In plain English
When you ask your RAG pipeline a question, the retriever searches a corpus and returns a ranked list of chunks — say the top 5. Retrieval metrics are how you grade that list before the LLM ever sees it. Did the retriever bring back the chunks that actually contain the answer? Did it waste slots on irrelevant noise? Did the best chunk land at position 1 or buried at position 5?
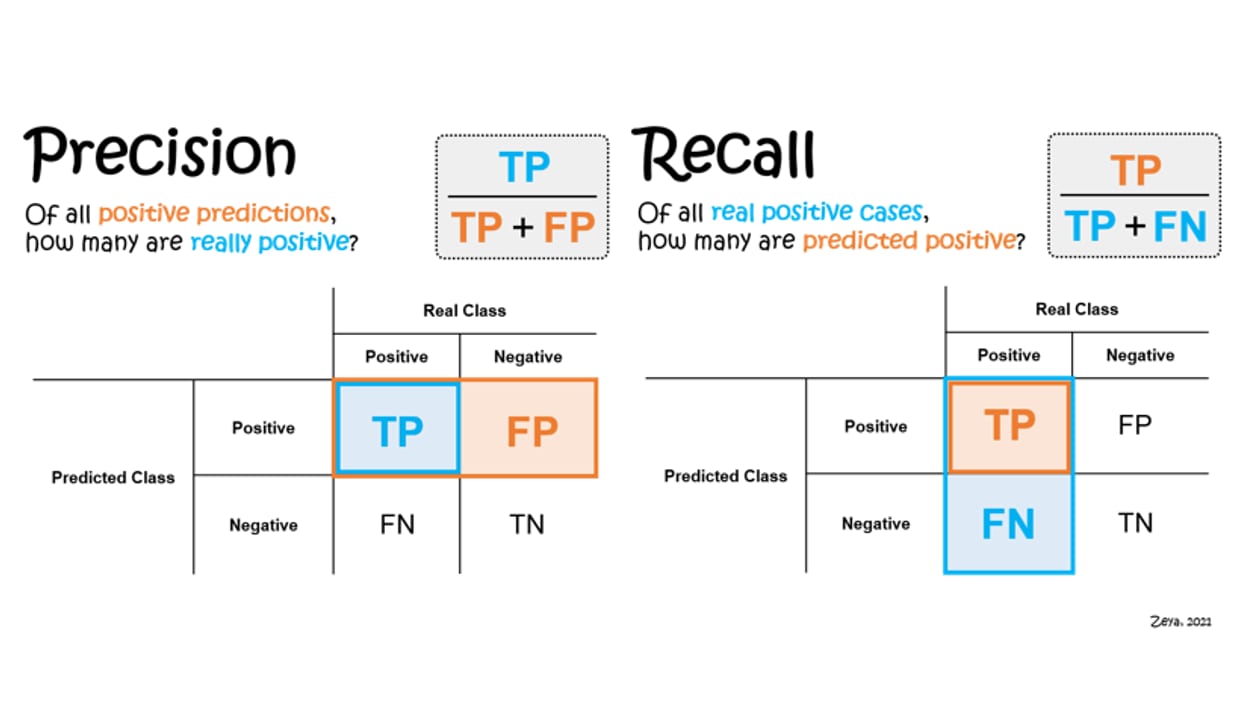
Think of your retriever as a detective who can search a filing cabinet. Precision measures how many of the files the detective pulled out were actually relevant to the case — quality of the haul. Recall measures how many of the relevant files in the entire cabinet were found — coverage. MRR (Mean Reciprocal Rank) measures how quickly the detective's first relevant file appears — speed of the hit. A perfect detective scores 1.0 on all three: every file pulled is relevant, every relevant file is pulled, and the best file is always on top.
All three metrics are defined at K — meaning they only look at the top K results returned. You typically see values like precision@5, recall@10, or MRR@10. The K you choose should match how many chunks your LLM actually processes: if you pass top_k=5 to your generator, measure at K=5.
