In plain English
By default, a large language model answers like a helpful colleague writing an email: it wraps the real answer in friendly prose. You ask for a list of three product names and you get "Sure! Here are three great options for you:" followed by the list, followed by "Let me know if you'd like more!" That's lovely for a human and a nightmare for a program that expected three clean lines or a block of JSON.
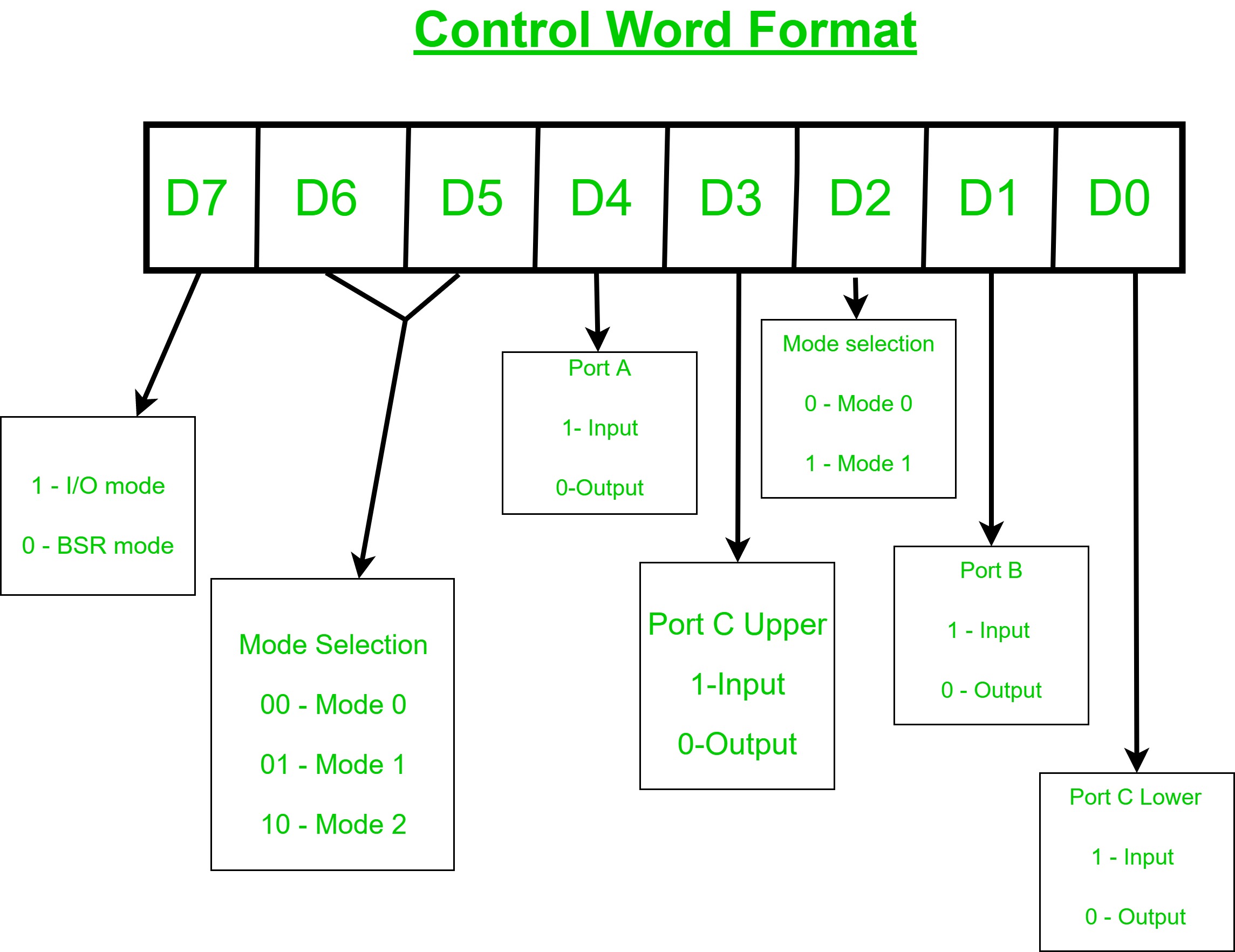
Controlling output format means using your prompt to pin the model to one exact shape — valid JSON, a Markdown table, a bullet list, a fixed template — so that whatever you build around it can read the answer reliably. The key idea: you are not asking for help, you are asking for output in a contract. This article is about doing that with words alone, using nothing but the prompt.
Think of it like ordering at a busy deli. If you say "I'd like something with turkey," you'll get a friendly conversation and maybe the wrong sandwich. If you say "One turkey on rye, no mayo, cut in half, in a box — nothing else," you get exactly that. A format prompt is the second kind of order: specific, closed, and leaving the model little room to improvise.
Why it matters
The moment an LLM stops being a chat toy and becomes part of a program, its output has to be parsed by code. Code is unforgiving. A single stray sentence of prose, a trailing comma, or a Markdown code fence wrapped around your JSON can crash the parser and take your feature down with it.
