
Overview
DeepSeek-V4-Pro is the larger of the two models in DeepSeek's V4 series, released as a preview on 24 April 2026. It is a Mixture-of-Experts language model with 1.6 trillion total parameters and 49 billion activated per token, and it supports a context length of one million tokens. The smaller sibling in the series is DeepSeek-V4-Flash (284B total / 13B active).
The model introduces a Hybrid Attention Architecture that combines Compressed Sparse Attention and Heavily Compressed Attention to make long-context inference far cheaper than V3: in the 1M-token setting DeepSeek reports it needs only about 27% of the single-token inference FLOPs of the prior generation. It was trained on more than 32 trillion tokens and uses techniques including Manifold-Constrained Hyper-Connections and the Muon optimizer.
DeepSeek-V4-Pro exposes three reasoning-effort modes — Non-think, Think High, and Think Max — where 'Think Max' (sometimes referred to as V4-Pro-Max) applies the highest reasoning budget. All weights are released under the MIT License and published on Hugging Face, making the model fully open for local deployment and commercial use.
| Released | 2026-04-24 |
|---|---|
| License | MIT |
| Weights | Open weights |
| Parameters | 1.6T total · 49B active |
| Context | 1M |
| Architecture | Mixture-of-Experts |
| Modalities | Text |
| Status | Preview |
Benchmarks
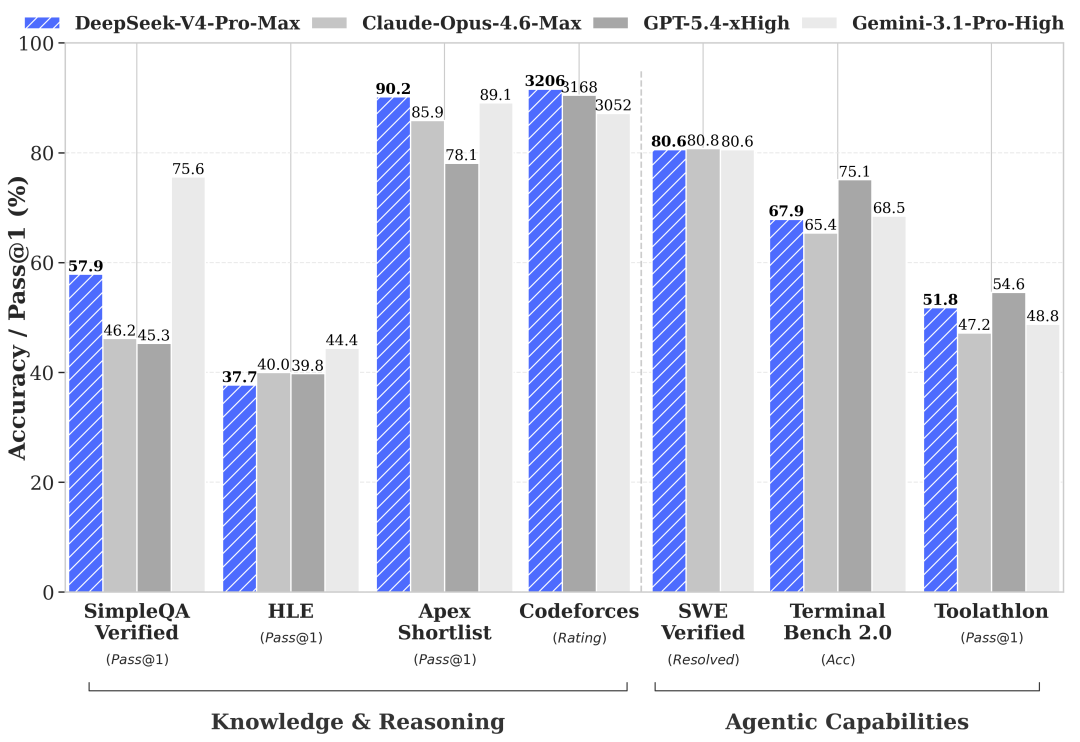
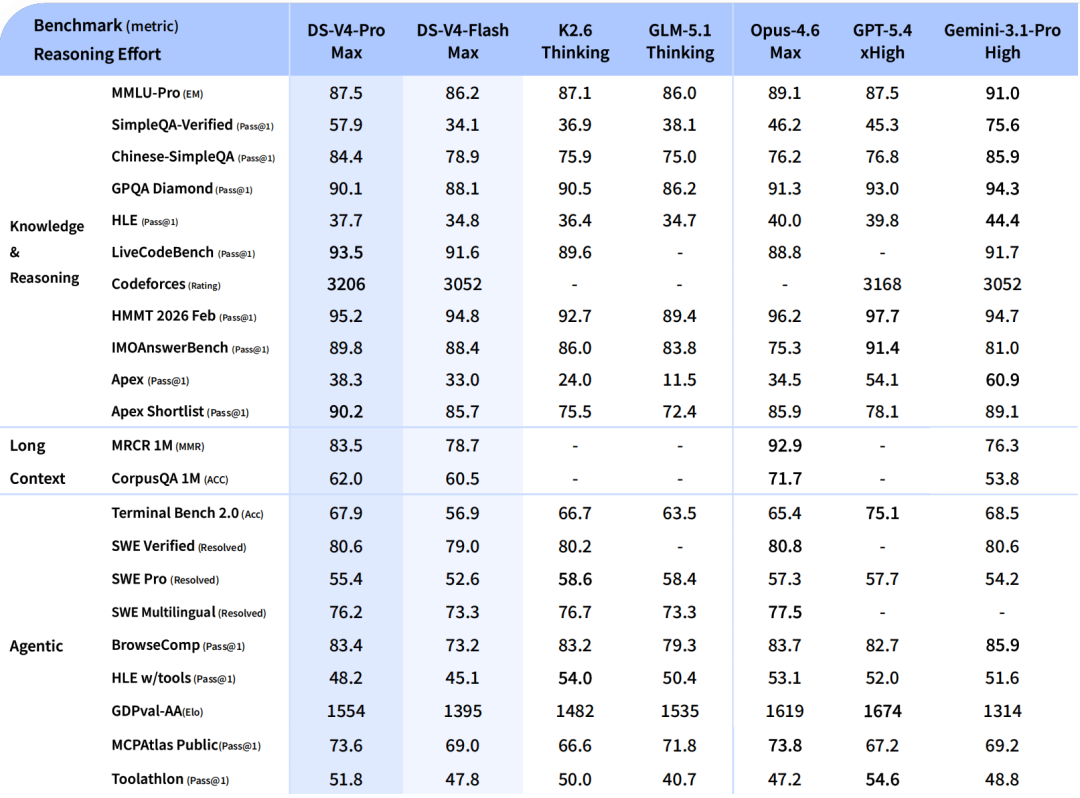
This model's scores
- MMLU90.1%
- MMLU-Pro73.5%
- HumanEval76.8%
- GSM8K92.6%
- LongBench-V251.5%
Scores on a 0–100 scale (25-point gridlines); higher is better. Each benchmark links to its published source.
Pricing
| Input | $0.435 / 1M tokens |
|---|---|
| Cached input | $0.003625 / 1M tokens |
| Output | $0.87 / 1M tokens |
Strengths
- Open MIT-licensed weights at frontier scale (1.6T parameters), free for commercial use and local deployment
- Native one-million-token context window with efficient hybrid attention
- Selectable reasoning effort (Non-think / Think High / Think Max) to trade latency for depth
- Strong knowledge and coding benchmark results among open models
- Very low API pricing relative to capability, with aggressive cache-hit discounts
