In plain English
Imagine two ways to decide whether a book answers your question. In the first approach, a librarian reads every book once and writes a summary card for each. When you arrive with your question, they write a summary card for you too, then flip through the card file looking for summary cards that match yours. Fast, scalable, but accuracy is limited by how much a summary card captures.
In the second approach, the librarian sits down with your question and one candidate book at a time, reading them side by side to judge relevance directly. Slow — you couldn't do it for ten thousand books — but extremely accurate for the few books you do check.
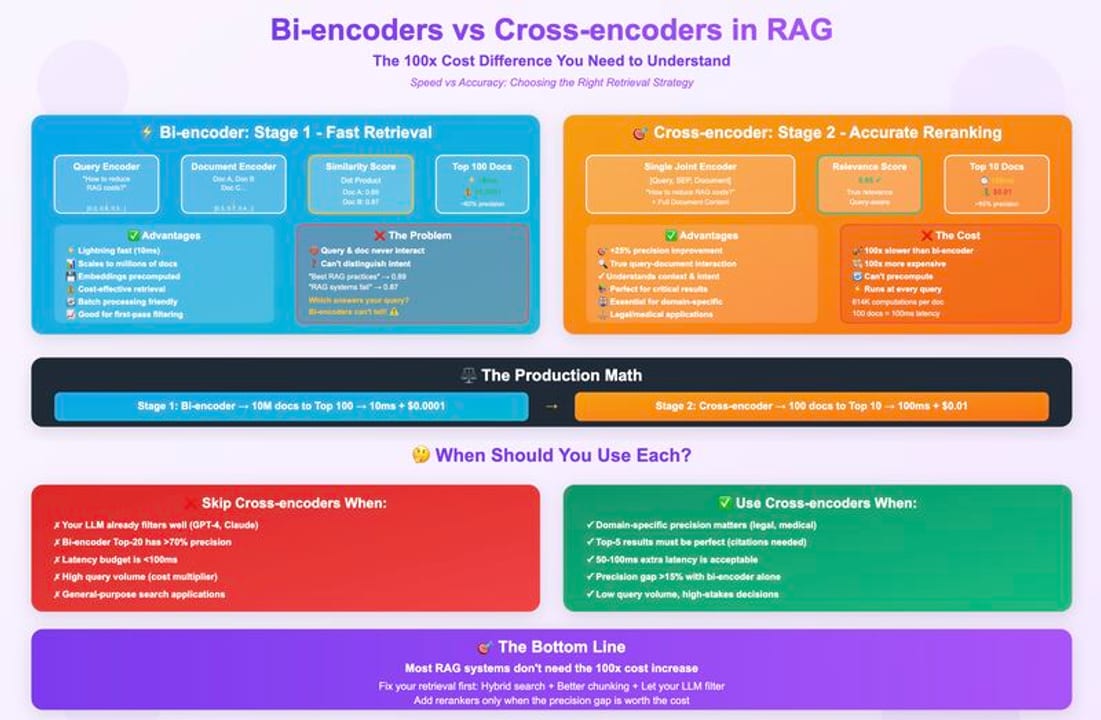
Those two approaches are exactly bi-encoder and cross-encoder architectures. A bi-encoder encodes the query into a vector and each document into a vector independently; relevance is the geometric distance between those vectors. A cross-encoder takes a (query, document) pair and processes both together through a single transformer, producing one relevance score by letting every query token attend to every document token from layer one.
Why it matters
Every production RAG system must answer two questions that pull in opposite directions: "can I search millions of chunks in under 10 ms?" and "can I rank those chunks with near-human relevance judgment?" The first demands pre-computation; the second demands joint reasoning. No single architecture satisfies both.
Understanding the architectural split explains why the retrieve-then-rerank pattern exists and why it is essentially universal in serious search and RAG systems today. If you try to skip the bi-encoder and rerank everything from scratch with a cross-encoder, you face one full transformer forward pass per document at query time — completely infeasible at scale. If you rely only on a bi-encoder and skip the reranker, you accept embedding-space distance as a proxy for relevance, which fails on subtle, multi-hop, or negation-heavy queries.
