In plain English
Hybrid search runs two kinds of search at the same time — one that looks for your exact words and one that looks for your meaning — then merges both ranked lists into a single result. You get the best of both worlds: the precision of keyword matching and the flexibility of semantic understanding.
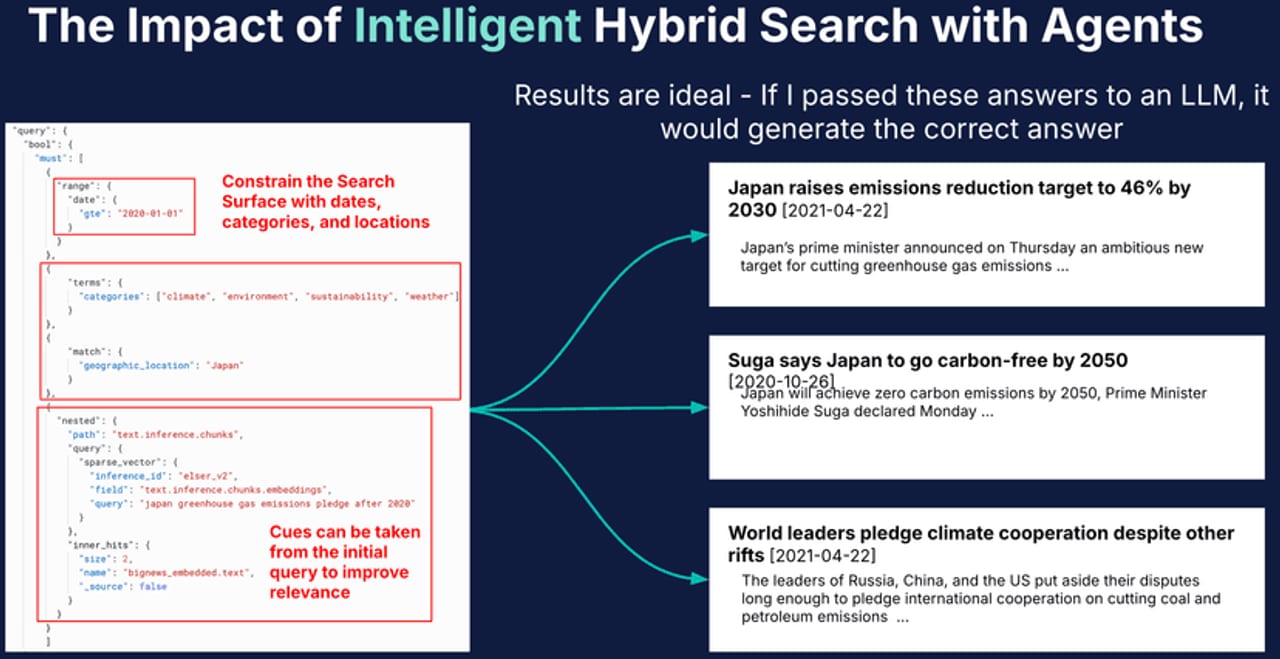
Here's a concrete analogy. Imagine you're looking for a legal contract in a filing cabinet. A keyword search is like checking the label on each folder — it finds "Agreement for Services" instantly if that exact phrase is on the tab, but it misses the folder labelled "SOW" (Statement of Work) even though it's the same thing. A semantic search is like asking a colleague who has read every folder — they find the SOW immediately because they understand what you mean, but they sometimes grab a loosely related contract that doesn't have the terms you need verbatim. Hybrid search does both: it checks labels and asks the colleague, then combines what each found.
In technical terms: the "check labels" side is BM25, a classic keyword-scoring algorithm used in search engines for decades. The "ask the colleague" side is vector search, which converts text into dense numerical embeddings and finds the closest matches by meaning. Hybrid search runs both in parallel, then fuses the two ranked lists — typically using a lightweight algorithm called Reciprocal Rank Fusion (RRF) — into one final ranking.
Why it matters
The fundamental problem is that keyword search and vector search fail in opposite directions. Neither is universally better, but together they cover almost everything.
