In plain English
RAGAS (Retrieval-Augmented Generation Assessment) is an open-source Python framework that automatically grades a RAG pipeline. You give it a question, the retrieved context chunks, and the generated answer — and it hands back a set of scores between 0 and 1. No human grader required.
Think of RAGAS as a restaurant inspector who visits after the kitchen has closed. The inspector didn't watch every dish being cooked, but she can still taste the food, read the recipe, and check whether every ingredient in the recipe actually ended up on the plate. RAGAS does the same thing after a query runs: it tastes the answer, compares it to the retrieved context (the recipe), and checks whether everything that should be there is there — and nothing extra was invented.
The framework was introduced in a 2023 paper by Shahul Es and Jithin James and presented at EACL 2024. It is backed by Y Combinator (W2024) and processes more than five million evaluations per month for companies including AWS, Microsoft, and Databricks. It installs with a single pip install ragas and integrates natively with LangChain and LlamaIndex.
Why it matters
The central problem with RAG is that it has two places to fail: the retriever (fetching wrong or incomplete chunks) and the generator (making things up or ignoring what was retrieved). A single pass/fail test or a thumbs-up from a user tells you something broke, but not where. RAGAS decomposes the pipeline into separate scores so you know which component to fix.
The second problem is scale. Manually reviewing 500 chatbot answers a day is not feasible. RAGAS uses an LLM as a judge — the same class of model you are evaluating — to run the grading automatically. This means you can run evaluation on your full test set in minutes, track scores over every code change, and gate deployments on a quality threshold.
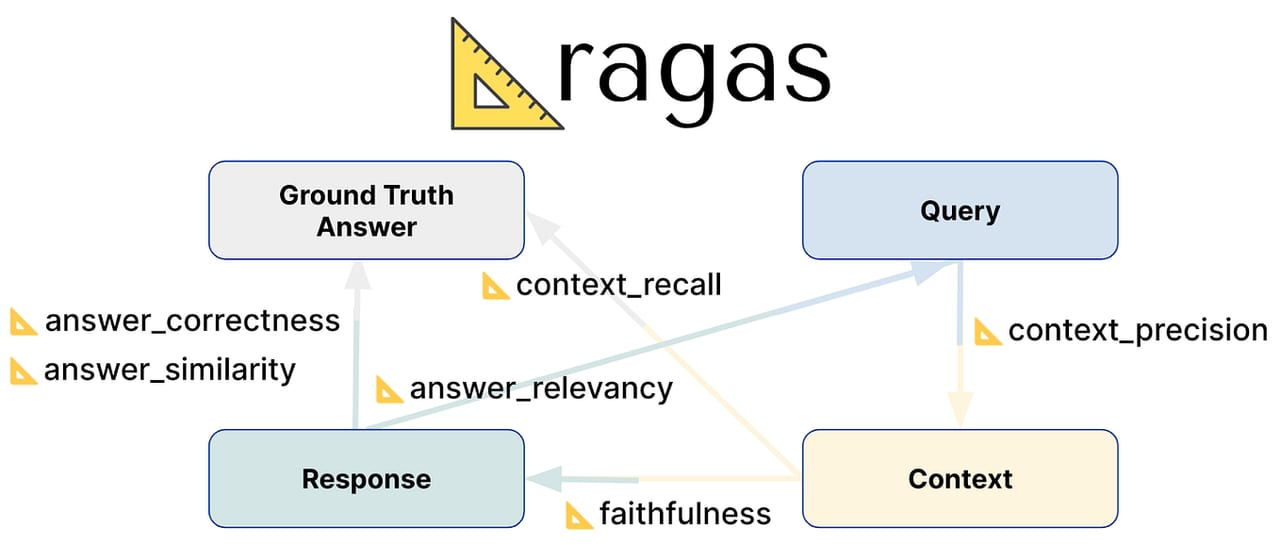
Reference-free vs. reference-required
A key feature of RAGAS is that most of its core metrics are reference-free: they compare the answer to the retrieved context or the original question, not to a human-written ground-truth answer. That means you can run faithfulness and answer relevancy on live production traffic without having to annotate anything first. Only context recall needs a reference answer to score against.
| Metric | Needs ground truth? | What it diagnoses |
|---|---|---|
| Faithfulness | No | Generator hallucinating beyond the retrieved context |
| Answer Relevancy | No | Generator giving vague or off-topic answers |
| Context Precision | Yes (or LLM judge) | Retriever returning noisy, irrelevant chunks |
| Context Recall | Yes | Retriever missing chunks needed to answer the question |
How it works
Every RAGAS metric follows the same pattern: form a specific prompt that encodes the evaluation task, send it to a judge LLM (by default OpenAI's flagship GPT model, but any LLM works), parse the structured response, and derive a numeric score. The framework ships prompt templates and parsing logic for each metric; you supply the judge LLM and the data.
