In plain English
Imagine two sports scouts ranking the same pool of athletes. Scout A ranks them by speed; Scout B ranks them by endurance. Their lists look completely different because the underlying measurements have nothing in common — sprint times are in seconds, VO2 max is in millilitres per kilo per minute. You can't average the raw numbers. But you can look at positions: if the same athlete appears near the top of both lists, they're probably exceptional.
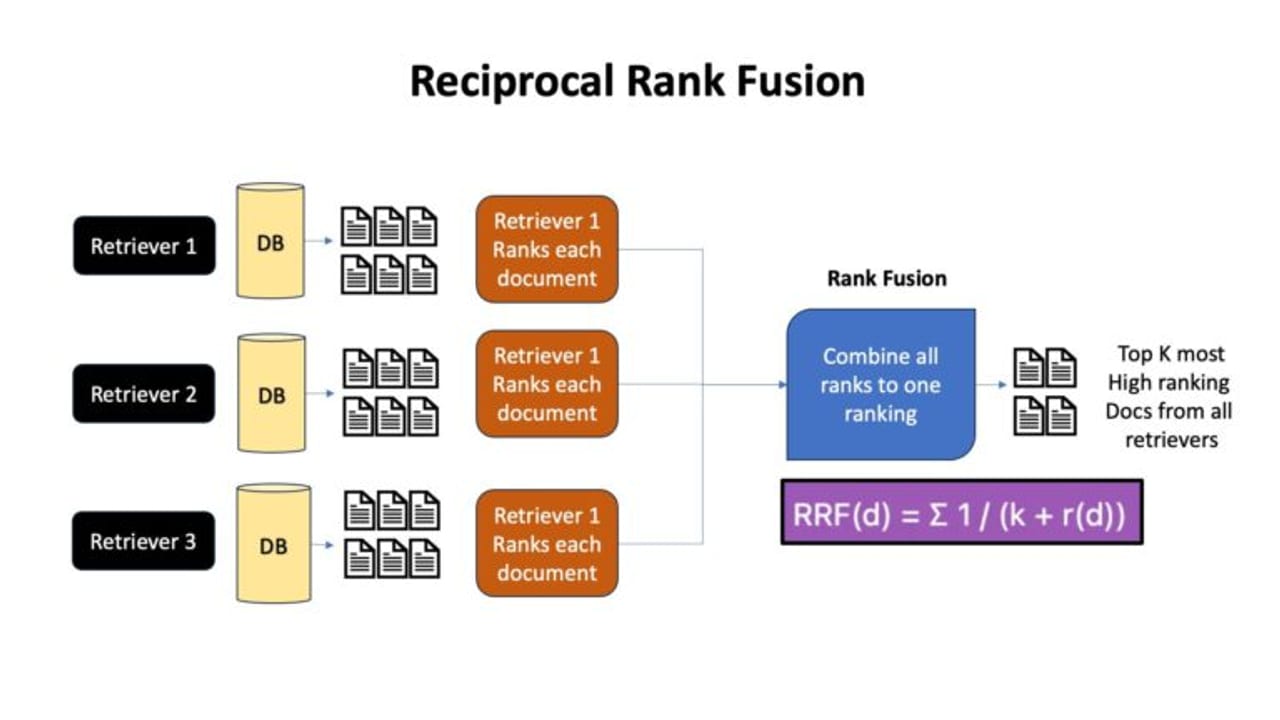
Reciprocal Rank Fusion (RRF) does exactly that for search results. When you run two retrievers — say, a BM25 keyword search and a vector similarity search — each one returns a ranked list with scores that live on completely different scales. A BM25 score of 14.2 and a cosine similarity of 0.87 mean nothing to each other. RRF ignores the raw scores entirely. It converts each document's position in each list into a small contribution value, then sums those contributions across all lists. Documents that appear near the top of multiple lists accumulate the highest totals and win.
The result is a single merged ranking that reflects consensus across retrieval methods. A document that is ranked #1 by the vector search but completely absent from the BM25 list may score lower than a document ranked #8 in both lists. RRF rewards consistency, not dominance in a single dimension.
