In plain English
Imagine two research assistants. You give both the same stack of documents and the same question. The first types up a confident, well-written answer. The second does the same — but every sentence ends with a bracketed number pointing to the exact paragraph it came from. The first answer might be right. The second answer is verifiable. Grounded generation is the engineering practice of making your RAG system behave like the second assistant.
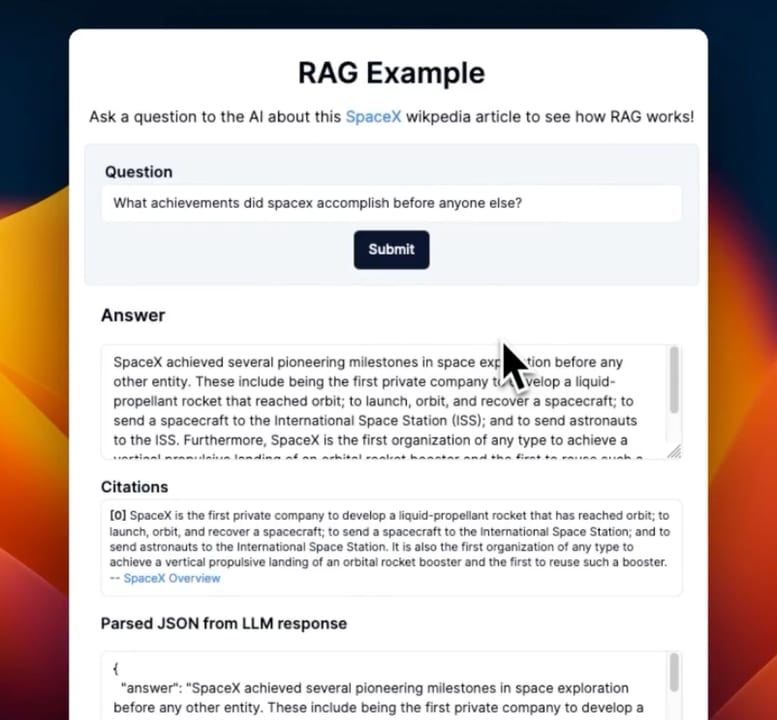
In a standard RAG pipeline, the retriever fetches the top-k chunks and the LLM synthesizes an answer from them. The answer sounds authoritative, but there is no traceable link between the text on screen and the source that justified it. Citations restore that link. The model identifies which chunk (or which span within a chunk) supports each claim it makes, and the UI surfaces that pointer as a numbered footnote, a highlighted passage, or a clickable source card. The user goes from "I guess I trust this" to "I can check this right now."
Why it matters
RAG reduces hallucination, but it does not eliminate it. A 2025 Stanford study of RAG-powered legal assistants found hallucination rates of 17–34% even in purpose-built systems. Citations do two things that help: they let users catch hallucinations themselves, and they force the pipeline to surface evidence so that automated verifiers can catch them on your behalf.
- Trust in enterprise deployments. When a compliance officer reads a policy summary, they need to know which clause it came from — not because they distrust AI, but because they are personally accountable for the answer. Citations turn RAG from a useful toy into a professional tool.
- Automated quality gates. A citation is a testable claim. You can build a verifier that re-reads the cited chunk and scores whether it actually supports the sentence. Without citations, you can only score the answer holistically, which is far weaker.
- Debugging. When the answer is wrong, citations tell you whether the problem is in retrieval (wrong chunk was fetched) or in generation (right chunk, wrong summary). That distinction drives completely different fixes.
- Regulatory and legal exposure. In medical, legal, and financial applications, an uncited assertion made by an AI is a liability. A cited one at least points to the underlying source where accountability lives.
- User experience. Showing sources builds user confidence even before they click through, and gives power users a fast path to the original for context the summary omits.
How it works
There are three broad moments in the RAG pipeline where citation work happens: at index time (tag every chunk with a stable identifier and rich metadata), at generation time (prompt the model to emit citation markers inline with its answer), and at verification time (check that each citation actually supports the claim beside it). Most production systems combine all three.
Step 1 — Index time: give every chunk a stable ID and rich metadata
Nothing downstream works unless each chunk carries a durable pointer back to its origin. At minimum that means a stable chunk_id (a UUID or a deterministic hash of the content), the source document name or URL, and a page or section number. Vector databases including Pinecone, Qdrant, and Weaviate store arbitrary key-value metadata alongside each vector — exploit this. If you are chunking a PDF, capture the bounding box so you can highlight the exact paragraph in a document viewer later.