Where pure vector search breaks down. Embedding models are trained to capture meaning, but they are surprisingly bad at rare, specific tokens. A product SKU like RTX-4090-FE, an error code like ERR_CERT_INVALID, a person's name, or a version string like v2.14.3 gets smeared into the surrounding semantic neighborhood. The embedder has never seen RTX-4090-FE enough times to give it a stable location in embedding space, so cosine similarity to that string is essentially noise. A pure vector RAG system will have a systematic blind spot for exactly these identifiers — and identifiers are often the most important part of a user's query.
Where pure keyword search breaks down. BM25 only fires on literal term overlap. A user who asks "how do I cancel my account?" gets zero matches against a document titled "Closing your subscription" — zero shared content words, zero score. The same knowledge base may answer the question perfectly, but BM25 will never surface it. Synonyms, paraphrases, and intent all require a semantic layer.
The result is that empirical benchmarks consistently show hybrid search outperforming either method alone. On standard information-retrieval benchmarks, pure BM25 and pure vector search score similarly — around NDCG 0.70 — while a well-tuned hybrid reaches 0.75 or higher, a roughly 7% lift that is large by IR standards. More strikingly, recall@10 numbers from production-style evals show dense-only at 78%, sparse-only at 65%, and hybrid at 91%.
- Docs chatbots and internal Q&A. Users ask natural-language questions but also search by product names, ticket IDs, and version numbers. Only hybrid covers both.
- E-commerce and catalog search. Queries mix intent ("comfortable running shoes") with exact attributes ("Nike Air Zoom Pegasus 41"). Keyword retrieval handles the SKU; vector retrieval handles the intent.
- Code and technical documentation. Queries over APIs mix function names (
torch.nn.CrossEntropyLoss) with conceptual questions ("loss function for multi-class classification"). Hybrid handles both. - Legal and compliance search. Statutory citations require exact matches; intent-based questions require semantic understanding. A hybrid system handles "Article 17 GDPR" and "right to be forgotten" as the same underlying regulation.
How it works
At query time, hybrid search runs two independent searches in parallel, then merges the results. Here is the full pipeline:
Step 1 — Sparse retrieval with BM25
BM25 (Best Match 25) scores each document chunk based on how often query terms appear in it, weighted by term rarity across the whole corpus. A term that appears in 5% of documents is worth far more than one that appears in 95%. BM25 also applies a saturation curve so that repeating a term ten times adds less and less to the score — it avoids rewarding keyword stuffing. The underlying data structure is an inverted index: a mapping from each vocabulary word to the list of chunks that contain it. Lookups are extremely fast — sub-millisecond at millions of chunks — and require no GPU.
Step 2 — Dense retrieval with embeddings
The query is run through an embedding model (e.g., text-embedding-3-small, sentence-transformers/all-MiniLM-L6-v2, or Cohere Embed) to produce a dense vector — a list of several hundred floating-point numbers. The vector database (Pinecone, Weaviate, Qdrant, Milvus, pgvector, etc.) then performs an approximate nearest-neighbor (ANN) search to find the chunk vectors closest to the query vector by cosine similarity. Ingestion is the expensive part: every chunk must be embedded and indexed before queries start. ANN search itself is fast — typically 10–50ms.
Step 3 — Reciprocal Rank Fusion
The core problem with merging the two result lists is score incompatibility: a BM25 score of 14.3 and a cosine similarity of 0.87 live on completely different scales and cannot be meaningfully added. Normalizing the raw scores (e.g., min-max) is fragile — an outlier document can shift the normalization and distort every other score. Reciprocal Rank Fusion (RRF) solves this elegantly by ignoring raw scores entirely and working only with ranks.