Why it matters for RAG builders
Retrieval is the most consequential part of a RAG pipeline. If the right document never makes it into the context window, even the most capable LLM cannot answer correctly — it has nothing to work from. The two dominant retrieval strategies have complementary failure modes.
| Retrieval method | Strength | Failure mode |
|---|---|---|
| BM25 (keyword) | Exact match — finds documents with the precise terms from the query | Misses synonyms, paraphrases, and semantically equivalent phrasing |
| Dense vector (embedding) | Semantic match — finds conceptually related content even without shared words | Struggles with rare terms, product codes, version numbers, and proper nouns |
| Hybrid (BM25 + vector) | Catches what either method alone misses | Requires a way to merge the two ranked lists — this is where RRF comes in |
The core problem is score incompatibility. BM25 scores are unbounded positive numbers whose magnitude depends on document length and corpus statistics. Cosine similarity scores are bounded between -1 and 1. Directly adding or averaging these numbers produces nonsense. Early hybrid systems tried min-max normalization or z-score normalization to put scores on a common scale before combining them, but normalization is sensitive to outliers and score distribution — if one BM25 result scores 200 and the rest score between 1 and 5, normalization compresses the useful signal into noise.
RRF sidesteps the normalization problem entirely by discarding raw scores from the moment the lists are created. It operates purely on ordinal ranks, which are always on the same scale: 1st, 2nd, 3rd. This makes it robust, parameter-light, and easy to reason about — properties that matter enormously when you are building a production retrieval system and need to understand why a document ended up in the top five.
How RRF works
The RRF formula for a single document d across N ranked lists is:
RRF(d) = sum over each list i of: 1 / (k + rank_i(d))
where:
rank_i(d) = the 1-based position of document d in list i
(omit the term if d does not appear in list i)
k = a smoothing constant, default 60The constant k is the only tuning parameter. With the widely-adopted default of 60, 1 / (60 + 1) ≈ 0.0164 for the top-ranked document and 1 / (60 + 100) ≈ 0.00625 for the 100th-ranked document. The denominator grows gradually, so the score advantage of rank 1 over rank 2 is small (about 1.6% relative difference), and the difference between rank 1 and rank 60 is about 49%. This gentle decay is intentional: it rewards consistent presence across lists rather than a single pole position.
A worked example
Suppose BM25 returns [Doc-A, Doc-B, Doc-C] and vector search returns [Doc-B, Doc-D, Doc-A]. Using k=60:
| Document | BM25 rank | Vector rank | RRF score | Final rank |
|---|---|---|---|---|
| Doc-A | 1 | 3 | 1/(60+1) + 1/(60+3) = 0.01639 + 0.01587 = 0.03226 | 1st |
| Doc-B | 2 | 1 | 1/(60+2) + 1/(60+1) = 0.01613 + 0.01639 = 0.03252 | 2nd |
| Doc-C | 3 | (absent) | 1/(60+3) = 0.01587 | 4th |
| Doc-D | (absent) | 2 | 1/(60+2) = 0.01613 | 3rd |
Notice that Doc-B, which was ranked #2 by BM25 but #1 by vector search, edges out Doc-A which was #1 by BM25 but only #3 by vector. The algorithm is not simply picking whoever won one list — it is accumulating evidence across both. Doc-C (top-3 keyword match, no vector match) scores lower than Doc-D (top-3 vector match, no keyword match) purely because Doc-D's list position happens to be slightly higher.
Python implementation in seven lines
def reciprocal_rank_fusion(
ranked_lists: list[list[str]],
k: int = 60
) -> list[tuple[str, float]]:
scores: dict[str, float] = {}
for ranked_list in ranked_lists:
for rank, doc_id in enumerate(ranked_list, start=1):
scores[doc_id] = scores.get(doc_id, 0.0) + 1.0 / (k + rank)
return sorted(scores.items(), key=lambda x: x[1], reverse=True)
# Example usage
bm25_results = ["doc-a", "doc-b", "doc-c"]
vector_results = ["doc-b", "doc-d", "doc-a"]
fused = reciprocal_rank_fusion([bm25_results, vector_results])
for doc_id, score in fused:
print(f"{doc_id}: {score:.5f}")RRF in production tools
You rarely need to implement RRF from scratch. Every major search engine and RAG framework now ships it natively, usually as the default fusion strategy for hybrid queries.