Why it matters
The retriever is the gatekeeper of your RAG system. If it fails to surface the right chunk, no amount of prompt engineering or model quality can fix a bad answer — the generator cannot hallucinate its way to the correct fact it was never shown. Conversely, if the retriever floods the context with irrelevant chunks, the generator has to work harder to find the signal in the noise, and the risk of a confused or hallucinated answer rises sharply.
Retrieval metrics give you a fast, cheap feedback signal you can compute without running the full LLM generation step. You just need a test set of questions paired with the chunk IDs that contain the correct answer. This makes them ideal for tight iteration loops: change your embedding model, chunking strategy, or similarity threshold, run the retrieval eval in seconds, and know immediately whether things got better or worse.
What each metric diagnoses
| Metric | The question it answers | Fix when it is low |
|---|---|---|
| Precision@K | Of the K chunks I retrieved, how many were relevant? | Raise similarity threshold, add a reranker, improve embedding model |
| Recall@K | Of all relevant chunks in the corpus, how many did I find in the top K? | Increase K, rethink chunk boundaries, use query expansion or HyDE |
| MRR@K | On average, how far down the list before the first relevant chunk appears? | Rerank top results, tune retrieval scoring, use hybrid BM25 + vector search |
The three metrics pull in different directions. Raising K almost always improves recall (more chances to find relevant chunks) but hurts precision (more irrelevant chunks sneak in). MRR is insensitive to K once the first relevant hit is found. Understanding this tension is the key to picking the right lever when something breaks.
How the metrics are computed
Each metric starts with the same raw data: a query, a ranked list of K retrieved chunk IDs, and a set of chunk IDs that a human (or a held-out ground truth) has marked as relevant. The formulas then count and weigh that overlap in different ways.
Precision@K
Precision@K is the fraction of the top-K retrieved chunks that are relevant. It is the simplest metric: count how many hits in your list are good, divide by K.
Precision@K = (number of relevant chunks in top K) / K
Example (K = 5):
Retrieved chunks: [C1✓, C2✗, C3✓, C4✗, C5✓] (✓ = relevant, ✗ = irrelevant)
Relevant chunks found: 3
Precision@5 = 3 / 5 = 0.60
Perfect score: 1.0 (all K chunks are relevant)
Worst score: 0.0 (no relevant chunk in top K)Precision@K penalises noise but does not care about coverage: a retriever that always returns 1 perfect chunk plus 4 junk chunks scores 0.20, even if that single chunk is exactly what the model needs. That is why you rarely use precision alone — you pair it with recall.
Recall@K
Recall@K measures coverage: of all the relevant chunks that exist anywhere in the corpus, what fraction did the retriever find within the top K? A recall of 0.5 means the retriever missed half the relevant material.
Recall@K = (number of relevant chunks in top K) / (total relevant chunks in corpus)
Example (K = 5, corpus contains 4 relevant chunks total):
Retrieved: [C1✓, C2✗, C3✓, C4✗, C5✓] → 3 relevant found
Recall@5 = 3 / 4 = 0.75
Perfect score: 1.0 (every relevant chunk in corpus is in top K)
Worst score: 0.0 (no relevant chunk found)Recall@K is the metric to watch when the risk is missed answers. In a legal document RAG system, missing a relevant clause is far more dangerous than including one extra irrelevant paragraph. In a general FAQ bot, the cost asymmetry is lower and you may accept lower recall to keep precision high and the context window clean.
Mean Reciprocal Rank (MRR)
MRR measures where the first relevant chunk appears in the ranked list. The reciprocal rank for one query is 1 divided by the rank position of the first relevant chunk. If the first relevant chunk is at position 1, the reciprocal rank is 1.0. At position 2 it is 0.5, at position 3 it is 0.33, and so on. MRR is the average of these reciprocal ranks across all queries in your test set.