The RRF formula for each document d is:
RRF_score(d) = sum over each ranker r of: 1 / (k + rank_r(d))
where:
rank_r(d) = position of document d in ranker r's list (1-indexed)
k = smoothing constant, conventionally 60A document ranked #1 by either retriever earns 1 / (60 + 1) ≈ 0.0164. One ranked #10 earns 1 / (60 + 10) ≈ 0.0143. A document that ranks well in both lists accumulates contributions from both rankers and rises to the top. The constant k = 60 is the empirically validated sweet spot from Cormack et al. (2009): it prevents a single rank-1 result from completely dominating and gives lower-ranked results a meaningful voice. Most production systems (Azure AI Search, Elasticsearch, Weaviate, Supabase) ship with k = 60 as the default.
- Exact product codes and SKUs
- Error codes and version strings
- Proper nouns and acronyms
- No model, no GPU needed
- Fails on synonyms and paraphrases
- Synonyms and paraphrases
- Intent and concept matching
- Cross-lingual queries
- Requires embedding model
- Fails on unseen exact tokens
- Handles both of the above
- Higher recall@10 in benchmarks
- RRF avoids score normalization
- More infrastructure to operate
- Gold standard for production RAG
Implementing hybrid search
Every major retrieval platform now has native hybrid search support. Here is a quick overview of the main options:
| Platform | Sparse method | Fusion default | Notes |
|---|---|---|---|
| Weaviate | BM25F | relativeScoreFusion (v1.24+), RRF available | alpha=0 → pure BM25, alpha=1 → pure vector, default 0.75 |
| Elasticsearch / OpenSearch | BM25 | RRF (8.9+) | native knn + query combined; RRF constant tunable |
| Azure AI Search | BM25 | RRF (k=60) | hybrid mode merges full-text and vector indexes automatically |
| Pinecone | BM25 or SPLADE (sparse-dense) | Linear combination | requires sparse+dense index; LangChain retriever wrapper available |
| Qdrant | BM25 via sparse vectors | RRF or weighted sum | sparse vectors stored alongside dense; query fused at retrieval |
| pgvector + pg_search | BM25 (ParadeDB) | Custom RRF SQL | pure Postgres; RRF computed in a SQL CTE |
If you are building from scratch, here is a minimal self-contained hybrid search implementation in Python — no framework, so every step is visible:
from rank_bm25 import BM25Okapi # pip install rank-bm25
from sentence_transformers import SentenceTransformer, util
# --- Sample corpus (in production: database of chunked docs) ---
chunks = [
"To cancel your subscription, visit Account Settings > Billing.",
"The refund policy covers purchases within 30 days.",
"Closing your account permanently removes all data.",
"Contact support at help@example.com for billing issues.",
"The API endpoint is POST /v1/subscriptions/{id}/cancel.",
]
# --- Build sparse index (BM25) ---
bm25 = BM25Okapi([c.lower().split() for c in chunks])
# --- Build dense index (embeddings) ---
model = SentenceTransformer("all-MiniLM-L6-v2")
chunk_embeddings = model.encode(chunks, convert_to_tensor=True)
RRF_K = 60 # conventional constant
def hybrid_search(query: str, top_k: int = 3) -> list[str]:
# --- Sparse: rank by BM25 score ---
bm25_scores = bm25.get_scores(query.lower().split())
sparse_ranked = sorted(range(len(chunks)),
key=lambda i: bm25_scores[i], reverse=True)
# --- Dense: rank by cosine similarity ---
q_vec = model.encode(query, convert_to_tensor=True)
sims = util.cos_sim(q_vec, chunk_embeddings)[0]
dense_ranked = sorted(range(len(chunks)),
key=lambda i: float(sims[i]), reverse=True)
# --- Reciprocal Rank Fusion ---
rrf_scores: dict[int, float] = {}
for ranked_list in (sparse_ranked, dense_ranked):
for rank, idx in enumerate(ranked_list): # rank 0-indexed here
rrf_scores[idx] = rrf_scores.get(idx, 0.0) + 1.0 / (RRF_K + rank + 1)
top = sorted(rrf_scores, key=rrf_scores.__getitem__, reverse=True)[:top_k]
return [chunks[i] for i in top]
# "cancel" is in chunks[0] and [4] literally; chunks[2] is a semantic match
print(hybrid_search("how do I cancel my account?"))Running the query "how do I cancel my account?" surfaces chunks 0, 2, and 4 — the billing settings chunk (exact word "cancel"), the account-closure chunk (semantic match for "cancel account"), and the API endpoint chunk (exact word "cancel"). A pure vector search would likely demote or miss the API endpoint because the phrase POST /v1/subscriptions/{id}/cancel does not embed close to the natural-language question. BM25 catches the literal token; RRF ensures neither retriever is ignored.
