In plain English
Stable Diffusion is a family of open-weights text-to-image AI models. You type a description — "a red panda reading a newspaper in the rain" — and the model generates a photorealistic or artistic image from scratch. Released publicly on August 22, 2022 by Stability AI, it was the first serious text-to-image model that anyone could download, run on their own computer, and modify freely.
Think of it like the Linux of image generation. Before Stable Diffusion, tools like DALL·E were locked behind APIs — you submitted a prompt, a company's server responded with an image, and you had zero visibility into what happened in between. Stable Diffusion changed that. The weights (the trained numbers inside the neural network) were published on Hugging Face. Anyone could inspect them, fine-tune them on their own data, combine them, or build entirely new user interfaces on top of them.
The name comes from its underlying technique: latent diffusion. The model works in a compressed, lower-dimensional "latent space" rather than operating pixel-by-pixel, which is what makes it fast enough to run on a consumer GPU. The "stable" part is not a technical term — it was simply the company's branding, though the approach really did make diffusion-based generation feasible at home for the first time.
Why it matters
Before August 2022, high-quality AI image generation was effectively gated. DALL·E required an OpenAI account and billed per image. Midjourney lived inside a Discord server on Midjourney's terms. You could not self-host, you could not fine-tune on your own dataset, and you could not see how the model worked.
Stable Diffusion's open release unlocked three things at once that mattered enormously to builders:
- Local inference — a gamer's GPU from 2020 was suddenly enough to generate images in seconds, with no API key or internet connection required.
- Fine-tuning — developers could train the model on small datasets of a specific style, face, product, or brand, producing a specialized "checkpoint" that the original could never have produced.
- Community remixing — because the weights were public, thousands of modified versions (called checkpoints, LoRAs, and merges) appeared on sites like Civitai within months, covering every artistic style imaginable.
For product teams, the open ecosystem means you are not paying per-image API costs at scale, you are not sending proprietary visual data to a third party, and you can adapt the model to your own aesthetic requirements. For researchers, it means a reproducible, inspectable baseline. For artists, it means a tool they can modify and own.
How it works
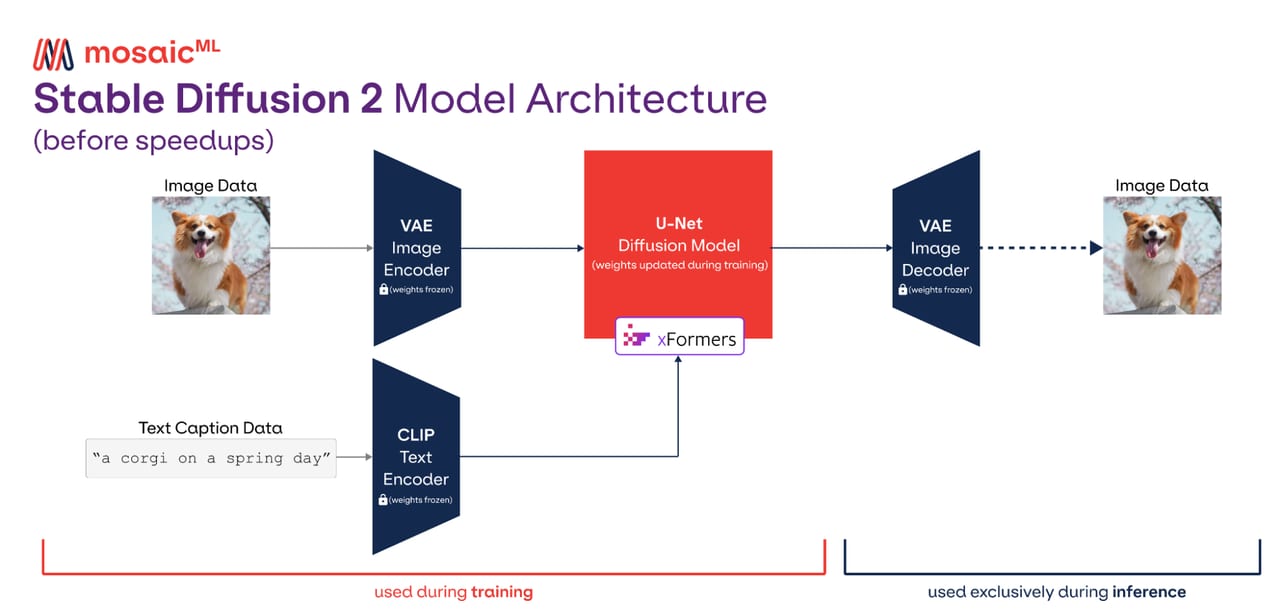
Stable Diffusion is a latent diffusion model — a diffusion model that operates in a compressed representation of an image rather than in full pixel space. This is the key architectural choice that made it fast enough to run locally. There are three major components working together:
The three components
- VAE (Variational Autoencoder) — compresses a 512×512 pixel image down to a 64×64 latent tensor (roughly 48× fewer numbers to process). The VAE encoder does this compression; its decoder reverses the process at the very end to produce the final pixels.
