-Decomposed Low-Rank Adaptation), introduced by NVIDIA researchers in February 2024 and presented at ICML 2024, refines LoRA by decomposing the weight matrix into magnitude and direction components, then applying LoRA only to the directional part. This mirrors how humans tend to think about learning — adjusting the direction of behavior while maintaining the scale — and consistently outperforms standard LoRA on downstream benchmarks at the same parameter count.
Adapter merging unlocks multi-task inference without switching overhead. Once you train separate LoRA adapters for task A, task B, and task C, you can merge them into the base weights using TIES-merging or DARE (both open-sourced in 2024) — techniques that average or prune adapter weights to produce a single combined model. The result degrades slightly versus individual adapters but can be worth the simplicity for production deployment.
The research frontier is narrowing the quality gap. Methods like rsLoRA (rank-stabilized LoRA, 2024) rescale adapter learning rates to allow stable training at higher ranks, recovering quality on harder tasks without extra memory. The overall trend: PEFT methods are continuously closing the gap with full fine-tuning while the memory advantages remain. Unless you specifically need deep knowledge injection or have infrastructure to spare, starting with QLoRA and graduating to standard LoRA (or full fine-tuning) only if quality benchmarks demand it is the pragmatic path.
FAQ
Does PEFT always give lower quality than full fine-tuning?
Not in practice for most tasks. LoRA typically recovers 90–95% of full fine-tuning quality, and for behavior-oriented tasks like instruction following, style matching, or output formatting the gap is often unmeasurable. Full fine-tuning holds an edge mainly for deep domain knowledge injection with large, rich datasets.
What is the LoRA rank parameter and how do I choose it?
The rank r controls how much expressive capacity the adapter has. A rank of 4–8 is very lightweight; 16–32 is a common production default; 64+ approaches the expressiveness of full fine-tuning. Start at r=16. Increase it only if you benchmark a quality gap, because higher ranks cost more memory and training time.
Can I merge a LoRA adapter back into the base model for deployment?
Yes. After training, calling model.merge_and_unload() in the Hugging Face PEFT library folds the adapter weights into the base model, producing a standard model with zero adapter overhead at inference. The merged model runs at the same speed as the original base.
Is QLoRA good enough for production, or does the 4-bit quantization hurt too much?
QLoRA is production-grade for most conversational, classification, and style tasks. Benchmarks show it recovers 80–90% of full fine-tuning quality. For precision-critical applications (medical coding, legal document analysis, safety-critical code generation) you should benchmark the quality delta explicitly before committing to QLoRA in production.
Do I need to run full fine-tuning to inject new domain knowledge?
For large-scale knowledge injection — training on hundreds of thousands of domain documents from scratch — full fine-tuning generalizes better because more weights are free to reorganize. For narrow domain adaptation (learning your company's terminology, a specific API's calling convention), LoRA with a focused dataset of a few thousand examples is usually sufficient.
How does PEFT affect inference latency compared to full fine-tuning?
If you merge the LoRA adapter into the base model before serving, latency is identical to a full fine-tune — the math is the same. If you keep the adapter separate and apply it at inference time, there is a small overhead, but it is typically negligible for real-world throughput. The main latency consideration is the base model's size, which is the same either way.