Faithfulness: claim-by-claim fact checking
Faithfulness is the flagship metric. The judge LLM first decomposes the answer into individual factual claims — for example, "The first Super Bowl was held on January 15, 1967" becomes one claim. It then checks each claim against the retrieved context and returns a binary verdict per claim. The score is the fraction of claims that are supported: faithfulness = supported_claims / total_claims. A score of 0.5 means half the answer was hallucinated beyond the retrieved text.
Answer relevancy: reverse-engineering the question
Answer relevancy does not need a reference answer at all. The judge LLM is asked to generate N hypothetical questions (default: 3) that the given answer could plausibly be answering. The metric then computes the average cosine similarity between the embeddings of those generated questions and the embedding of the original question. A high score means the answer stays on topic; a low score means the answer is vague or drifted into irrelevant territory.
Context precision: ranking-aware retrieval quality
Context precision measures whether the useful chunks are ranked at the top of your retrieval results. For each chunk in the retrieved set, the judge LLM returns a binary verdict — useful or not useful for answering the question. The score is a weighted average precision that gives more credit to useful chunks appearing early in the list, matching the intuition that a reranker that buries the good chunk at position 10 is worse than one that surfaces it at position 1.
Context recall: coverage against ground truth
Context recall requires a ground-truth reference answer. The judge LLM breaks the reference answer into individual statements and checks whether each statement can be attributed to at least one of the retrieved chunks. The score is attributed_statements / total_statements. A low score means your retriever is missing chunks that contain information the ideal answer depends on.
Running RAGAS: a minimal example
Install RAGAS (requires Python 3.9 or later) and set your judge LLM credentials:
pip install ragas
export OPENAI_API_KEY="sk-..."Build a small EvaluationDataset with one row per query, then call evaluate. Each row needs at minimum: user_input (the question), retrieved_contexts (a list of chunk strings), and response (the generated answer). Add reference to unlock context recall.
from ragas import evaluate, EvaluationDataset
from ragas.metrics import faithfulness, answer_relevancy, context_precision, context_recall
rows = [
{
"user_input": "What is the boiling point of water at sea level?",
"retrieved_contexts": [
"Water boils at 100 degrees Celsius (212 F) at standard sea-level pressure.",
"Altitude lowers atmospheric pressure, which lowers the boiling point.",
],
"response": "Water boils at 100 degrees Celsius at sea level.",
"reference": "The boiling point of water at sea level is 100 degrees Celsius (212 Fahrenheit).",
}
]
dataset = EvaluationDataset.from_list(rows)
result = evaluate(
dataset=dataset,
metrics=[faithfulness, answer_relevancy, context_precision, context_recall],
)
print(result)The evaluate call returns a Result object. Calling print on it shows per-metric means. Call result.to_pandas() to get a DataFrame with per-row scores for debugging.
Reading and acting on the scores
Raw scores only become useful when you read them as a diagnostic pattern rather than a single number. The table below maps the most common score patterns to the root cause and the fix.
| Faithfulness | Answer Relevancy | Context Precision | Context Recall | Diagnosis |
|---|---|---|---|---|
| Low | High | High | High | Generator is hallucinating despite good context — tighten the system prompt |
| High | Low | High | High | Generator is giving vague or padded answers — add conciseness instructions |
| High | High | Low | High | Retriever returns the right info but buries it in noise — improve reranking |
| High | High | High | Low | Retriever misses key chunks — expand chunk count or improve chunking strategy |
| Low | Low | Low | Low | Pipeline is fundamentally misconfigured — check embeddings, prompt, and data |
Score thresholds in practice
There are no universal pass/fail thresholds — the right cutoffs depend on your domain and risk tolerance. A customer-support bot handling refund queries needs much higher faithfulness (0.9+) than an internal brainstorming assistant (0.7 might be fine). Start by measuring your baseline, then set thresholds as deltas from that baseline rather than picking numbers from a blog post.
Integrating scores into your dev loop
The most practical integration is a regression test in CI. Keep a fixed test set of 50–200 representative questions, run RAGAS on every pull request, and block merges if any metric drops below a threshold. This makes evaluation automatic and prevents quiet regressions when you swap embedding models, change chunk sizes, or update system prompts.