Elasticsearch
Elasticsearch uses a rrf retriever that accepts any number of sub-retrievers. The rank_constant parameter maps to k; rank_window_size controls how many candidates each sub-retriever fetches before fusion.
{
"retriever": {
"rrf": {
"retrievers": [
{ "standard": { "query": { "match": { "text": "caching LLM" } } } },
{ "knn": { "field": "embedding", "query_vector": [0.1, 0.4, ...], "k": 10 } }
],
"rank_constant": 60,
"rank_window_size": 100
}
}
}LangChain and LlamaIndex
In LangChain, EnsembleRetriever wraps any two retrievers and uses RRF to merge their outputs. You pass weights to adjust how much each retriever's ranks contribute — this is the weighted variant where each term becomes weight * 1/(k + rank). In LlamaIndex, QueryFusionRetriever with mode="reciprocal_rerank" does the same thing and can also run query expansion (generating multiple query variants before retrieving), fusing all the resulting lists with a single RRF pass.
from langchain.retrievers import EnsembleRetriever, BM25Retriever
from langchain_community.vectorstores import FAISS
bm25_retriever = BM25Retriever.from_documents(docs, k=10)
vector_retriever = FAISS.from_documents(docs, embeddings).as_retriever(k=10)
# RRF is the default fusion strategy; weights adjust per-retriever contribution
ensemble = EnsembleRetriever(
retrievers=[bm25_retriever, vector_retriever],
weights=[0.5, 0.5] # equal contribution from both
)
results = ensemble.invoke("best practices for caching LLM responses")Native database support
Weaviate, Qdrant, Milvus, Azure AI Search, and MariaDB (via the VECTOR engine) all handle RRF natively in their hybrid query APIs. This means the BM25 and vector indexes live in the same system, parallel retrieval and RRF fusion happen server-side in a single round trip, and you never need to fetch two separate result sets and merge them in application code.
Tradeoffs and alternatives
RRF is not the only way to merge ranked lists. Understanding its tradeoffs helps you decide when to use it and when to reach for something else.
What RRF ignores
Because RRF discards raw scores, it cannot distinguish between a BM25 score of 1.2 and a score of 950 — both get the same rank-based contribution. If one document genuinely scores an order of magnitude higher than the others in a single retriever, that signal is completely lost. This matters in highly asymmetric datasets where a single retriever's score distribution contains meaningful information.
Similarly, if the two retrieval lists are completely disjoint — no shared documents at all — RRF degenerates into a simple interleaving of the two lists. The fusion effect only emerges when documents appear in multiple lists. In practice, hybrid retrieval over typical corpora produces substantial overlap in the top-20 results, so this edge case rarely causes problems.
Score normalization approaches
Alternatives to RRF include min-max normalization (rescale each list's scores to [0,1] before summing) and distribution-based score fusion (DBSF), which uses each list's mean and standard deviation to normalize. These approaches preserve score magnitude information that RRF discards, but they are sensitive to outliers: a single anomalously high BM25 score will compress all other BM25 scores toward zero after normalization, introducing exactly the kind of distortion RRF was designed to avoid.
Weighted RRF
The weighted variant replaces the uniform 1/(k + rank) with w_i / (k + rank) where w_i is a per-retriever weight. This lets you express a prior belief — for example, that semantic matches should count twice as much as keyword matches for a particular corpus. Elasticsearch's rrf retriever and LangChain's EnsembleRetriever both support weights. The tradeoff: weights require tuning, and tuning requires labelled evaluation data. Start with equal weights and only deviate when you have evidence from a retrieval evaluation framework like RAGAS or trulens.
- Uses rank position only
- Immune to score scale differences
- Robust to outliers
- Loses within-list magnitude
- k=60 works well out of the box
- Best for: most production hybrid search
- Preserves raw score magnitudes
- Requires compatible score scales
- Sensitive to outliers
- Captures strong vs weak matches
- Requires per-corpus tuning
- Best for: homogeneous retrievers
Going deeper
Once you have basic RRF working, several advanced patterns become relevant at production scale.