The practical stakes are high. Studies comparing naive top-k retrieval against two-stage retrieve-then-rerank show accuracy gains of 20–40 percentage points on complex question-answering benchmarks. Bi-encoder retrieval typically achieves 65–80% relevance accuracy on complex queries; adding a cross-encoder reranker raises that to 85–90% on web search benchmarks. More importantly, the biggest gains occur precisely where RAG fails hardest: queries where several chunks look superficially similar but only one is actually correct.
- RAG system builders need to know where to plug in each model and why the two stages cannot be merged into one.
- Search engineers choose embedding models knowing their real limitation is not size or speed but the absence of cross-attention at query time.
- LLM application developers waste token budget when they pass 50 bi-encoder-ranked chunks straight to the LLM instead of reranking to 5.
- Anyone fine-tuning or evaluating retrieval needs to know that NDCG and recall measure different things for the two stages.
How it works
Bi-encoder: late interaction via vector distance
A bi-encoder is two transformer encoders that share weights (or are separately trained to embed into a common space). The query goes through one pass, each document through another pass, and both emerge as fixed-size dense vectors — typically 768 or 1536 dimensions. Relevance is computed as cosine similarity (or dot product) between the query vector and each document vector.
The critical word is late: query and document only interact at the very last step, when you compute a single number from their two vectors. Every layer of self-attention inside the transformer operates on tokens from one input at a time. The query representation never "sees" the document during encoding, and vice versa. This is what makes pre-computation possible: you encode every document offline, store the vectors in a vector database, and at query time you only need to encode the query (one fast forward pass) and then run an approximate nearest-neighbor search. The documents are already ready.
- Query → Transformer → query_vec
- Doc → Transformer → doc_vec
- score = cosine(query_vec, doc_vec)
- Interaction: LATE (only at score step)
- Docs pre-encoded offline
- Query time: encode query + ANN search
- Speed: ~5 ms regardless of corpus size
- [CLS] query [SEP] doc [SEP] → Transformer
- score = linear([CLS] embedding)
- Interaction: EARLY (every attention layer)
- No pre-computation possible
- Query time: one forward pass per candidate
- Speed: ~5–10 ms per (query, doc) pair
- Must pre-filter with bi-encoder first
Cross-encoder: early interaction via joint attention
A cross-encoder concatenates the query and a single document into one sequence — [CLS] <query tokens> [SEP] <document tokens> [SEP] — and runs a single transformer forward pass over the full combined sequence. In every self-attention layer, every query token can attend to every document token and vice versa. The model learns to use these cross-attention patterns to detect exact matches, negation, co-reference, and subtle topical dependencies that bi-encoder distance cannot capture.
The output of the [CLS] token from the final transformer layer is fed into a single linear head that outputs one number: the relevance score. Research shows that early-to-middle layers primarily perform lexical matching (query token X attends to the same word in the document), while middle-to-late layers aggregate those signals into semantic relevance judgments. The score is therefore not a distance — it is a direct prediction of relevance, trained end-to-end on human-annotated or click-based relevance labels.
Speed vs accuracy tradeoffs
The core engineering decision is how many candidates to retrieve and how many to rerank. Those two numbers drive the latency budget of your pipeline and the accuracy ceiling you can reach.
| Stage | Model example | Latency (50 docs) | Accuracy |
|---|---|---|---|
| Bi-encoder retrieval | text-embedding-3-large, E5-large | ~5 ms (ANN lookup) | Moderate — optimized for recall |
| Cross-encoder rerank (CPU) | cross-encoder/ms-marco-MiniLM-L-6-v2 | 100–250 ms | High — joint attention |
| Cross-encoder rerank (GPU) | BGE-Reranker-v2-m3 | 15–50 ms | High — joint attention |
| Managed API rerank | Cohere Rerank 4 Pro, Jina Reranker v2 | 150–400 ms (incl. network) | Highest — large model, multilingual |
A practical rule of thumb that has emerged in production RAG systems: retrieve the top 50–100 candidates with the bi-encoder (maximizes recall), rerank with the cross-encoder and keep the top 5–10 (maximizes precision for the LLM). Retrieving fewer than 50 risks leaving the right answer outside the reranker's view; passing more than 100 to the reranker makes it slow without meaningfully improving final quality.
One subtlety that trips up builders: a perfect reranker cannot rescue a poor retriever. If the correct chunk is ranked 150th by your bi-encoder and you only pass the top 50 to the reranker, that chunk is invisible. Reranking improves ordering within the candidate set; it cannot expand the candidate set. Improving bi-encoder recall (better embedding model, hybrid search with BM25, query expansion) and improving cross-encoder precision are complementary investments, not substitutes.