import hashlib
def chunk_with_metadata(text: str, source_url: str, page: int) -> dict:
chunk_id = hashlib.sha256(text.encode()).hexdigest()[:12]
return {
"chunk_id": chunk_id,
"text": text,
"metadata": {
"source_url": source_url,
"page": page,
},
}
# Later, when you upsert into a vector DB:
# vector_db.upsert(id=chunk["chunk_id"], vector=embed(chunk["text"]), metadata=chunk["metadata"])Step 2 — Generation time: prompt the model to cite as it writes
Before calling the LLM, number the retrieved chunks and inject them into the system prompt with their IDs visible. Then tell the model explicitly that every factual claim must be followed by the bracketed source number. Most frontier models follow this instruction reliably. The prompt pattern looks like this:
def build_cited_prompt(question: str, chunks: list[dict]) -> str:
context_lines = []
for i, chunk in enumerate(chunks, start=1):
context_lines.append(f"[{i}] (id={chunk['chunk_id']})\n{chunk['text']}")
context = "\n\n".join(context_lines)
system = (
"You are a helpful assistant. Answer using ONLY the sources below. "
"After every factual claim, add the source number in brackets, e.g. [1] or [2,3]. "
"Do NOT add claims you cannot support with a source number."
)
user = f"Sources:\n{context}\n\nQuestion: {question}"
return system, userThe key instruction is "Do NOT add claims you cannot support" — this nudges the model toward acknowledged uncertainty rather than fabricated citations. When you get the model's response back, parse out the [N] markers with a regex and resolve each number to the corresponding chunk_id from your numbered list.
Step 3 — Verification time: check every citation is real
Once the model has produced a cited answer, you can run an automated verification pass. The two dominant approaches are NLI-based and LLM-as-judge. NLI (natural language inference) classifiers — such as fine-tuned versions of DeBERTa or AlignScore — take a (claim, evidence) pair and return entailment, neutral, or contradiction. LLM-as-judge passes the same pair to a capable model with a structured scoring prompt. Both approaches output a per-citation confidence score. Claims with low confidence can be flagged in the UI, suppressed, or sent back for retrieval retry.
Citation strategies compared
There is no single right way to produce citations. The four mainstream strategies sit on a spectrum from simple prompt engineering to multi-step pipelines, each with different accuracy and latency tradeoffs.
| Strategy | How it works | Accuracy | Latency | Complexity |
|---|---|---|---|---|
| Inline source IDs | Number chunks, prompt model to emit [N] markers | Good with strong models | No extra calls | Low |
| Quote-then-cite | Model first quotes exact passages, then builds answer from quotes | High — grounding enforced at generation | Slightly higher | Medium |
| Post-hoc attribution | Generate answer first, then run a second pass to assign sources | Moderate — relies on semantic match | One extra call | Medium |
| NLI verification layer | Run NLI classifier on every (claim, cited chunk) pair after generation | Highest audit quality | High — per-claim calls | High |
Quote-then-cite: breaking the task into steps
One of the most reliable patterns is to split the cognitive load: in a first LLM call, ask the model to extract verbatim quotes from the retrieved chunks that are relevant to the question. In a second call, ask the model to write an answer using only those quotes as building blocks, citing the source of each quote. Because the second step is constrained to exact text the model copied from sources, the grounding is much tighter than asking the model to simultaneously reason and cite. This is the logic behind LlamaIndex's CitationQueryEngine, which creates intermediate "citation nodes" wrapping the exact excerpt.
Post-hoc attribution: adding citations after the fact
Sometimes you have a generated answer already — from a legacy pipeline, a different model, or a streaming output you could not interrupt — and you need to add citations retrospectively. Post-hoc attribution splits the answer into sentences, embeds each sentence, and retrieves the best-matching chunk from the vector store for that sentence. The sentence-to-chunk similarity score becomes the citation confidence. This works reasonably well but has a known failure mode: a sentence may semantically resemble a chunk without being derived from it. Pair it with an NLI check to catch false positives.
Pitfalls and common mistakes
Citation systems fail in a small number of predictable ways. Knowing them up front saves a lot of debugging.
- Metadata stripped at chunk time. If you split documents with a library that discards the source URL or page number, you have nothing to cite. Make metadata inheritance the first thing you test in your chunker.
- ID drift between index and retrieval. If you rebuild your index and chunk IDs change, previously cached citation pointers become stale. Use content-based hashes or stable document-level IDs rather than auto-increment integers.
- Citation hallucination without verification. A model that is told to cite will cite — sometimes to sources that do not support the claim. Always run at least a spot-check pass; in production, run an automated NLI or LLM-judge verifier.
- Over-citing. Adding
[1][2][3]after every clause makes the answer unreadable and often reflects the model hedging rather than genuine multi-source support. Instruct the model to cite only when genuinely required, and prefer the single best source. - UI that drops citations. It is common to implement the citation logic in the backend and then have the frontend strip out the
[N]markers as "ugly". Citations without a rendered UI are invisible. Treat citation rendering as a first-class frontend feature from day one. - Confusing faithfulness with correctness. A citation can be faithful (the chunk really does say what the model claimed) but incorrect if the chunk itself contains wrong information. Citations ground the answer in the retrieved documents — they do not guarantee the documents are true.