Reciprocal Rank (single query) = 1 / rank_of_first_relevant_chunk
MRR = (1 / |Q|) * Σ (1 / rank_i) for i in 1..|Q|
Example (3 test queries):
Query 1: first relevant chunk at rank 1 → RR = 1/1 = 1.00
Query 2: first relevant chunk at rank 3 → RR = 1/3 = 0.33
Query 3: first relevant chunk at rank 2 → RR = 1/2 = 0.50
MRR = (1.00 + 0.33 + 0.50) / 3 = 0.61
Perfect MRR: 1.0 (first chunk is always relevant)
MRR of 0.5 means the first relevant hit lands at rank 2, on averageMRR is especially valuable in question-answering pipelines where the LLM needs the correct chunk to appear near the top of the context window. Research on the lost-in-the-middle problem shows that LLMs pay significantly more attention to content at the beginning and end of a long context than to content in the middle — so a relevant chunk buried at rank 4 out of 5 is often effectively invisible to the generator.
Worked example end-to-end
Let's walk through a concrete example: a RAG chatbot over a technical docs corpus. The test set has three questions. For each question, we know which chunk IDs are relevant (ground truth), and we see what the retriever returned at K=4.
| Query | Relevant chunks (ground truth) | Retrieved top-4 | First relevant rank |
|---|---|---|---|
| Q1: API rate limit | {C5, C12} | [C5, C8, C12, C3] | 1 |
| Q2: Authentication error | {C7} | [C2, C9, C1, C7] | 4 |
| Q3: Webhook retry logic | {C18, C19, C22} | [C18, C19, C4, C11] | 1 |
Now compute each metric:
--- Precision@4 ---
Q1: relevant in top 4 = {C5, C12} → 2 hits / 4 = 0.50
Q2: relevant in top 4 = {C7} → 1 hit / 4 = 0.25
Q3: relevant in top 4 = {C18,C19} → 2 hits / 4 = 0.50
Mean Precision@4 = (0.50 + 0.25 + 0.50) / 3 = 0.42
--- Recall@4 ---
Q1: 2 found / 2 total relevant = 1.00
Q2: 1 found / 1 total relevant = 1.00
Q3: 2 found / 3 total relevant = 0.67
Mean Recall@4 = (1.00 + 1.00 + 0.67) / 3 = 0.89
--- MRR@4 ---
Q1: first relevant at rank 1 → RR = 1/1 = 1.00
Q2: first relevant at rank 4 → RR = 1/4 = 0.25
Q3: first relevant at rank 1 → RR = 1/1 = 1.00
MRR@4 = (1.00 + 0.25 + 1.00) / 3 = 0.75Interpretation: Recall is strong at 0.89 — the retriever finds almost everything relevant. Precision is weaker at 0.42, meaning more than half the returned chunks are noise. MRR is 0.75, dragged down by Q2 where the only relevant chunk landed at the very last slot. The actionable fix is a reranker that re-orders the four retrieved chunks by relevance: it would push C7 from rank 4 to rank 1 for Q2, bringing MRR to 1.0, and might also push the irrelevant chunks for Q1 and Q3 to the bottom, improving precision.
MRR vs nDCG: knowing when to switch
MRR and precision@K both treat relevance as binary — a chunk is either relevant or not. nDCG (Normalized Discounted Cumulative Gain) adds a third dimension: how relevant a chunk is. In graded relevance, a chunk that contains the exact answer scores higher than a chunk that is tangentially related but not directly useful.
- Binary relevance labels (relevant / not)
- Single correct answer per query
- Question-answering, slot-filling
- Fast to compute, easy to explain
- Ignores results after the first hit
- Typical range: 0.5 – 0.9 in practice
- Graded relevance (0, 1, 2, 3...)
- Multiple relevant docs with varying quality
- Search engines, recommendation systems
- Captures full ranking quality
- Requires relevance labels, harder to annotate
- Normalised 0 – 1 against ideal ranking
For most RAG pipelines you should start with MRR and recall@K. They are cheap to annotate (binary labels) and directly answer the questions you care about. Switch to nDCG when you have a domain where partial relevance matters — for instance, a medical RAG where a chunk that mentions the right drug but the wrong dosage is better than a completely off-topic chunk, but worse than a chunk with the correct dosage. In that case binary labelling loses information that graded relevance preserves.