RRF over query expansion
RRF is not limited to merging different retrieval methods — it can also merge results from different query variants. Query expansion generates several paraphrases of the original question (using an LLM), runs each variant through the retriever independently, and fuses all N ranked lists with a single RRF pass. This technique, popularised as HyDE (Hypothetical Document Embeddings) and multi-query retrieval, can dramatically improve recall for ambiguous queries by covering different aspects of what the user might mean. LlamaIndex's QueryFusionRetriever supports this pattern natively with num_queries=4.
RRF as a pre-filter before a reranker
RRF and cross-encoder reranking are complementary, not competing. A common production pattern is: (1) run BM25 + vector search, (2) fuse the top-100 with RRF, (3) pass the fused top-20 to a cross-encoder reranker for final precision ordering. RRF handles the score-incompatibility problem cheaply; the reranker handles fine-grained relevance judgement at the cost of higher latency. The two-stage pipeline gets you recall from hybrid retrieval and precision from reranking without paying the latency penalty of running the reranker on all 200 raw candidates.
Tuning k
The constant k=60 was established by Cormack et al. on TREC data and has generalized remarkably well across corpora. Lowering k (e.g., to 1 or 10) makes the scoring steeper: the top-ranked document in each list gains a much larger advantage over lower ranks, so the algorithm behaves more like "trust the winner of each individual list." Raising k (e.g., to 1000) flattens the curve: all positions contribute nearly equal scores and the ranking becomes very flat, essentially ignoring position information. Empirically, values in the range 20–100 behave similarly; only deviate from 60 if your evaluation benchmarks show clear gains.
More than two lists
The RRF formula sums contributions from all lists, so adding a third or fourth retriever is trivially supported. Some advanced RAG setups combine BM25, dense vector, sparse neural (SPLADE), and a knowledge graph retriever, fusing all four with RRF. Each additional list adds marginal computational cost at fusion time (essentially free) but increases the latency of running the additional retriever. Whether the recall improvement justifies the extra retriever latency depends on your latency budget and the diversity of query types your system handles.
FAQ
What does the k=60 constant in RRF actually control?
k sets a floor on the denominator, smoothing the scoring curve so that the difference between rank 1 and rank 2 is small. With k=60, top-ranked documents get a small advantage over lower-ranked ones, and the algorithm rewards consistent presence across lists rather than dominance in one list. The value 60 was tuned empirically by Cormack et al. on TREC data and has generalized well enough that it is now the standard default in Elasticsearch, OpenSearch, and most frameworks.
Does RRF work if a document only appears in one of the two lists?
Yes. If a document appears in only one list, its RRF score is simply 1 / (k + rank) from that single list. Documents that appear in multiple lists accumulate contributions from each, which is why consistent cross-list presence is rewarded. A document absent from all lists gets a score of zero and will not appear in the fused result.
Should I use RRF or a cross-encoder reranker?
They solve different problems and work best together. RRF solves score incompatibility when merging two ranked lists — it is fast, runs at retrieval time, and has negligible latency overhead. A cross-encoder reranker refines the final ordering by reading the query and each candidate document together, giving much higher precision but significant per-document latency. The standard production pattern is to use RRF first to merge BM25 and vector lists, then pass the top-20 fused results to a reranker.
Can I use RRF with more than two retrieval methods?
Yes, RRF naturally extends to any number of ranked lists. The formula sums 1/(k + rank) for every list in which the document appears. Some systems fuse three or four retrievers — BM25, dense embeddings, sparse neural (SPLADE), and a knowledge graph — using a single RRF pass. Each additional retriever adds retrieval latency but negligible fusion latency.
What is weighted RRF and when should I use it?
Weighted RRF multiplies each list's contribution by a per-retriever weight: weight_i / (k + rank). This lets you express a prior belief that one retriever is more reliable for your corpus. In practice, start with equal weights (0.5/0.5 for two retrievers) and only tune if you have labelled evaluation data showing that one retriever consistently contributes better results. Without measurement, tuned weights often underperform the simple equal-weight baseline.
Does RRF work for combining results from multiple query variants?
Yes. RRF is equally effective at fusing results from different queries run through the same retriever as it is at fusing results from different retrievers for the same query. Query expansion techniques — where an LLM generates 3-5 paraphrases of the original question — use RRF to merge the N result lists into one. This improves recall for ambiguous queries by covering different aspects of meaning, and it is supported natively in LlamaIndex's QueryFusionRetriever.