- U-Net — the workhorse. At each denoising step, it takes the current noisy latent, the timestep, and the text embedding, and predicts exactly what noise should be removed. Repeat this 20–50 times and the latent converges to a clean image.
- CLIP text encoder — converts your text prompt into a numerical embedding vector. This embedding is injected into every layer of the U-Net via cross-attention, guiding the denoising toward what you described.
Guidance scale and sampling
Two important knobs control every generation. The guidance scale (commonly called CFG scale) determines how closely the output follows your prompt versus exploring freely — higher values give more literal prompt adherence, lower values give more creative variation. The sampler (such as Euler, DPM++, or DDIM) controls the denoising algorithm used at each step; different samplers trade off speed, detail, and style.
Stable Diffusion was originally trained on the LAION-5B dataset — 5.85 billion image-text pairs scraped from the internet. This is why the model has broad general knowledge of visual styles but can also produce biases and artifacts inherited from that training data.
The model family: SD 1.5, SDXL, SD 3, and beyond
"Stable Diffusion" is not a single model — it is a family of successively improved architectures released over three years. Understanding which generation you are looking at is essential because checkpoints and LoRAs are not interchangeable between generations.
| Model | Released | Base resolution | Key upgrade | VRAM needed |
|---|---|---|---|---|
| SD 1.5 | Oct 2022 | 512×512 | Foundational open release; largest community checkpoint library | 4–6 GB |
| SD 2.1 | Dec 2022 | 768×768 | New CLIP variant; better at following prompts, smaller community | 4–6 GB |
| SDXL 1.0 | Jul 2023 | 1024×1024 | Dual-encoder, two-stage pipeline; photorealistic quality leap | 8 GB |
| SD 3.0 | Jun 2024 | 1024×1024 | Multimodal diffusion transformer; far better text rendering | 10–12 GB |
| SD 3.5 Large | Oct 2024 | 1024×1024 | 8B parameters; best prompt adherence in the family | 16–18 GB |
| SD 3.5 Medium | Oct 2024 | 1024×1024 | 2.6B parameters; consumer-hardware friendly | 6–8 GB |
SD 1.5 remains relevant in 2026 purely because of its ecosystem size. Civitai alone hosts tens of thousands of SD 1.5 checkpoints and LoRAs spanning every conceivable art style, which no newer architecture has replicated in volume. If you need a specific obscure style, SD 1.5 probably has a fine-tune for it.
SDXL became the community workhorse for photorealistic and commercial-grade work. Its dual text-encoder setup (two CLIP models in tandem) significantly improved understanding of complex prompts. Most professional-grade open image tools in 2024–2025 targeted SDXL first.
SD 3 and SD 3.5 moved to a completely new architecture called a Multimodal Diffusion Transformer (MMDiT), abandoning the U-Net entirely. This brought dramatically better text rendering inside images and compositional accuracy, at the cost of higher VRAM and a smaller community fine-tune library.
The ecosystem it spawned
Stable Diffusion's real impact is not the base model itself but the ecosystem that grew around it. By releasing weights publicly, Stability AI inadvertently created an open platform — every new tool, fine-tuning technique, and model variant plugged into the same format.
User interfaces
- AUTOMATIC1111 (A1111) — the original web UI, Gradio-based, form-driven. Still the entry point most tutorials reference. Over 1,500 community extensions cover everything from face restoration to image upscaling.
- ComfyUI — a node-based visual pipeline editor. Each step of the diffusion process is a node you wire together, which makes it the preferred tool for power users and automation workflows.
- Stable Diffusion WebUI Forge — a fork of A1111 optimised for lower VRAM usage and faster generation, popular on mid-range hardware.
Fine-tuning methods
- Checkpoint fine-tuning — train the entire (or most of the) model on a new dataset. Produces a standalone model file. Requires significant GPU-hours but yields the deepest style adaptation.
- LoRA (Low-Rank Adaptation) — adds small weight delta files (typically 10–200 MB) on top of any base checkpoint. A LoRA might capture a specific artist's style, a particular face, or a product design. Plug-and-play: one LoRA can be combined with any compatible base checkpoint at inference time.
- Textual Inversion / Embeddings — trains a new text token to represent a concept. Lightweight (a few KB) but limited in scope compared to LoRA.
- ControlNet — a conditioning extension that lets you guide the spatial layout of a generated image using depth maps, edge detections, pose skeletons, or reference images. Preserved layout + new style.
FLUX.1 — the 2024 successor
In August 2024, Black Forest Labs — founded by Robin Rombach and Andreas Blattmann, the original Stable Diffusion researchers from LMU Munich who later left Stability AI — released FLUX.1. FLUX uses a hybrid architecture of multimodal and parallel diffusion transformer blocks scaled to 12 billion parameters. In head-to-head benchmarks it outperformed SD 3 Ultra, Midjourney v6, and DALL·E 3. FLUX.1 [schnell] is Apache 2.0 licensed and freely downloadable from Hugging Face, making it a natural heir to the open-weights tradition Stable Diffusion established.