The BEIR benchmark (Benchmarking Information Retrieval), a widely used zero-shot evaluation suite for retrieval models, reports nDCG@10 as its primary metric. This is useful context when comparing off-the-shelf embedding models: a model claiming state-of-the-art BEIR scores is being evaluated on nDCG@10 across 18 heterogeneous datasets, which is a more demanding standard than a single-domain binary recall@5.
Computing retrieval metrics in code
You can compute all three metrics with a few lines of Python. No external library is strictly required for the basics, though libraries like ranx and ir-measures provide battle-tested implementations and support for many additional metrics.
def precision_at_k(retrieved: list[str], relevant: set[str], k: int) -> float:
"""Fraction of top-k retrieved items that are relevant."""
top_k = retrieved[:k]
hits = sum(1 for doc_id in top_k if doc_id in relevant)
return hits / k
def recall_at_k(retrieved: list[str], relevant: set[str], k: int) -> float:
"""Fraction of all relevant items found in top-k."""
if not relevant:
return 0.0
top_k = retrieved[:k]
hits = sum(1 for doc_id in top_k if doc_id in relevant)
return hits / len(relevant)
def reciprocal_rank(retrieved: list[str], relevant: set[str]) -> float:
"""1 / rank of the first relevant item (0 if none found)."""
for rank, doc_id in enumerate(retrieved, start=1):
if doc_id in relevant:
return 1.0 / rank
return 0.0
def mean_reciprocal_rank(
queries: list[tuple[list[str], set[str]]]
) -> float:
"""MRR over a list of (retrieved, relevant) pairs."""
return sum(reciprocal_rank(r, rel) for r, rel in queries) / len(queries)
# Example
results = [
(["C5", "C8", "C12", "C3"], {"C5", "C12"}), # Q1
(["C2", "C9", "C1", "C7"], {"C7"}), # Q2
(["C18", "C19", "C4", "C11"], {"C18", "C19", "C22"}), # Q3
]
K = 4
for i, (retrieved, relevant) in enumerate(results, 1):
p = precision_at_k(retrieved, relevant, K)
r = recall_at_k(retrieved, relevant, K)
rr = reciprocal_rank(retrieved, relevant)
print(f"Q{i}: precision@{K}={p:.2f} recall@{K}={r:.2f} RR={rr:.2f}")
print(f"MRR@{K}: {mean_reciprocal_rank(results):.2f}")For a more complete harness, the open-source library ranx supports precision, recall, MRR, nDCG, MAP, and many more metrics with a single unified interface. It accepts standard TREC-format run files and qrels, making it easy to plug into any retriever evaluation pipeline.
pip install ranxfrom ranx import Qrels, Run, evaluate
# qrels: ground truth relevance labels per query
qrels = Qrels({
"q1": {"C5": 1, "C12": 1},
"q2": {"C7": 1},
"q3": {"C18": 1, "C19": 1, "C22": 1},
})
# run: retriever output — doc_id -> score (higher = better rank)
run = Run({
"q1": {"C5": 0.95, "C8": 0.80, "C12": 0.72, "C3": 0.61},
"q2": {"C2": 0.88, "C9": 0.79, "C1": 0.71, "C7": 0.60},
"q3": {"C18": 0.91, "C19": 0.85, "C4": 0.70, "C11": 0.65},
})
results = evaluate(qrels, run, ["precision@4", "recall@4", "mrr@4"])
print(results)Going deeper
The three core metrics cover most RAG evaluation needs, but there are important nuances and extensions that matter in production.