Choosing the right model for each stage
Bi-encoder (embedding) models
For the retrieval stage, the most widely deployed open-source bi-encoders are E5-large-v2 and text-embedding-ada-002 (or its successor text-embedding-3-large) from OpenAI. For self-hosted deployments, BAAI/bge-large-en-v1.5 and intfloat/e5-mistral-7b-instruct rank near the top of the MTEB (Massive Text Embedding Benchmark) leaderboard. Bi-encoder quality is best measured by recall@k — what fraction of the time does the ground-truth chunk appear in the top-k results?
Cross-encoder (reranker) models
For the reranking stage, cross-encoder/ms-marco-MiniLM-L-6-v2 from the Sentence Transformers library is the standard self-hosted starting point: ~66 MB, runs on CPU, strong English Q&A quality. For multilingual or higher-accuracy requirements, BAAI/bge-reranker-v2-m3 and jinaai/jina-reranker-v2-base-multilingual are leading open-weight options in 2025–2026. For managed APIs, Cohere Rerank 4 Pro (32K context, 100+ languages, BEIR top-tier) and Jina Reranker v2 API are the dominant choices.
from sentence_transformers import SentenceTransformer, CrossEncoder
import numpy as np
# --- Stage 1: Bi-encoder retrieval ---
bi_encoder = SentenceTransformer("BAAI/bge-large-en-v1.5")
# Pre-compute document embeddings (done offline, stored in a vector DB)
documents = [
"GPT-5.5 supports function calling via the tools parameter.",
"GPT-5.5 is a multimodal model in the GPT-5 family.",
"Function calling was first introduced in earlier GPT-3.5 models.",
"GPT-5.5 supports a large context window for long inputs.",
"Structured outputs guarantee JSON schema compliance in GPT-5.5.",
]
doc_embeddings = bi_encoder.encode(documents, normalize_embeddings=True)
query = "does GPT-5.5 support function calling?"
query_embedding = bi_encoder.encode(query, normalize_embeddings=True)
# Cosine similarity = dot product on normalized vectors
scores = np.dot(doc_embeddings, query_embedding)
top_k_indices = np.argsort(scores)[::-1][:4] # top 4 candidates
candidates = [documents[i] for i in top_k_indices]
print("Stage 1 — bi-encoder top 4:")
for i, doc in enumerate(candidates):
print(f" {i+1}. {doc}")
# --- Stage 2: Cross-encoder reranking ---
cross_encoder = CrossEncoder("cross-encoder/ms-marco-MiniLM-L-6-v2")
pairs = [(query, doc) for doc in candidates]
rerank_scores = cross_encoder.predict(pairs)
ranked = sorted(zip(rerank_scores, candidates), reverse=True)
print("\nStage 2 — cross-encoder reranked top 2:")
for score, doc in ranked[:2]:
print(f" [{score:.3f}] {doc}")The code above illustrates the key structural difference: the bi-encoder's encode() calls can be cached (line 12), so at query time you only encode the query. The cross-encoder's predict() call (line 28) must receive the full (query, doc) pairs at query time — there is no caching because the model has never seen this particular query before and cannot pre-compute anything about how the document relates to it.
Going deeper
The bi-encoder / cross-encoder split is not binary. Researchers have explored a spectrum of architectures that trade off pre-computation against interaction depth. ColBERT (Contextualized Late Interaction over BERT) sits between the two: it encodes query and document separately like a bi-encoder, but instead of compressing each into a single vector, it retains one contextualized vector per token. At query time it computes a MaxSim score — for each query token, find its most similar document token, then sum those similarities — capturing token-level matching without full cross-attention. ColBERT achieves accuracy close to cross-encoders while being two orders of magnitude faster at reranking, though at the cost of much larger indexes (one vector per token rather than one per document).
Listwise reranking is a growing alternative to pairwise cross-encoder scoring. Instead of running one forward pass per (query, doc) pair, you send all N candidates to an LLM in a single prompt and ask it to return a ranked order. This lets the model reason about relative relevance — "document A is more specific than B" — which pairwise scoring misses. The tradeoff is cost: one large LLM call versus N small cross-encoder calls. As LLM inference costs fall, listwise approaches are becoming competitive for offline or asynchronous pipelines.