- Parsing reliability. If you call
JSON.parse()on the model's reply, that reply must be only JSON — no "Here's the data:" preamble, no closing remark. Format control is what makes the parse succeed on the first try, every time. - Downstream automation. An extracted invoice total feeds a database. A list of tags feeds a search index. A classification label routes a support ticket. Each of these breaks if the shape wanders, so a predictable format is the seam that lets you wire an LLM into a real pipeline.
- Cost and latency. Friendly prose is tokens you pay for and wait for. "Return only the three values, comma-separated" is shorter to generate, cheaper, and faster than a chatty paragraph that says the same thing.
- Fewer post-processing hacks. Without format control, teams write brittle regexes to claw the answer out of prose. Those regexes rot the moment the model phrases things slightly differently. Getting the shape right at the source removes a whole layer of fragile cleanup.
Anyone wiring an LLM into software cares about this: data-extraction jobs, classifiers, agents that call tools, "fill this template" generators, and batch pipelines that process thousands of items unattended. When no human is watching each reply, the format is the interface — and a sloppy interface fails silently at 3 a.m.
How it works
An LLM generates text one token at a time, always predicting what "should" come next based on its training. Most of its training is ordinary conversational text, so its default pull is toward polite, well-explained prose. Format control is the craft of overriding that pull — making the most-likely next tokens be the ones you want. There are five core levers, and they stack.
1. Describe the format in words
The simplest lever: tell the model precisely what you want. Don't say "return JSON" — say which keys, which types, and what each means. Ambiguity is the enemy; every detail you leave out, the model fills in with its own guess.
Return a JSON object with exactly these keys:
- "sentiment": one of "positive", "negative", "neutral"
- "score": a number from 0 to 1
- "reason": a short string, max 12 words
Do not add any other keys.2. Show a worked example (the format example)
Models imitate. One concrete, filled-in example of the exact output is often more powerful than a paragraph of description, because it removes all doubt about spacing, quoting, and structure. This is few-shot prompting applied to shape rather than content. Show the skeleton you want and the model snaps to it.
3. Forbid the prose explicitly
The model's instinct is to be helpful and explain itself. You have to actively shut that off with a blunt instruction: "Output only the JSON object. Do not include any explanation, preamble, or Markdown code fences." Naming the specific failure modes (preamble, code fences) works better than a vague "just the JSON," because you are pre-empting exactly the habits the model reaches for.
4. Prefill the start of the answer
This is the strongest prompt-only trick. In a chat-style API you usually send user and assistant turns. If you put the beginning of the assistant's reply into the request yourself — say, a single { — the model is forced to continue from there. It physically cannot open with "Sure! Here's…" because the next token must follow your {. You have grabbed the steering wheel for the first character, and the first character is where prose usually sneaks in.
{
"messages": [
{ "role": "user", "content": "Extract the order as JSON." },
{ "role": "assistant", "content": "{" }
]
}5. Stop sequences
A stop sequence is a string that tells the API to halt generation the instant the model produces it. Set the stop sequence to whatever marks the end of your format — a closing triple-backtick fence, or a custom token like </json> — and the model is cut off before it can add a chatty sign-off. Combined with a prefill, you bracket the output on both ends: the prefill controls how it starts, the stop sequence controls where it ends.
A worked example, prose to clean JSON
Let's extract structured data from a messy sentence and force a parseable result. Here is a single prompt that uses four of the five levers at once: a described schema, a format example, an explicit no-prose rule, and (in the call) a prefill.
Extract the order details from the message below.
Return ONLY a JSON object, no prose, no code fences, matching this shape:
{"item": string, "qty": integer, "size": "S"|"M"|"L"|null}
Example input: "can I get two large blue hoodies"
Example output: {"item": "blue hoodie", "qty": 2, "size": "L"}
Message: "hey could you send me 3 medium coffee mugs please"Paired with a prefilled { on the assistant turn, the model returns:
{"item": "coffee mug", "qty": 3, "size": "M"}No greeting, no "Here's your JSON," no trailing offer to help. Your code can call JSON.parse on it directly. Notice how the example carries weight the description can't: it shows that "two large blue hoodies" should collapse to "blue hoodie" and "L", teaching the normalization you want, not just the syntax.
Why models drift back to prose (and how to catch it)
Understanding why format prompts fail tells you which lever to reach for. The drift almost always comes from one of a few predictable habits baked in during training.
| The drift you see | Why it happens | The fix |
|---|---|---|
| "Sure! Here is the JSON you asked for:" | Helpfulness training rewards friendly preambles | Prefill the opening {; add "no preamble" |
| Wrapping JSON in triple-backtick fences | Chat UIs train the model to format code blocks | Forbid fences explicitly, or prefill the fence and stop on the closing one |
| "Let me know if you need anything else!" | Conversational sign-offs are everywhere in training | Use a stop sequence at the end of the format |
| Extra commentary keys or notes | The model 'explains' inside the structure | Say "exactly these keys, no others"; show a tight example |
| Trailing comma / single quotes in JSON | Casual code style leaks in | Show a strictly valid example; validate and repair |
Catching malformed output is half the job. Build a small validation gate around every call so a bad reply never reaches your database:
import json
def parse_or_repair(raw, prefill=""):
text = prefill + raw # glue prefill back on
# strip accidental code fences if they slipped through
text = text.strip().removeprefix("```json").removeprefix("```").removesuffix("```").strip()
try:
return json.loads(text)
except json.JSONDecodeError:
return None # signal: retry, or ask model to fix it
result = parse_or_repair(model_output, prefill="{")
if result is None:
# cheap recovery: send the broken text back and ask for valid JSON only
result = retry_with_fix(model_output)Choosing the right format for the job
JSON is the default for machine consumption, but it isn't always the best choice. Match the format to who — or what — reads the output next.