Tuning and common pitfalls
Hybrid search is almost always better than either alone, but it does not work magic out of the box. These are the real failure modes teams run into.
Choosing between RRF and weighted linear combination
RRF is rank-based, needs no tuning, and is robust across query types and corpus distributions. It is the safe default — use it unless you have a specific reason not to. Linear combination (final = alpha * bm25_norm + (1 - alpha) * vector_norm) is more expressive but brittle: it requires reliable score normalization (min-max or z-score) and a tuned alpha. Normalizing BM25 scores is sensitive to outliers — a single unusually long document can shift the min-max range. Unless you have an offline evaluation pipeline with NDCG metrics and regular recalibration, stick with RRF.
Tuning alpha when you use weighted fusion
If your platform uses weighted fusion, alpha controls the balance. Higher alpha means "trust the vector more"; lower alpha means "trust BM25 more." Typical starting values: alpha = 0.7 for general prose Q&A (favor semantics); alpha = 0.3 to 0.4 for legal or technical documentation where exact term precision is paramount. Always tune on a held-out evaluation set — the right value depends on your specific corpus and query distribution.
Embedding model mismatch
Every chunk in your index must be embedded with the same model you use to embed queries at retrieval time. Switch embedding models (e.g., upgrade from text-embedding-ada-002 to text-embedding-3-large) and you must re-embed and re-index your entire corpus. Vectors from two different models live in different spaces; cosine similarity between them is meaningless.
Not adding a reranker on top
Hybrid search improves recall — more of the right documents make the top-k. But it does not guarantee the best document is ranked first. A cross-encoder reranker (Cohere Rerank, BGE-Reranker, FlashRank) reads the query and each candidate together, giving much more accurate ordering. The standard production pattern is: hybrid retrieval to fetch top-50, then reranker to return top-5. Hybrid handles recall cheaply; the reranker handles precision precisely.
- No evaluation baseline. Running hybrid search without measuring recall@k tells you nothing. Establish a baseline first — even 50 query-answer pairs annotated by hand.
- BM25 not indexed on the right fields. If you store chunk text plus metadata (source, date, category), make sure the BM25 index covers only the content field, not metadata noise.
- Chunk size still wrong. Hybrid search cannot rescue retrieval from bad chunking. If your chunks are too large or split across sentence boundaries, both BM25 and vector scores will be noisy.
- Ignoring query preprocessing. Lowercasing, removing stop words, and stripping punctuation before BM25 scoring can noticeably improve sparse recall for free.
Going deeper
The hybrid search pattern is stable, but the components inside it continue to evolve. Understanding the frontier helps you choose where to invest.
Learned sparse retrieval: SPLADE and beyond
SPLADE (Sparse Lexical and Expansion model) is a middle path between BM25 and dense vectors. It uses a transformer to produce a sparse vector over the vocabulary — like BM25's inverted index — but it learns which terms to weight and even expands documents with related terms that never appeared in them. A chunk about "closing an account" might be assigned high weight on the term "cancel" even if that word is absent. SPLADE indexes in standard inverted-index machinery (fast, no GPU at query time) but retrieves semantically. It is a direct drop-in replacement for the sparse side of a hybrid pipeline and often outperforms BM25 while keeping the exact-match strengths.
ColBERT and late interaction
Standard dense retrieval encodes each document down to a single vector. ColBERT keeps a separate vector for every token in both the query and the document, and scores them with a MaxSim operator — for each query token, find the closest document token. This "late interaction" architecture is noticeably more accurate than bi-encoders because matching happens at token granularity, not document granularity. The cost is storage: a 200-token chunk needs 200 vectors instead of one. ColBERT is used in production retrieval stacks (e.g., RAGatouille library) where precision is critical and storage budget allows.