Training data quality matters more than architecture for both stages. Bi-encoders benefit enormously from hard negative mining — training pairs where the negative document is semantically close but incorrect (retrieved by the model itself), forcing the model to push their representations further apart. Cross-encoders benefit from diverse labeling: models trained on click data, downstream answer quality signals, or domain-specific relevance labels consistently outperform those trained on annotation alone. If you are fine-tuning either stage on your own corpus, generating hard negatives from your existing bi-encoder's top-k results is the single highest-ROI improvement you can make.
A recurring practical confusion: embedding similarity scores are not calibrated probabilities. A cosine similarity of 0.92 from a bi-encoder does not mean 92% relevant, and a cross-encoder logit of 8.3 does not mean anything absolute either. The scores are only meaningful relative to each other within a single query's candidate set. Cross-encoder scores are more meaningful for cross-query comparison because the joint encoding normalizes for query difficulty, but they are still not directly comparable across different models. When building evaluation pipelines, always compare ranked orderings (NDCG, MAP) rather than absolute score thresholds.
Finally, context length is reshaping both stages. Bi-encoders are being pushed to handle longer inputs (e.g., Jina Embeddings v3 supports up to 8,192 tokens), reducing the need for aggressive chunking. Cross-encoders like Cohere Rerank 4 Pro support 32K-token inputs, enabling reranking of full documents rather than paragraphs. This opens the door to "retrieve documents, rerank documents, extract the answer" pipelines that skip chunk-level retrieval entirely — a fundamental inversion of the traditional RAG architecture whose empirical advantages are still being mapped out.
FAQ
Why can't I just use a cross-encoder for all retrieval instead of a bi-encoder?
A cross-encoder requires one full transformer forward pass for every (query, document) pair. For a corpus of 100,000 chunks, that is 100,000 forward passes at query time — easily several minutes of compute. A bi-encoder pre-computes all document embeddings offline and reduces query time to a single embedding plus a millisecond vector search. The bi-encoder is not more accurate; it is the only approach that scales.
Is the bi-encoder the same as the embedding model I use to index documents in a vector database?
Yes, exactly. When you call openai.embeddings.create() or sentence_transformers.encode() to turn your chunks into vectors before inserting them into Pinecone, Qdrant, or Weaviate, you are using a bi-encoder. The query embedding you generate at search time is also produced by the same bi-encoder. The vector database's ANN index is then the mechanism that makes bi-encoder retrieval fast at scale.
How many candidates should I retrieve before reranking?
A widely used rule of thumb is to retrieve the top 50–100 candidates with the bi-encoder, rerank them all, and pass the top 5–10 to the LLM. Retrieving fewer than 50 risks the correct chunk falling outside the reranker's view. Reranking more than 100 adds significant latency without proportionally improving final accuracy. The right number depends on your corpus density and query complexity.
What is the difference between a cross-encoder relevance score and a cosine similarity score?
Cosine similarity is a geometric distance between two independently produced vectors — it measures whether two embeddings point in a similar direction. A cross-encoder relevance score is the output of a linear layer on top of a transformer that jointly read both the query and document — it directly predicts relevance, not geometric proximity. Cross-encoder scores are better calibrated for ranking but are not comparable across queries or models; they are only meaningful relative to other scores from the same query run.
Does ColBERT replace both bi-encoders and cross-encoders?
ColBERT is a middle-ground architecture: it pre-encodes documents (like a bi-encoder) but retains per-token vectors instead of a single vector, then scores via token-level MaxSim at query time (closer to cross-encoder expressivity). In practice it achieves accuracy close to cross-encoders while being far faster for reranking, but its indexes are much larger — roughly one vector per token per document. Most production pipelines still use a standard bi-encoder for first-stage retrieval due to simpler infrastructure, and add either ColBERT or a standard cross-encoder for reranking.
Can I fine-tune a bi-encoder or cross-encoder on my own data?
Yes, and domain fine-tuning often delivers the largest accuracy gains — more so than switching to a bigger base model. For bi-encoders, the standard approach is contrastive learning with hard negatives mined from your existing retriever's top-k results. For cross-encoders, you need (query, positive_doc, negative_doc) triples. The Sentence Transformers library provides training utilities for both. Even a small fine-tuning run on a few thousand domain-specific pairs can close the gap between a general-purpose model and one explicitly trained on your corpus structure.