- Best for code to parse
- Strict, nestable, typed
- Easy to validate
- Brittle: one bad comma breaks it
- Best for a human to read
- Renders nicely in UIs
- Forgiving of small slips
- Harder to parse precisely
- Best for simple, flat data
- One value per line or CSV-style
- Very robust, easy to split
- No nesting, no types
Some practical rules of thumb. If code will parse it, use JSON and validate it. If a person will read it in a chat or doc, ask for a Markdown table or bullet list. If you just need a handful of flat values, a line-per-item or simple delimited format is the most robust thing you can ask for — there's almost nothing to get syntactically wrong. And when structure matters inside the prompt itself, XML-style tags are a clean way to fence sections — see structuring prompts with XML and Markdown.
Going deeper
Once the basics click, a few subtler points separate a demo from a system that survives thousands of real calls.
Prompt-craft vs. guaranteed structured output. Everything here makes valid output highly likely. For a hard guarantee, most major APIs offer a structured-output or JSON-mode feature, often driven by a JSON Schema, that constrains the decoder so it cannot emit invalid JSON. The trade: it's the strongest guarantee, but it's tied to a specific provider and sometimes a specific model, and it can be less flexible for non-JSON shapes. A common production pattern is to use the API guarantee when available and keep the prompt-craft techniques as your portable fallback.
Format vs. reasoning quality. As noted above, tight formats can suppress the model's thinking. The fix is to give reasoning a home inside the structure — a "thinking" string before the "answer" field, or a scratch section before a stop delimiter — so you get both careful reasoning and a clean parse. Newer reasoning models separate their thinking tokens from the final answer automatically, which sidesteps much of this tension.
Prefilling has limits. It's a powerful lever, but support varies by provider, and a too-aggressive prefill can paint the model into a corner — if you prefill {"answer": and the right answer is "I don't know," you've forced an awkward output. Prefill the frame (the opening bracket or fence), not the content.
Make it part of the system, not just the prompt. Pin the format in the system prompt so it holds across a long conversation, validate every reply against a schema in code, log the failures, and feed the worst ones back as new few-shot examples. Format control isn't a one-time prompt tweak; it's a small loop of specify → validate → repair → improve that you tighten over time. Treat it like context engineering: the prompt, the examples, and the validation code are one system, and the format is only as reliable as the weakest of the three.
The durable lesson: an LLM's default is helpful prose, and every reliable format is the result of actively overriding that default — describe it, show it, forbid the prose, prefill the start, stop at the end, and verify what comes back. Do all five and the model will hand your program exactly the shape it expects.
FAQ
How do I force an LLM to return only JSON with no extra text?
Stack three moves: describe the exact JSON shape, add the instruction "Output only the JSON, no prose or code fences," and prefill the assistant turn with an opening { so the reply can't start with a greeting. Then validate with a try/catch and retry if it doesn't parse. For a hard guarantee, use your provider's structured-output or JSON-mode API.
What is prefilling the assistant response?
Prefilling means putting the first part of the assistant's reply into your API request yourself — for example a single {. The model must continue from your text, so it physically cannot open with "Sure, here's…". Remember the final output is your prefill plus the model's continuation, so glue them together before parsing.
Why does the model keep adding explanations even when I ask for just the data?
Models are trained on conversational text and rewarded for being helpful, so adding a preamble or a closing offer is their default habit. Counter it by naming the specific behaviors to avoid ("no preamble, no code fences"), prefilling the start of the answer, and using a stop sequence to cut off any sign-off at the end.
How do I make ChatGPT or any LLM output a Markdown table?
Show one small example table with your exact column headers, then say "Return only a Markdown table with these columns and nothing else." A filled-in example is more reliable than a description because it fixes the column order, headers, and separator rows for the model to copy.
What is a stop sequence and when should I use one?
A stop sequence is a string that tells the API to halt generation the moment the model produces it. Use it to mark the end of your format — a closing code fence or a tag like </json> — so the model is cut off before it can append a chatty closing line. It pairs well with prefilling to bracket the output on both ends.
Is prompting for format as reliable as using a JSON-mode API?
No. Prompt-craft makes valid output very likely but not guaranteed, so you must always validate and have a fallback. A structured-output or JSON-mode API constrains decoding so the result can't be invalid JSON — that's stronger, but it's tied to a specific provider. Many teams use the API when available and keep prompt techniques as a portable backup.