Best for
- Long-document and large-codebase analysis that needs the full 1M-token window
- Agentic and coding workflows that benefit from high-effort reasoning modes
- Self-hosted / on-prem deployment where open MIT weights are a requirement
- Cost-sensitive high-volume inference via the DeepSeek API
How to access
| Provider | Model ID |
|---|---|
| DeepSeek Platform ↗ | deepseek-v4-pro |
DeepSeek V4 — every version
The full lineage of the DeepSeek V4 line, newest first. Every version has its own page — click any to compare specs, benchmarks and pricing.
| Version | Released | Context | License |
|---|---|---|---|
| DeepSeek-V4-Procurrent | 2026-04-24 | 1M | MIT |
| DeepSeek-V4-Flash | 2026-04-24 | — | MIT |
FAQ
Is DeepSeek-V4-Pro open source?
Yes. The model weights are published on Hugging Face under the MIT License, one of the most permissive open licenses. That means you can download, run, fine-tune, and use DeepSeek-V4-Pro commercially, including for self-hosted and on-premise deployment, without paying DeepSeek. It can be run locally with tools such as Ollama, vLLM, or llama.cpp.
How big is DeepSeek-V4-Pro and how much context does it handle?
DeepSeek-V4-Pro is a Mixture-of-Experts model with 1.6 trillion total parameters, of which 49 billion are activated per token. It supports a context length of one million tokens, which DeepSeek now treats as the default across its official services, making it suitable for very long documents and large codebases.
What are the reasoning modes in DeepSeek-V4-Pro?
The model offers three reasoning-effort settings: Non-think for fast direct answers, Think High for deliberate step-by-step analysis, and Think Max for maximum reasoning depth. The highest setting, sometimes called V4-Pro-Max, is positioned as DeepSeek's strongest configuration for hard knowledge and coding tasks.
How much does the DeepSeek-V4-Pro API cost?
Per DeepSeek's official pricing page, DeepSeek-V4-Pro costs $0.435 per 1M input tokens on a cache miss and $0.87 per 1M output tokens. Cache hits drop the input price dramatically to about $0.003625 per 1M tokens, which makes repeated-context workloads especially cheap.