Query expansion and HyDE
Both retrieval sides benefit from a better query. Query expansion uses an LLM to rewrite a terse query into a richer one before retrieval — turning "refund?" into "What is the refund and return policy for purchases?" — improving recall on both BM25 (more terms to match) and vector search (closer to document phrasing). HyDE (Hypothetical Document Embeddings) takes this further: the LLM writes a fake answer to the question, and that hypothetical answer is embedded and used as the dense query vector. Because a hypothetical answer is phrased more like the real source document than the original question is, HyDE often outperforms direct query embedding.
Multi-vector hybrid retrieval
Production RAG systems often go beyond a single query to retrieve. Multi-query retrieval generates several paraphrases of the original question, retrieves for each, unions the result sets, deduplicates, then reranks. This dramatically improves recall on ambiguous queries — the variants cover the semantic neighborhood from different angles. Combined with hybrid search for each individual query, multi-query retrieval is the state-of-the-art pattern for high-recall RAG before a final reranking pass.
Freshness and re-indexing
Hybrid search does not change the freshness problem, but it makes it slightly more complex: you have two indexes to keep in sync — the inverted index (BM25) and the vector index. Most platforms expose incremental upsert APIs so individual chunks can be updated without full re-indexing, but you need to ensure both indexes are updated atomically or queries can get stale results from one while the other is current. This is a common operational bug in production hybrid search pipelines.
FAQ
What is the difference between hybrid search and vector search?
Vector search uses only embeddings to find semantically similar chunks, and it can miss queries that rely on exact keyword matches (product codes, error codes, names). Hybrid search runs vector search plus BM25 keyword search in parallel and merges both result lists — so it handles both exact-match and meaning-based queries. Vector search is a component of hybrid search, not an alternative to it.
Do I need hybrid search or is vector search enough?
If your users only ask natural-language questions about prose content with no specific identifiers, pure vector search is often sufficient. But as soon as queries include product SKUs, error codes, version strings, names, or acronyms — or if your corpus is technical documentation — pure vector search will have systematic blind spots. Hybrid search is the safer default for production systems because it costs little extra and eliminates the entire class of exact-token failures.
How does Reciprocal Rank Fusion (RRF) work?
RRF scores each document by summing 1 / (k + rank) across all rankers, where rank is the document's position in each ranked list and k = 60 is a smoothing constant. Documents that appear near the top in both BM25 and vector results accumulate high scores and float to the top of the merged list. RRF works on ranks not raw scores, so it sidesteps the problem of BM25 and cosine similarity living on different numeric scales.
What is the alpha parameter in hybrid search?
Some platforms (Weaviate, Pinecone) use a weighted linear combination of normalized BM25 and vector scores rather than RRF. The alpha parameter controls the balance: alpha=0 uses only BM25, alpha=1 uses only vector search, and alpha=0.5 weights them equally. Weaviate defaults to alpha=0.75 (favoring vector). If your queries are more technical or identifier-heavy, lower alpha toward 0.3–0.4; for conversational Q&A, keep it at 0.7 or higher.
Does hybrid search replace a reranker?
No — they solve different problems. Hybrid search improves recall: more of the right documents make the top-k candidate list. A reranker improves precision: it re-orders the candidates so the single best chunk comes first. The standard two-stage pattern is hybrid retrieval to fetch the top-50, then a cross-encoder reranker to return the top-5. Skipping the reranker is fine for simpler use cases, but the combination is the gold standard for precision.
Which databases support hybrid search natively?
As of mid-2026, native hybrid search (BM25 + vector + fusion) is built into Weaviate, Elasticsearch/OpenSearch, Azure AI Search, Qdrant, Milvus, and Pinecone (via sparse-dense indexes). PostgreSQL users can achieve the same via the pgvector extension for vectors and pg_search (ParadeDB) or ts_rank for BM25, fused with a SQL CTE. LangChain and LlamaIndex both ship retriever abstractions that wrap these backends.