Going deeper
Span-level attribution is the research frontier. Most production systems cite at the chunk level — "this paragraph came from Document 3". Span-level attribution goes finer: it highlights the exact sentence or phrase within the chunk that supports the claim. Achieving this requires either a fine-tuned model that produces character-offset pointers alongside its answer, or a post-hoc alignment step that uses fuzzy string matching to locate the model's paraphrase inside the original text. The TREC 2025 RAG Track, a shared evaluation benchmark, requires sentence-level citation links in submitted systems, signalling that span attribution is becoming the expected standard in research.
NLI classifiers vs LLM-as-judge. NLI models trained on datasets like MultiNLI are fast and cheap — a DeBERTa-based classifier runs in milliseconds per pair — but they are known to miss paraphrase-heavy entailment and struggle with domain-specific terminology. LLM-as-judge is slower and more expensive but handles nuance far better, can explain its verdict, and generalises across domains without fine-tuning. The pragmatic choice for most teams: use NLI as a first-pass filter for obvious non-entailments, then escalate low-confidence cases to an LLM judge. This keeps cost manageable while catching the failure modes that NLI misses.
Correctness vs faithfulness is a subtle trap. A citation can be perfectly faithful — the model is accurately summarising the chunk — while being incorrect if the chunk itself is wrong or out of date. Conversely, a citation can be technically unfaithful (the model used slightly different phrasing) while pointing to perfectly relevant source material. Evaluation frameworks like CiteEval (2024) try to disentangle these axes by scoring redundancy, credibility, and evidence completeness separately, rather than collapsing everything into a single binary score.
Model training for citation. Beyond prompt engineering, some teams fine-tune or preference-tune their generation model to natively produce citations. The 2025 paper Cite Pretrain explored pre-training on corpora where inline citation anchors are already present (such as Wikipedia, which has inline [N] footnotes throughout), teaching the model to expect the citation idiom during generation rather than learning it only at inference time via a system prompt. Fine-tuned citation models make fewer citation-shaped hallucinations and require simpler prompts. For most teams the prompt-engineering approach is good enough; fine-tuning makes sense when you have a domain-specific corpus and citation quality is a hard requirement.
TREC RAG Track as a benchmark. If you want to measure your system against a public standard, the TREC 2025 RAG Track is the best current reference. It requires structured JSON output where each answer sentence carries explicit document citations, and it evaluates both nugget-based answer quality and citation faithfulness separately. Reviewing the task guidelines and top-system papers is one of the fastest ways to understand the state of the art in production citation systems.
FAQ
Do I need to fine-tune my LLM to get good citations?
Not usually. Modern frontier models (the GPT-5 series, Claude's Opus and Sonnet models, Gemini 3) follow citation instructions reliably when prompted correctly. Fine-tuning pays off mainly when you need span-level attribution, work in a narrow domain with specialised terminology, or have very high citation-accuracy requirements. For most production RAG systems, prompt engineering plus a post-hoc verification step is enough.
What is the difference between citation and attribution in RAG?
Attribution is the broad concept of linking generated content back to a source — it can be implicit (the model was grounded but shows nothing to the user) or explicit. Citation is the user-visible signal that makes attribution legible: a bracketed number, a link, a highlighted excerpt. In practice the terms are used interchangeably, but if you see them contrasted, attribution is the internal mechanism and citation is the external presentation.
How do I prevent the model from citing sources it did not actually use?
Three approaches together work best: first, instruct the model to only cite when it can, and to say "I don't know" rather than fabricate a source. Second, run an NLI or LLM-judge verification pass that checks whether each cited chunk actually entails the claim beside it. Third, implement the quote-then-cite pattern so the model is constrained to passages it copied verbatim before building the answer — this makes up citations structurally harder.
Can I add citations to a RAG system that already generates un-cited answers?
Yes — this is called post-hoc attribution. You split the existing answer into sentences, embed each sentence, and retrieve the best-matching chunk for each one. The retrieved chunk becomes the citation. It works reasonably well but is less reliable than generating citations during the initial response, because the model may have synthesised claims from multiple chunks in ways that are hard to disentangle after the fact.
What metadata should I store with each chunk to support citations?
At minimum: a stable chunk ID, the source document name or URL, and a page or section number. For PDFs, storing the bounding box of the text block enables pixel-accurate highlighting in a document viewer. For web pages, storing the URL fragment or heading anchor lets you deep-link directly to the passage. Rich metadata costs almost nothing at index time and is extremely hard to reconstruct after the fact.
How do I evaluate whether my citations are good?
Score two things separately: faithfulness (does the cited chunk actually support the claim — measured with NLI or LLM-as-judge) and completeness (are all the important claims in the answer cited at all — measured by scanning the answer for uncited factual sentences). Frameworks like RAGAS, TruLens, and CiteEval provide automated metrics for both. Run on a held-out eval set before and after any citation-related change.