Going deeper
Synthetic test set generation
One of RAGAS's most powerful features is its TestsetGenerator. Point it at your document corpus and it automatically generates document-grounded question–answer pairs at multiple difficulty levels (simple factual, multi-hop, abstract). This eliminates the laborious manual work of writing a test set from scratch and ensures the questions are grounded in your actual data rather than generic examples.
from ragas.testset import TestsetGenerator
from langchain_community.document_loaders import DirectoryLoader
loader = DirectoryLoader("./docs", glob="**/*.md")
docs = loader.load()
generator = TestsetGenerator.from_langchain(
generator_llm=your_llm,
critic_llm=your_llm,
embeddings=your_embeddings,
)
testset = generator.generate_with_langchain_docs(docs, testset_size=50)
print(testset.to_pandas())Custom and domain-specific metrics
The four core metrics do not cover every concern. RAGAS also ships metrics for noise sensitivity (does the answer change when irrelevant chunks are injected?), response conciseness, and factual correctness (a reference-based metric using claim matching against a ground-truth answer rather than retrieved context). You can also write fully custom metrics by subclassing MetricWithLLM and supplying your own prompt template and scoring logic.
Calibrating the judge LLM
LLM-as-judge evaluation inherits the biases of the judge model. Research has found that RAGAS faithfulness metrics can show high recall but imprecise verdicts — flagging some correct claims as unsupported. RAGAS addresses this with its align-llm-as-judge workflow: you label a small set of examples yourself, then fine-tune the judge's prompt (or use few-shot examples) to match your labeling style. This calibration step is worth doing before you trust the scores to gate a production deploy.
RAGAS versus other evaluation frameworks
RAGAS competes with frameworks like DeepEval, TruLens, and Braintrust. RAGAS's strength is its RAG-specific metric vocabulary and its tight integration with the LangChain and LlamaIndex ecosystems. DeepEval covers a broader surface (agents, chat, safety) and has better CI/CD tooling. TruLens and LangSmith provide continuous production monitoring, which RAGAS does not. For most teams building a RAG application, RAGAS is the right starting point — it is free, well-documented, and the metric definitions map directly to the two-component (retriever + generator) mental model of RAG.
FAQ
Do I need labeled data to use RAGAS?
For faithfulness and answer relevancy, no — those metrics are reference-free and compare the answer to the retrieved context or the original question. For context recall and context precision (when using ground-truth mode), you need a reference answer per question. RAGAS's TestsetGenerator can produce that reference data synthetically from your documents if you do not have a hand-labeled set.
How expensive is running RAGAS?
Each evaluation row requires roughly 2–5 LLM API calls (one per metric), so cost scales with the size of your test set and the price tier of your judge model. Using a flagship model gives the most reliable verdicts; dropping to a cheaper mini or fast tier cuts cost substantially, though scoring accuracy on nuanced claims drops slightly. Batch the calls and cache results to minimise repeat spend during iterative development.
What is a good RAGAS faithfulness score?
There is no universal threshold — it depends on your application's tolerance for hallucination. Customer-facing pipelines where factual errors are costly should target faithfulness above 0.90. Internal tools or creative assistants can tolerate lower scores. Start by measuring your baseline on a representative sample, then treat drops below that baseline as regressions rather than applying arbitrary cutoffs.
Can I use RAGAS without OpenAI?
Yes. RAGAS accepts any LangChain-compatible chat model as the judge LLM. You can use Anthropic Claude, Google Gemini, Mistral, a locally hosted model via Ollama, or Amazon Bedrock. Pass the model as the llm argument to evaluate(). Very small local models (under 7B parameters) tend to produce noisy verdicts, so prefer a model with strong instruction-following ability.
What is the difference between context precision and context recall in RAGAS?
Context precision measures whether the chunks your retriever returned are actually useful — it penalises noise. Context recall measures whether your retriever found everything necessary — it penalises gaps. You need both: high precision with low recall means you found a clean but incomplete set of chunks; high recall with low precision means all the right chunks are there but buried in irrelevant ones.
How does RAGAS answer relevancy work without a reference answer?
The judge LLM generates three hypothetical questions that the given answer could plausibly be answering, then computes the average cosine similarity between embeddings of those generated questions and the embedding of the original question. If the answer is on-topic and specific, the reverse-engineered questions will closely match the original; if the answer is vague or off-topic, they will diverge.