MAP: the average over all relevant chunks
Mean Average Precision (MAP) extends MRR to handle queries with multiple relevant chunks. While MRR stops caring about the ranked list after finding the first relevant result, MAP computes a precision score at every position where a relevant chunk appears, then averages those precision values. A retriever that finds all three relevant chunks at ranks 1, 2, 3 scores higher MAP than one that finds them at ranks 1, 3, 5 — even if their MRR scores are identical (both have a first relevant hit at rank 1). MAP is the right choice when every relevant chunk matters equally and you have many relevant documents per query.
The annotation bottleneck
All of these metrics require relevance labels — someone or something has to specify which chunks are correct for each query. Two practical shortcuts: first, if you have a QA dataset (questions with verified answers), embed the answer text and find the chunks it comes from. Second, use an LLM to generate synthetic question-answer pairs from your documents — each question maps to the source chunk as relevant. The RAGAS TestsetGenerator does exactly this. Synthetic labels are noisier than human labels but cheap to produce at scale and good enough for catching major regressions.
Hit rate vs recall
Hit rate@K (also called top-K accuracy) is a simplified version of recall used in many RAG evaluation toolkits. It answers a binary question: does the top-K list contain at least one relevant chunk? Hit rate@K = 1 if any relevant chunk appears in the top K, otherwise 0. It is faster to compute and easier to explain to stakeholders ("we find the answer 87% of the time in the top 5 results"), but it conceals how many relevant chunks are missing. Use hit rate for executive dashboards and recall@K for engineering decisions.
When metrics disagree with user satisfaction
High recall@5 does not guarantee a good user experience. If the retriever fetches 4 relevant chunks but they all say the same thing, the LLM produces a redundant answer. Diversity is not captured by standard retrieval metrics, and neither is freshness (returning a recent chunk vs. an outdated one) or authority (a primary source vs. a third-party summary). In production systems, it pays to log implicit signals — thumbs-up/down, follow-up questions, session abandonment — and correlate them with your offline metrics to verify the metrics actually track what users care about.
FAQ
What is the difference between precision@k and recall@k in RAG?
Precision@K measures quality: of the K chunks your retriever returned, what fraction are relevant? Recall@K measures coverage: of all the relevant chunks that exist in the corpus, what fraction did you find in the top K? A retriever can score high on precision by returning a small, careful selection, but miss many relevant chunks (low recall). They measure opposite failure modes and you need both.
What does MRR of 0.5 mean?
An MRR of 0.5 means the first relevant chunk appears at rank 2 on average across your test queries. A score of 1.0 means the first retrieved chunk is always relevant; a score of 0.33 means the first relevant hit is typically at rank 3. MRR is most useful for question-answering tasks where you need the correct chunk near the top of the context window.
Should I use recall@k or MRR to evaluate my retriever?
Use both, but for different purposes. Recall@K tells you whether the right chunks are anywhere in your top-K results — the prerequisite for a correct answer. MRR tells you whether the right chunk is ranked near the top, which matters because LLMs pay more attention to the beginning of a long context. Fix recall first, then optimize MRR with a reranker.
How is nDCG different from MRR for retrieval evaluation?
MRR uses binary relevance labels (relevant or not) and focuses on where the first relevant result appears. nDCG uses graded relevance labels (e.g., 0 = irrelevant, 1 = partial, 2 = perfect) and considers the full ranked list, giving higher weight to results near the top. MRR is simpler to annotate and compute; nDCG captures ranking quality more completely when partial relevance matters.
What is hit rate and how does it differ from recall@k?
Hit rate@K is 1 if at least one relevant chunk appears in the top K, and 0 otherwise. It is a binary per-query score, usually reported as the percentage of queries where at least one relevant result was found. Recall@K is more granular: it tells you what fraction of all relevant chunks were found. Hit rate hides how many relevant chunks are still missing; recall@K exposes that.
How many test queries do I need to reliably measure retrieval metrics?
50 diverse, representative queries are enough to catch major regressions and make directional decisions. 100–200 gives you statistical stability for smaller improvements. Prioritise query diversity over raw count — 50 queries covering different topics, phrasings, and difficulty levels are more informative than 200 minor variations of the same question. Annotate with binary relevant/not-relevant labels to start.