Going deeper
Once you are comfortable running inference, the next level is understanding img2img (using an existing image as a starting point rather than pure noise), inpainting (repainting a masked region of an image), and ControlNet conditioning. These three techniques together enable a workflow that is genuinely useful for professional production: you can sketch a rough composition, have the model refine it, repaint specific regions without touching others, and constrain the spatial layout using depth or pose information.
Sampling depth: what really controls quality
The two most overlooked parameters are the sampler and step count. Modern samplers like DPM++ 2M Karras can produce excellent results in 20–30 steps; DDIM typically needs 50 steps for comparable quality. Choosing a mismatched sampler for a checkpoint can produce muddy or over-saturated images even if every other setting is correct.
Training your own LoRA
Training a LoRA requires 10–30 curated images of your subject, a captioning step (often automated with BLIP-2 or WD14 tagger), and a training run of roughly 1,000–3,000 steps on a single GPU. Tools like kohya_ss and OneTrainer provide GUI wrappers around the accelerate-based training loop. A well-trained LoRA can reproduce a specific product, character, or style reliably across any base checkpoint it is compatible with.
Architectural trajectory: from U-Net to DiT
SD 1.5 through SDXL used a U-Net as their denoising backbone — a convolutional architecture with skip connections that processes spatial features at multiple scales. SD 3 and SD 3.5 replaced this with a Multimodal Diffusion Transformer (MMDiT), and FLUX.1 uses a related hybrid transformer design. Transformers scale more predictably with parameter count and handle long-range spatial relationships better, which is why newer architectures produce significantly better text rendering and compositional coherence. The trade-off is that transformers are less efficient at low parameter counts, which is why SD 1.5 still outperforms SD 3.5 Medium on simple tasks when VRAM is limited.
Running locally: a realistic hardware guide
| GPU VRAM | What you can run comfortably |
|---|---|
| 4 GB | SD 1.5 at 512×512 with careful settings |
| 6–8 GB | SD 1.5, SD 2.1, SDXL with attention optimization, SD 3.5 Medium |
| 12–16 GB | SDXL without compromise, FLUX.1 [schnell] quantized, SD 3.5 Large quantized |
| 24 GB+ | Any open model at full precision, including FLUX.1 [dev] at full quality |
FAQ
Is Stable Diffusion free to use commercially?
It depends on the version. SD 1.5 uses the CreativeML Open RAIL-M license, which permits commercial use with certain restrictions (no harmful use cases). SD 3.5 uses the Stability AI Community License, which is free for commercial use up to $1 million in annual revenue — above that threshold, a commercial license from Stability AI is required. Always check the specific model card for the version you are using.
What is the difference between a checkpoint and a LoRA?
A checkpoint is a complete model file — it contains all the trained weights needed to run inference. A LoRA is a small delta file (typically 10–200 MB) that modifies a base checkpoint by adding learned adjustments on top. You load a LoRA alongside a checkpoint at runtime; it cannot run standalone. Checkpoints define the overall quality and style; LoRAs inject specific concepts like a face, art style, or product design.
Do I need an internet connection to run Stable Diffusion?
No. Once you have downloaded the model weights and installed a local UI like ComfyUI or AUTOMATIC1111, you can generate images entirely offline. This is one of the core advantages over API-based services and makes local Stable Diffusion suitable for air-gapped environments or sensitive content pipelines.
How is FLUX.1 related to Stable Diffusion?
FLUX.1 was released in August 2024 by Black Forest Labs, founded by Robin Rombach and Andreas Blattmann — the researchers who originally created Stable Diffusion at LMU Munich before joining and then leaving Stability AI. FLUX is architecturally distinct (a 12B-parameter hybrid diffusion transformer rather than a U-Net), but it follows the same open-weights philosophy. FLUX.1 [schnell] is Apache 2.0 licensed and is widely considered the spiritual successor to Stable Diffusion in the open-model space.
Can I fine-tune Stable Diffusion on my own photos?
Yes. The most common approach is training a LoRA using 10–30 captioned images of your subject, which takes roughly 30–60 minutes on a modern GPU. Tools like kohya_ss and OneTrainer provide beginner-friendly GUIs. A successful LoRA can reliably reproduce a specific person, product, or visual style across any compatible base checkpoint.
Why do some people use SD 1.5 in 2026 when newer models exist?
Ecosystem depth. SD 1.5 has the largest library of community fine-tunes ever built around a single model architecture — tens of thousands of checkpoints and LoRAs on Civitai alone, covering every art style imaginable. Newer architectures like SDXL and SD 3.5 produce higher base quality but have far fewer specialized community fine-tunes. If you need a very specific obscure aesthetic, SD 1.5 frequently has a ready-made fine-tune that newer models simply do not.